[译]使用MS CNTK的Bezier曲线机器学习
By robot-v1.0
本文链接 https://www.kyfws.com/ai/bezier-curve-machine-learning-with-ms-cntk-zh/
版权声明 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
- 16 分钟阅读 - 7707 个词 阅读量 0使用MS CNTK的Bezier曲线机器学习(译文)
原文地址:https://www.codeproject.com/Articles/1258542/Bezier-Curve-Machine-Learning-with-MS-CNTK
原文作者:asiwel
译文由本站 robot-v1.0 翻译
前言
Bezier Curve Classification Training and Validation Models using CNTK and ALGLIB
使用CNTK和ALGLIB的贝塞尔曲线分类训练和验证模型
- 下载源文件439.6 KB(Download source files - 439.6 KB) 访问第1部分:(Visit Part 1:) 数据可视化和贝塞尔曲线(Data Visualizations and Bezier-Curves)
访问第2部分:(Visit Part 2:) 贝塞尔曲线机器学习示范(Bezier Curve Machine Learning Demonstration)
介绍(Introduction)
本文是系列文章的第3部分.第1部分演示了使用Bezier曲线来平滑大数据点波动并提高图案展开的可见性.第2部分重点介绍使用ALGLIB机器学习算法训练网络模型,以识别学生学习成绩的贝塞尔曲线轨迹中反映的模式和趋势.在这里,我们将使用相同的WinForm用户界面,并将演示代码扩展为使用批处理和微型批处理方法检查几种常见的MS CNTK数据格式以及CNTK分类和评估模型.(This article is Part 3 in a series. Part 1 demonstrated using Bezier curves to smooth large data point fluctuations and improve the visibility of the patterns unfolding. Part 2 focused on using ALGLIB machine learning algorithms to train network models to recognize patterns and trends reflected in Bezier curve trajectories of student academic performance. Here, we will use the same WinForm user interface and extend the demonstration code to examine several common MS CNTK data formats and CNTK classification and evaluation models using batch and mini-batch methods.)
演示代码和UI反映了用于二进制或多标签分类任务的模型构建,训练,验证和测试的著名方法.我们对数据集的随机选择部分进行训练,并对其余部分进行验证/测试.(The demonstration code and UI reflect well-known approaches to model building, training, validation, and testing for binary or multi-labelled classification tasks. We train on a randomly selected portion of the dataset and validate/test the trained model on the remaining portion.)
在模型方面,有很多选择,比较结果总是好的.这就是为什么我决定在演示中保留ALGLIB神经网络和决策林模块以及新的CTNK模块的原因.这意味着要运行代码,您将需要提供并包括(In terms of models, there are many choices and it is always good to compare results. Which is why I decided to leave the ALGLIB neural network and decision forest modules in the demonstration, along with new CTNK modules. This means that to run the code, you will need to have available and include the)**ALGLIB314.dll(ALGLIB314.dll)**库以及C#2.5.1 NuGet程序包的CNTK作为项目引用.本系列的第2部分介绍了如何获取ALGLIB免费版源,并详细介绍了在Visual Studio中构建该DLL库的步骤.(library as well as the CNTK for C# 2.5.1 NuGet package as project references. Part 2 of this series explained how to obtain the ALGLIB free edition source and presented a detailed walk-through the steps for building that DLL library in Visual Studio.)
背景(Background)
本演示以Microsoft提供的C#CTNK为特色,它是C#程序员的强大而动态的工具,它提供了许多高级的机器学习方法.但是,CNTK向用户提供了相当陡峭的学习曲线,并且文档还没有达到应有的水平.最近,许多特定问题开始在诸如StackOverFlow之类的资源上得到解答,并且在GitHub上提供了更详细的代码示例.特别是,一个CodeProject的贡献者Bahrudin Jrnjica从一开始就发表了一系列我认为最有帮助的优秀CNTK文章.(This demonstration features CTNK for C# from Microsoft, a powerful, dynamic tool for C# programmers that offers many advanced machine learning methods. However, CNTK presents users with a rather steep learning curve and documentation is not yet as good as it should be. More recently, many specific questions are beginning to have answers on sources like StackOverFlow and more detailed code examples are being provided on GitHub. In particular, one CodeProject contributor, Bahrudin Jrnjica, has published a whole series of excellent CNTK articles that I have found most helpful, beginning) 这里(here) IRIS数据集示例,并在他的技术博客文章中进一步记录了(with IRIS dataset examples and further documented in his technical blog posts at) http://bhrnjica.net(http://bhrnjica.net) ,.其他参考资料包括Microsoft源文档,例如(,. Other references include Microsoft source documentation such as) 将CNTK与C#/.NET API结合使用(Using CNTK with C#/.NET API) .(.)
