[译]贝叶斯n-gram合奏"垃圾邮件"分类器
By robot-v1.0
本文链接 https://www.kyfws.com/ai/bayes-n-gram-ensemble-spam-classifier-zh/
版权声明 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
- 9 分钟阅读 - 4225 个词 阅读量 0贝叶斯n-gram合奏"垃圾邮件"分类器(译文)
原文地址:https://www.codeproject.com/Articles/1233120/Bayes-n-gram-Ensemble-Spam-Classifier
原文作者:ddrogahn
译文由本站 robot-v1.0 翻译
前言
A resilient text classifier using word and character n-grams, and Bayes theorem statistical analysis
使用单词和字符n-gram和贝叶斯定理统计分析的弹性文本分类器
介绍(Introduction)
没有人喜欢垃圾邮件-机器如何自动标记垃圾邮件?(No one like spam messages – how can spam automatically be flagged by a machine?)
如果其中没有太多垃圾邮件,则是垃圾邮件吗?(Is a message spam if it doesn’t have that much spam in it?) 垃圾邮件中有多少个垃圾邮件词需要包含垃圾邮件,成为垃圾邮件,被归类为垃圾邮件?(How many spam words does a spam message need to have spam, to be spam, spam classified as spammity spam?)
文本分类可能很困难,因为人们使用各种语言进行交流,使用语,犯拼写错误,并且垃圾邮件发送者不断更新其方法.(Text classification can be difficult because humans communicate using various languages, use slang, make spelling mistakes, and spammers continually update their methods.)
背景(Background)
文字分类方法(Text Classification Methods)
-
关键字和短语:“获胜者”,“免费”,“视线”,“加倍您”,“新规则”(Keywords & Phrases: “winner”, “free”, “as seen on”, “double your”, “new rule”)
- 不统计,仅搜索文本;但是垃圾邮件发送者有一些您不会相信的技巧!(not statistical, just searching for text; but spammers have tricks you won’t believe!)
-
字数统计(Word statistics) 英文中最常见的单词是" THE"(其他最重要的单词是:AND I OF A IS OR AT)…(The most frequent word in English is “THE” (other top words are: AND I OF A IS OR AT)…)
- 垃圾邮件发送者可以获得创意错误的单词(Spammers can get creative, misspell words) " m0rtgage"," F R E E"," ca $ h"," /laGr @",外观相似的Unicode字符(“m0rtgage”, “F R E E”, “ca$h”, “/laGr@”, unicode characters that are visually similar)
- 垃圾邮件发送者可以粘贴大部分文本(例如Melville或Poe),以丢弃统计信息.(Spammers can paste in large sections of text (e.g. Melville or Poe) to throw the statistics off.)
- 某些语言不会分隔单词:中文,日语,泰语(Some languages don’t space words: Chinese, Japanese, Thai)
- 一些语言将单词融合在一起:(Some languages fuse words together:) 凝集语言(Agglutinative Language) 德语"Rindfleischetikettierungsüberwachungsaufgabenübertragungsgesetz"(German “Rindfleischetikettierungsüberwachungsaufgabenübertragungsgesetz”)
- 减少用于文本搜索的数据的常用方法是排除"停止"词:(A common method to reduce data for text searching is to exclude “stop” words:) 根据定义,停用词是最常用的词,将其删除可能会丢弃潜在的有用上下文.(Stop words are by definition the most common words, removing them may discard potentially helpful context.)
-
多字统计(ngram/带状疱疹)(Multi Word stastics (n-gram / shingles)) 多个单词为统计信息提供了更多的上下文,但需要更多的训练数据.(Multiple words give the statistics more context, but require more training data.) “你赢了 !“与"胜利者是你”(“you win !” vs “winner is you”)
- 仍然容易拼错(still susceptible to misspellings)
- 不同的单词形式会增加模型的大小(different word forms inflate the model size) 动词形式/名词-动词一致:单/复数,性别,时态,形式,主语/宾语…(verb forms / noun-verb agreement: single/plural, gender, tense, formality, subject/target…)
-
多字+字符统计信息«-这就是本文要测试的内容(Multi word+character statistics «– this is what this article will be testing)
-
+用于上下文的多词(+ multi-words for context)
-
+退回较少的单词,以获取未经训练的短语(+ fallback to fewer words for untrained phrases)
-
+回退到未经训练的单词的字符(+ fallback to characters for untrained words)
-
+可以轻松地编辑模型,并快速重新运行它(+ can easily edit the model, and quickly rerun it)
-
-大型号(- large model size)
-
维基百科大小示例:(Wikipedia size example:) 约10种语言,每种语言减少为约300k n-gram(每种n-gram类型为50k)(~10 languages, reduce to ~300k n-grams (50k each n-gram type) for each language) 千兆字节以下载和提取(gigabytes to download and extract) 在多核上花费几个小时,以将一种语言的文本减少为词频数据(several hours on a multi-core to reduce one language text to word frequency data) 和〜1GB RAM来加载精简模型(and ~1GB RAM to load the reduced model) 可以有效地识别几个单词的语言片段(例如,书名或剧本的名称)(Can effectively identify a language fragment of a few words (e.g., name of a book or play))
-