数据特征(Data Characteristics)
该数据可视化系列的先前文章标题为(The previous articles in this data visualization series, entitled) 数据可视化和贝塞尔曲线(Data Visualizations And Bezier Curves) 和(and) 贝塞尔曲线机器学习示范(Bezier Curve Machine Learning Demonstration) 关于使用贝塞尔曲线建模数据.作为示例,我们研究了使用Bezier曲线建模的6至12年级学生在一段时间内的学习成绩.我们讨论了可以训练以识别各种模式的机器学习分类模型,例如纵向轨迹可以识别表现良好或有危险的学生.(were about modeling data with Bezier curves. As examples, we looked at student academic performance over time from grades 6 through 12, modelled using Bezier curves. We discussed machine learning classification models that could be trained to recognize various patterns, such as longitudinal trajectories that identify students who are appear to be doing well or likely to be at-risk.)
在这里,我们将使用相同的小型模拟样本((Here, we will use the same small simulated sample () N=500 学业成绩平均成绩()() of school marking period grade point average () MPgpa )第2部分中使用的学生在核心课程中的表现历史.() student performance histories in core coursework as was used in Part 2.) MPgpa s的范围在0.00到4.00之间. (请查看以前的文章,以获取有关数据源的完整描述.)(s are bounded from 0.00 to 4.00 on the grading scale. (Please review the previous articles for a fuller description of the data source.))
我们的小型演示数据集是通过随机选择预先分类的学生历史记录而建立的,同时确保了代表每个状态组的一组演示数据的平衡.每条曲线都标记为(Our small demonstration data set was built by selecting pre-classified student histories at random, while ensuring a balanced set of demo data representing each status group. Each curve was labeled either as)
- 在课程时间表上显示相对成功的学术历史,直到状态估计点(中学毕业9.0)为止(indicating a relatively successful academic history up to the status estimation point (9.0, end of middle school) on the curriculum timeline)
- 由于MPgpa模式下降到评分等级上的2.0以下,可能会带来风险(as possibly at-risk due to a falling MPgpa pattern below 2.0 on the grading scale)
- 仍处于危险之中,但MPgpa呈上升趋势,接近或略高于2.0(still at-risk but exhibiting a rising MPgpa pattern toward or slightly above 2.0)
- 严重面临学术失败的风险,这种趋势趋向于低于1.0(seriously at risk of academic failure, a pattern trending below 1.0)
与CNTK合作(Working with CNTK)
MS CNTK for C#提供了用于在CPU或GPU上运行的多线程代码.在这里,我们将CPU用作CPUOnly版本的默认设备. C#的MS CNTK需要x64编译.在构建演示项目之前,您应检查(MS CNTK for C# provides multi-threaded code for running on CPUs or GPUs. Here, we use the CPU as the default device for the CPUOnly version. MS CNTK for C# requires x64 compilation. Before building the demonstration project, you should check the)配置管理器(Configuration Manager)确保(to insure that)**除错(Debug)**和(and)**发布(Release)**解决方案中所有项目的内部版本都设置为x64. (“任何CPU"均不起作用.)(builds for all projects in the solution are set to x64. (“Any CPU” will not work.))
CNTK流程需要各种格式的数据,并提供了用于根据需要重塑数据的工具.一种特殊格式是用于小批量处理的|特征…|标签…(以热向量样式).对于我们的数据,它看起来像这样:(CNTK processes require data in various formats and provide tools for re-shaping that data as needed. One particular format is the |features … |label … (in hot vector style) used for minibatch processing. For our data, it looks like this:)
|features 2.383 2.624888 2.740712 2.794445 2.814961 2.816335
2.807138 2.793529 2.779638 2.767359 2.756607 2.74636 2.736153
2.727306 2.723097 2.727629 2.744186 2.77428 2.817792 2.873763
2.941018 3.018575 3.105723 3.202 |label 1 0 0 0
|features 1.134 1.090346 1.049686 1.012011 0.9773244 0.9455433
0.9165261 0.8900167 0.8656217 0.8427486 0.8205234 0.7977431 0.7727986
0.7436811 0.7081886 0.6644097 0.611671 0.5517164 0.4896953 0.4342301
0.3965976 0.3895209 0.4262405 0.52 |label 0 0 1 0
…
另一个重要的CNTK格式只是一维数据向量.一种用于功能,另一种用于标签;一对用于训练数据集,另一对用于验证/测试数据集.在这个新的演示中,(Another important CNTK format is simply a 1D data vector; one for features and one for labels; one pair for the training dataset and another pair for the validation/test dataset. In this new demo, the) DataReader 对象已被修改以提供内存(object has been modified to provide in-memory) dataset 以各种格式显示.(s in these various formats.)
使用代码(Using the Code)
在这个”(In this “) BezierCurveMachineLearningDemoCNTK “使用Visual Studio 2017和.NET 4.7用C#编写的项目”,我们首先读取数据文件,构造学生历史记录,并随机整理记录.从每个历史记录中提取一个子历史记录.与每个子历史记录相关联的是预分类的状态值.接下来,拟合贝塞尔曲线以对每个学生子历史进行建模.通过从起点到终点(包括端点)以相等的时间间隔提取24个MPgpa值的列表,可以对平滑的Bezier曲线本身进行建模.这些成为标签和用于训练和验证各种机器学习分类模型的功能.(” project written in C# using Visual Studio 2017 and .NET 4.7, we first read a data file, construct student histories, and shuffle records randomly. From each history, a sub-history is extracted. Associated with each sub-history is a pre-classified status value. Next, a Bezier curve is fitted to model each student sub-history. That smooth Bezier curve itself is modeled by extracting a list of 24 MPgpa values at equal time intervals from the starting point to ending point, inclusive. These become the label and the features use to train and validate various machine learning classification models.)
下载项目并在Visual Studio中打开解决方案文件.在解决方案资源管理器中,右键单击项目引用文件夹,然后删除对该引用的任何现有引用.(Download the project and open the solution file in Visual Studio. In the Solution Explorer, right-click on the project references folder and delete any existing reference to the)**ALGLIB314.dll(ALGLIB314.dll)**图书馆.然后使用(library. Then use the)添加参考(Add References)查找和添加发行版本的选项(option to locate and add the release version of)**ALGLIB214.dll(ALGLIB214.dll)**库(在本系列的第2部分中创建). C#的MS CNTK需要x64编译.如上所述,您应该检查(library (that you created in Part 2 of this series) to the project. MS CNTK for C# requires x64 compilation. As mentioned above, you should check the)配置管理器(Configuration Manager)确保(to insure that)**除错(Debug)**和(and)**发布(Release)**解决方案中所有项目的内部版本都设置为x64.(builds for all projects in the solution are set to x64.)
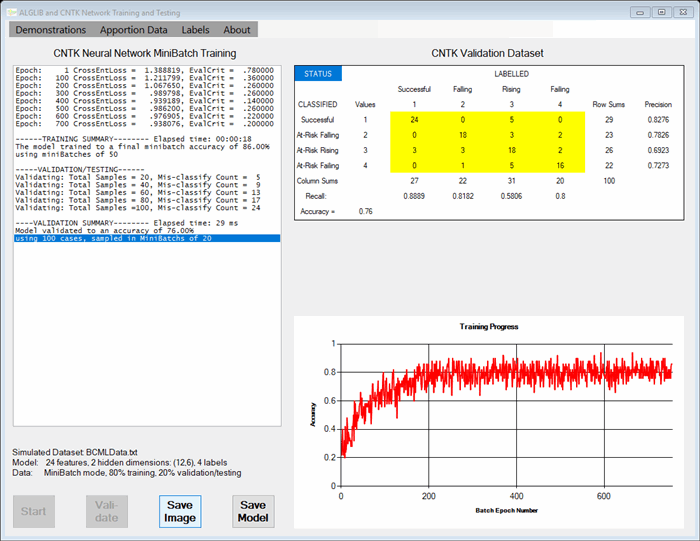
然后点击(Then click)开始(Start)生成并运行该应用程序.该解决方案需要几个软件包(对于C#2.5.1和(to build and run the application. The solution requires several packages (CNTK for C# 2.5.1 and) System.ValueTuple 4.3.1)应自动下载并还原. WinForm应该以(4.3.1) which should download and restore automatically. A WinForm should open with a) listbox , 一种(, a) chart , 一种(, a) datagridview ,以及一些按钮.其他细节将在本系列的第2部分中进行解释.对于此演示,提供了其他菜单选项来选择具有批处理或小批处理数据处理的CNTK模型训练.(, and a few buttons. Other details are explained in Part 2 of this series. For this demonstration, additional menu options are provided to select CNTK model training with batch or mini-batch data processing.)