-运行:大型模型的运行速度不是超级快,但优化后的运行速度却不是非常慢…(- Running: not super fast with large models, but not terribly slow when optimized…) 可调整:预处理,克大小/权重,模型大小,多线程(* Tweakable: pre-processing, gram sizes/weights, model size, multithreading*)
-
人工神经网络:(Artificial Neural Networks:) 快速发展的领域;很多很多的选择(* a rapidly growing field; many, many options*)
- 很难甚至不可能追溯为什么某些东西起作用或不起作用(can be difficult to impossible to trace back why something does or does not work)
- 大规模培训可能很耗时,并且需要大量的硬件资源(training at scale can be time consuming and require large hardware resources)
- 编辑模型通常需要重新培训(editing the model typically requires retraining)
-
概率统计(Probability & Statistics)
贝叶斯规则:P(A | B)=P(B | A)* P(A)/P(B)(*Bayes Rule: P(A|B) = P(B|A) * P(A) / P(B)*)
A的概率(发生B时)=B的概率(发生A时)* A的概率(随时)/B的概率(随时)(*The probability of A (when B has occurred) = the probability of B (when A has occurred) * probability of A (anytime) / probability of B (anytime)*)
应用于垃圾邮件:(Applied to spam:) P(垃圾邮件|单词)=P(文字|垃圾邮件)* P(垃圾邮件)/(P(文字|垃圾邮件)+ P(文字|火腿))(*P(spam | word) = P( word | spam) * P(spam) / ( P(word | spam) + P(word | ham) )*)
连锁规则:P(A&B)=P(A)* P(B)(*Chain Rule: P(A & B) = P(A) * P(B)*)
优化:乘数比加数慢,并且小数可能会下溢(Optimization: multiplying numbers is slower than adding, and tiny numbers can underflow) 因此,使用对数:(So use logarithms:) 对数(A * B)=对数(A)+对数(B)(Log(A * B) = Log(A) + Log(B)) 对数(A/B)=对数(A)-对数(B)(Log(A / B) = Log(A) - Log(B))
模糊逻辑:现实世界中的状态可能不像我们对它们进行建模那样二进制(Fuzzy Logic: real world states may not be as binary as we model them)
如果未知的未知数大于假定的未知数,或者涉及隐藏的变量…(If the unknown unknowns turn out to be bigger than assumed, or hidden variables are involved…) 那么假设一件事排除另一件事可能是不安全的:P(A)=1-P(B)(Then it may not be safe to assume one thing excludes another: P(A) = 1 - P(B))
邮件(或网页)可能同时包含垃圾邮件和非垃圾邮件,或者是外语,模型无法根据该外语做出明智的决定.(A message (or webpage) could contain both spam and non-spam, or be in a foreign language on which the model cannot make an informed decision.)
文字预处理(Text Pre-Processing):标准化空间并以可重复的方式处理符号,数字等非常重要.(: It is extremely important to normalize spaces, and deal with symbols, numbers, etc. in a repeatable way.)
使用代码(Using the Code)
var bec = new BayesEnsembleClassifier();
bec.Train(files);
bec.TrainPost();
bec.Test(filename_test);
//-Run the test data with increasingly misspelled words
for (int r = 5; r <= 95; r += 5) {
bec.TestRandom(filename_test, randomness);
}
训练步骤对文本进行标记,删除HTML并在1-3个单词的n-gram瓦片和垃圾邮件和火腿的3,5,7个字符上构建频率表.字符克可以交叉单词. n克的重量和大小/长度是可定制的.(The Train step tokenizes the text, removes HTML & builds frequency tables on n-gram shingles of 1-3 words, and 3,5,7 characters for both spam and ham. Character grams can cross words. Weights and sizes/lengths of n-grams are customizable.)
类别是动态的(但有效的存储需要更复杂的数据结构以减小大小并避免周转).(Categories are dynamic (but an efficient storage needs a more complicated data structure to reduce size and avoid turnover).)
例如:(For example:)
- 前两个单词的火腿条目是:".the”," the."," the the"," and the" …(Top 2-word ham entries are: “. the”, “the .”, “the the”, “and the”…)
- 垃圾邮件的前2个词条:“和”,“至”,“他的”,“他”.(Top 2 word spam entries: “and .”, “to .”, “his .”, “he .")
- 垃圾邮件的主要文字是” th"," the"," and"," his"," childe"(Top spam char-grams are " th", “the”, " and “, " his “, " childe”)
- 顶级火腿字符为” th"," the"," ing"," the"," the"," evermor"(Top ham char-grams are " th", “the”, “ing”, " the “, " and “, " that”, “evermor”) 发布(Post):过滤掉稀有的n-gram并预先计算对数概率(: Filters out rare n-grams and pre-calculates Log probabilities)
测试(Test):评估测试文件中的行并显示TruePositive/TrueNegative/FalseNegative/FalsePositive和F分数(: Evaluates lines in the test file and displays TruePositive/TrueNegative/FalseNegative/FalsePositive & F-Score)
TestRandom 在处理前对测试文本进行更改(它会随机增加所选字符)并显示分数.(makes changes to the test text before processing (it increments randomly selected characters), and displays scores.)