兴趣点(Points of Interest)
这里的理念是,大多数从CodeProject"演示"中获得的好处应该来自对代码的检查.我们当然鼓励读者这样做(任何改进的建议将不胜感激).如果不是大多数的话,大多数代码对于构建表单和演示用户界面都是不明显的.但是,最重要的方法是用于创建和操作(The philosophy here is that most of the benefit to be derived from a CodeProject “demonstration,” is supposed to come from examination of the code. Readers are certainly encouraged to do that (any suggestions for improvements will be appreciated). Much if not most of the code is unremarkable, for building the form and the demo User Interface. However, the most important methods are those for creating and manipulating the) dataset (如上所述)以及调用CNTK实现的实际机器学习过程的程序.((discussed above) and those that call the actual machine learning processes implemented by CNTK.)
训练模式(TRAINING MODELS):此演示说明了使用!features…!label…格式(将数据保存为磁盘数据文件)进行CNTK迷你批处理的培训以及使用1D格式(将数据存储在内存中)的批处理培训.例如,这是(: This demonstration illustrates CNTK mini-batch training using the !features …!label … format (with the data saved as a disk datafile) and batch training using the 1D format (with data stored in-memory). For instance, this is the) CNTKTraining 演示中用于批处理的神经网络代码块,该块定义并实现了(24:12:6:4)神经网络,该神经网络已被证明足以对代表学术表现的贝塞尔曲线进行分类. (此类中的许多代码已改编自以下示例提供的示例源代码:(neural net code block for batch processing in the demo that defines and implements a (24:12:6:4) neural network that has been shown to be adequate for classifying Bezier curves representing academic performance. (Much of the code in this class has been adapted from example source code provided by) 巴鲁丁(Bahrudin Jrnjica)(Bahrudin Jrnjica) 在上述参考文献中.)(at references noted above.))
class CNTKTraining
{
public static CNTK.Function CNTK_ffnn_model;
private static CNTK.Trainer _trainer;
private static double _accuracy;
public static void RunExample3() // CNTK Neural Network demo using Batch mode
{
// Network definition
int inputDim = Form1.rdr.NofFeatures;
int numOutputClasses = Form1.rdr.NofLabels;
int[] hiddenLayerDim = new int[2] { 12, 6 }; // The Bezier Curve NN model used in this demo
int numHiddenLayers = hiddenLayerDim.Count();
uint batchSize = (uint)Form1.rdr.NofTrainingCases; // use all data for each batch
ModelInfoSummary_B(hiddenLayerDim); // sends output to the UI
// Define input and output variables (features and label)
var xValues = Value.CreateBatch<float>(new NDShape(1, inputDim),
Form1.rdr.GetCNTK_Train_1DFeatures, Form1.device);
var yValues = Value.CreateBatch<float>(new NDShape(1, numOutputClasses),
Form1.rdr.GetCNTK_Train_1DLabels, Form1.device);
var features = Variable.InputVariable(new NDShape(1, inputDim), DataType.Float);
var labels = Variable.InputVariable(new NDShape(1, numOutputClasses), DataType.Float);
// Combine variables and data into a Dictionary for the training
Dictionary<Variable, Value> dic = new Dictionary<Variable, Value>
{
{ features, xValues },
{ labels, yValues }
};
//Build simple Feed Forward Neural Network model
CNTK_ffnn_model = CreateFFNN(features, numHiddenLayers, hiddenLayerDim,
numOutputClasses, ACTIVATION.Tanh, "DemoData", Form1.device);
// Loss and error functions definition
var trainingLoss = CNTKLib.CrossEntropyWithSoftmax(new Variable(CNTK_ffnn_model),
labels, "lossFunction");
var classError = CNTKLib.ClassificationError( new Variable(CNTK_ffnn_model),
labels, "classificationError");
// LEARNING RATE
PairSizeTDouble p1 = new PairSizeTDouble( 1, 0.05);
PairSizeTDouble p2 = new PairSizeTDouble( 2, 0.03);
PairSizeTDouble p3 = new PairSizeTDouble( 2, 0.02);
var vlr = new VectorPairSizeTDouble() { p1, p2, p3};
var learningRatePerEpoch =
new CNTK.TrainingParameterScheduleDouble(vlr, batchSize); // variable
// learning schedule
//var learningRatePerEpoch = new TrainingParameterScheduleDouble(0.02); // fixed
// learning schedule
//MOMENTUM
PairSizeTDouble m1 = new PairSizeTDouble(1, 0.005);
PairSizeTDouble m2 = new PairSizeTDouble(2, 0.001);
PairSizeTDouble m3 = new PairSizeTDouble(2, 0.0005);
var vm = new VectorPairSizeTDouble() { m1, m2, m3 };
var momentumSchedulePerSample =
new CNTK.TrainingParameterScheduleDouble(vm, (uint)Form1.rdr.NofTrainingCases);// variable
// schedule
//var momentumSchedulePerSample = CNTKLib.MomentumAsTimeConstantSchedule(256); // time constant
// schedule
//var momentumSchedulePerSample = new TrainingParameterScheduleDouble(.001); // fixed schedule
//L1 and L2 REGULARIZATION
//var addParam = new AdditionalLearningOptions()
//{
// l1RegularizationWeight = 0.01,
// l2RegularizationWeight = 0.05
//};
var vp = new ParameterVector();
foreach (Parameter p in CNTK_ffnn_model.Parameters()) vp.Add(p);
// DEFINE LEARNERS FOR THE NN MODEL
//var myLearner = Learner.SGDLearner(CNTK_ffnn_model.Parameters(), learningRatePerEpoch);
var myLearner = Learner.MomentumSGDLearner(CNTK_ffnn_model.Parameters(),
learningRatePerEpoch, momentumSchedulePerSample, true);
//var myLearner = CNTK.CNTKLib.AdamLearner(vp,
// learningRatePerEpoch, momentumSchedulePerSample, true);
// DEFINE A TRAINER
_trainer = Trainer.CreateTrainer(CNTK_ffnn_model, trainingLoss,
classError, new Learner[] { myLearner });
// IF WE WANTED TO CONTINUE TRAINING A PARTICULAR MODEL
//_trainer.RestoreFromCheckpoint(ApplicationPath + "CNTK_Trained_Network(CKP)");
//Preparation for the iterative learning process
int epoch = 1;
int epochmax = 4000;
int reportcycle = 200;
double prevCE = 0.0;
double currCE = 0.0;
double losscritierion = 0.00001; // About as good as we are going to get
Dictionary<int, double> traindic = new Dictionary<int, double>();
while (epoch <= epochmax)
{
_trainer.TrainMinibatch(dic, true, Form1.device); // whole batch is used each epoch
// print progress
currCE = _trainer.PreviousMinibatchLossAverage();
if (Math.Abs(prevCE - currCE) < losscritierion) break; // stop interations
prevCE = currCE;
_accuracy = 1.0 - _trainer.PreviousMinibatchEvaluationAverage();
traindic.Add(epoch, _accuracy);
PrintTrainingProgress(_trainer, epoch, reportcycle); // UI ouput info
Charts.ChartAddaPoint(epoch, _accuracy);
epoch++;
}
TrainingSummary_B(); // UI output info
…
}
… // a bunch of private support methods for this RunExample
}
如您所见,首先是进一步的数据处理和重塑.大多数时候,这也将涉及标准化步骤.但是,在我们的情况下,贝塞尔曲线特征数据已经限制在0.0到4.0 MPgpa值之间,并且该模型似乎可以很好地处理该范围内的数据.然后定义一个网络,在这种情况下,由24个节点的输入层(用于描述Bezier曲线的24个点),两个隐藏层–第一个具有12个节点,第二个具有6个节点,以及一个具有4个或2个节点的输出层用于三级或二元分类.接下来,可以设置各种参数(例如,学习率和/或动量时间表).这些用于定义学习者(例如,内置(As you can see, first there is further data processing and reshaping. Most of the time, this would also involve a normalization step. However, in our case, the Bezier curve feature data is already bounded 0.0-to-4.0 MPgpa values and the models seem to work fine with data within that range. Then a network is defined, in this case by a 24 node input layer for the 24 points describing a Bezier curve, two hidden layers – the first with 12 nodes and the second with 6 nodes, and an output layer with 4 or 2 nodes for tertiary or binary classification. Next, various parameters (e.g., learning rate and/or momentum schedules) can be set. These are used to define a learner (e.g., either the built-in) SGDLearner 要么(or) MomentumSGDLearner 或者,例如,(or, as another example, the) AdamLearner **提供在(provided in) CNTK.CNTKLib .给定学习者,将创建一个培训者.每个时代,批次(. Given the learner, a trainer is created. Each epoch, the batch) dataset 呈现给培训师,并产生"逐步"中间输出.这是用来更新(is presented to the trainer and “step-wise” intermediate output is produced. This is used here to update the) listbox 信息表和培训进度图可视化.(information table and the Training Progress chart visualization.)