兴趣点(Points of Interest)
内存使用情况:(提供的训练集)(Memory Usage: (provided training set))
装载高峰135MB(Loading Peak 135MB) 加载后47MB(After Loading 47MB)
定时(Timing)
加载/训练6809ms(但优化的用法将节省减少和压缩的训练数据)(Load/Train 6809ms (but optimized usage would save the reduced & compacted training data)) 评估时间250毫秒(提供的测试集:100条消息,35583字)(Eval 250ms (provided test set: 100 messages, 35583 words))
弹性(Resilience)
因为模型包含字符克,所以当更改文本中最多50%的字符时,它可以成功地对文本进行分类. (很容易辨认出各个单词)(Because the model includes character grams, it can successfully categorize text when upto 50% of the characters in the text are changed. (long after the individual words are humanly recognizable))
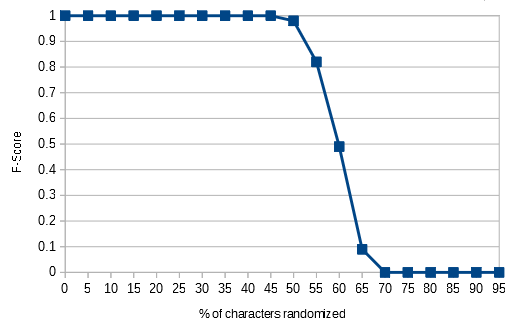
% Chars Changed, F-Score, Test Text (partial first line)
0% 1.00 bust by this expressing at stepped and . my my dreary a and . shaven we spoken
5% 1.00 bust by this eypressinh at stepped bnd . my my dreary a and . shaven we spoken
10% 1.00 bust by this eypressinh at suepped bnd . my my dreary a and . siaven we spoken
15% 1.00 bust by this eypressinh at suepped bnd . ny my ereary a and . siaven we sppkeo
20% 1.00 bust by this eypressinh at sufpped bnd . ny my ereary a and . siawen we sppkeo
25% 1.00 busu by this eypressinh at sufpped bnd . ny my eseary a and . siawen we sppkeo
30% 1.00 busu by uiis eypressinh at sufpqed bnd . nz my eseary a and . siawen we sppkeo
35% 1.00 busu by uiis eypretsinh at sufpqed bne . nz mz eseary a and . siawen we sppkeo
40% 1.00 busu by uiis eypretsinh at sufpqed boe . nz mz eseary a and . siawen we sppkeo
45% 1.00 busu bz uiis eypretsinh at sufpqed boe . nz mz esfary a and . siawen we sppkeo
50% 0.98 busu bz uijs eypretsinh at sufqqed boe . nz mz esfarz a and . siawen wf sppkeo
55% 0.82 busu bz uijs eypretsinh bt tufqqed boe . nz mz esfarz a and . siawen wf sppkeo
60% 0.49 butu bz uijs eypretsinh bt tufqqed boe . nz mz esfarz a and . siawen wf sppkeo
65% 0.09 butu bz uijt eypretsinh bt tufqqee boe . nz mz esfasz a and . siawfn wf sppkeo
70% 0.00 butu bz uijt eyprftsinh bt tufqqee boe . nz mz esfasz a ane . siawfn wf sppkeo
75% 0.00 butu bz uijt eyprftsinh bt tufqqee boe . nz mz esfbsz a bne . siawfn wf tpplfo
80% 0.00 bvtu bz uijt eyprftsinh bt tufqqee boe . nz nz esfbsz a bne . siawfn wf tpplfo
85% 0.00 cvtu bz uijt eyprfttjnh bt tufqqee boe . nz nz esfbsz a bne . sibwfo wf tqplfo
90% 0.00 cvtu bz uijt eyqrfttjnh bt tufqqee boe . nz nz esfbsz b boe . tibwfo wf tqplfo
95% 0.00 cvtu cz uijt eyqrfttjnh bu tufqqee boe . nz nz esfbsz b boe . tibwfo wf tqplfo
笔记(Notes)
决赛(The final) PredictLine() 有点复杂…(is a bit complicated…)
写出循环以进行多路分组和聚合需要大量代码.(Writing out loops to a multi-way grouping and aggregation takes a lot of code.)
如果遗漏了某些内容,几乎不可能调试LINQ查询.(And LINQ queries are nearly impossible to debug if something was left out.)
不知道哪个更糟.(Not sure which is worse.)
历史(History)
- 2018-03-04:初始帖子(2018-03-04: Initial post)
许可
本文以及所有相关的源代码和文件均已获得The Code Project Open License (CPOL)的许可。
C# .NET VS2013 Dev 新闻 翻译