训练完模型后,只需将其保存为磁盘文件,然后将该模型重新加载到用于分类新数据记录的其他程序中,就很简单. CNTK为此提供了功能,例如:(Once the model is trained, it is a simple matter to save it as a disk file and to reload that model into a different program for classifying new data records. CNTK provides functions for this purpose, e.g.:)
public static CNTK.Function CNTK_ffnn_model;
public static CNTK.Trainer _trainer;
…
/// <summary>
/// Write the trained CNTK neural network and checkpoint as files
/// </summary>
/// <param name="pathname"></param>
public static void SaveTrainedCNTKModel(string pathname)
{
CNTK_ffnn_model.Save(pathname); // saves trained model for production or evaluation
_trainer.SaveCheckpoint(pathname + "(CKP)"); // in case we want to continue training the model
}
和:(and:)
/// <summary>
/// Load a saved trained CNTK neural network
/// </summary>
/// <param name="pathname"></param>
public static void LoadTrainedCNTKModel(string networkPathName)
{
if (!File.Exists(networkPathName))
throw new FileNotFoundException("CNTK_NN Classifier file not found.");
CNTK_ffnn_model = Function.Load(networkPathName, Form1.device, ModelFormat.CNTKv2);
}
注意(NOTE):在此演示中,一个有趣的地方是所有数据文件都恰好被复制到或保存到项目的运行时"(: In this demonstration, a point of interest is that all data files happen to be either copied to or saved into the project’s runtime “)申请文件夹(Application folder)"(例如,(” (e.g., the)**x64调试(x64 debug)**要么(or)**发布(release)**夹).(folder).)
验证和测试(VALIDATION AND TESTING):训练完成后,您想将训练后的模型应用于验证测试数据. CNTK模型包含可以提取的定义信息.通常,您会看到与此类似的代码(: Once training is complete, you want to apply the trained model to the validation test data. A CNTK model contains definitional information that can be extracted. Typically, you see code similar to this) EvaluateModel_Batch 例程,它利用内存数据,一维格式样式和CNTK数据重塑.该演示还包括一个更复杂的CNTK(routine, which makes use of in-memory data, the 1D format style, and CNTK data reshaping. The demonstration also includes a more complex CNTK) Evaluate_MiniBatch 方法以及更简单的方法(method as well as a somewhat simpler) MLModel IClassifier 生产运行的对象. (请务必注意,(object for production runs. (It is important to note that) 经过培训的CBTK模型不是线程安全的(trained CBTK models are NOT thread-safe) .但是,那(. However, the) IClassifier object是线程安全的,将在本系列的下一篇文章中进行详细说明.)(object is thread-safe and will be described in detail in the next article in this series.))
class CNTKTesting
{
private static double _accuracy;
/// <summary>/// Evaluates using a trained model and test data
/// </summary>
/// <param name="ffnn_model"></param>
/// <param name="device"></param>
/// <param name="rdr"></param>
public static void EvaluateModel_Batch(Function ffnn_model, bool validationFlag = false)
{
// extract features and labels from the model
var features = (Variable)ffnn_model.Arguments[0];
var labels = ffnn_model.Outputs[0];
// get dimensions
int inputDim = features.Shape.TotalSize;
int numOutputClasses = labels.Shape.TotalSize;
// define input and output variable
Value xValues, yValues;
if (validationFlag == true)
{
xValues = Value.CreateBatch<float>(new NDShape(1, inputDim),
Form1.rdr.GetCNTK_Validate_1DFeatures, Form1.device);
yValues = Value.CreateBatch<float>(new NDShape(1, numOutputClasses),
Form1.rdr.GetCNTK_Validate_1DLabels, Form1.device);
}
else
{
xValues = Value.CreateBatch<float>(new NDShape(1, inputDim),
Form1.rdr.GetCNTK_Train_1DFeatures, Form1.device);
yValues = Value.CreateBatch<float>(new NDShape(1, numOutputClasses),
Form1.rdr.GetCNTK_Train_1DLabels, Form1.device);
}
var inputDataMap = new Dictionary<Variable, Value>() { { features, xValues} };
var expectedDataMap = new Dictionary<Variable, Value>() { { labels, yValues } };
var outputDataMap = new Dictionary<Variable, Value>() { { labels, null } };
var expectedData = expectedDataMap[labels].GetDenseData<float>(labels);
var expectedLabels = expectedData.Select(l => l.IndexOf(l.Max())).ToList();
ffnn_model.Evaluate(inputDataMap, outputDataMap, Form1.device);
var outputData = outputDataMap[labels].GetDenseData<float>(labels); // get
// probabilities
var actualLabels = outputData.Select(l => l.IndexOf(l.Max())).ToList(); // get labels
if (validationFlag == true)
{
int NofMatches = actualLabels.Zip(expectedLabels, (a, b) => a.Equals(b) ? 1 : 0).Sum();
int totalCount = yValues.Data.Shape.Dimensions[2]; // gets NofCases
_accuracy = (double)NofMatches / totalCount;
ValidationSummary_B();
}
// Start by converting the 0-based labels to 1-based labels
List<int> predict = new List<int>();
List<int> status = new List<int>();
for (int k = 0; k < actualLabels.Count; k++)
{
predict.Add(actualLabels[k] + 1);
status.Add(expectedLabels[k] + 1);
}
Support.RunCrosstabs(predict, status);
}
…
}
的(The)**crosstabs.cs(crosstabs.cs)**模块包含以"混淆"矩阵格式显示实际和预测分类结果的方法,(module contains methods to display actual and predicted classification results in a “confusion” matrix format in the) datagridview WinForm中的控件以及各种精度,召回率和准确性统计信息.有兴趣将例程用于自己目的的读者可以参考CodeProject的另一篇文章(control in the WinForm, along with various precision, recall, and accuracy statistics. Readers interested in using that routine for their own purposes are referred to another CodeProject article entitled) 人工智能分类项目的交叉表/混淆矩阵(Crosstabs/Confusion Matrix for AI Classification Projects) 我前一段时间写的(that I wrote some time ago.)
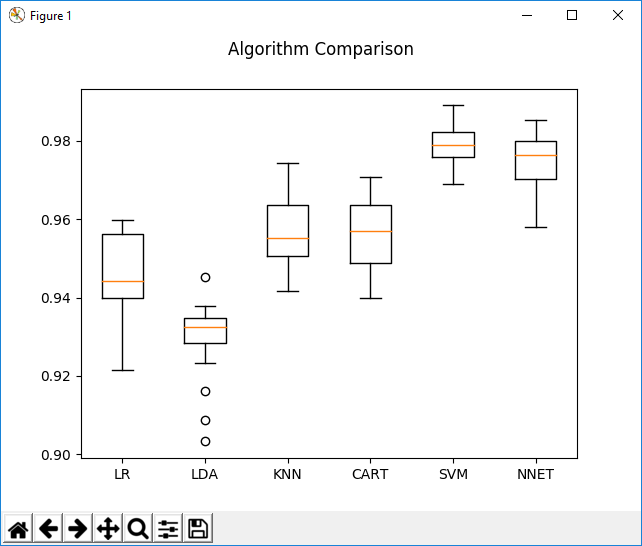
在先前的研究中,使用更大的数据集(N> 14,000)和60%/40%进行训练/验证,使用这些分类模型通常可以实现Bezier曲线的稳定验证精度> .98.这是(24:12:6:2)二进制文件的示例(使用Python)(In previous research, using a much larger data set (N>14,000) and 60%/40% for training/validation, stable validation accuracies >.98 for Bezier curves have typically been achieved using these classification models. Here is an example (using Python) of a (24:12:6:2) binary)神经网络与应用于该数据集的其他分类模型(逻辑回归,线性判别分析,K近邻,CART –决策森林和支持向量机)相比.(neural network compared to other classification models (logistic regression, linear discriminant analysis, K-nearest neighbor, CART – a decision forest, and a support vector machine) applied to that data set.)
结论(Conclusion)
从该系列的第一个演示得出的主要结论是,贝塞尔曲线对于在不同时间或X轴点收集的嘈杂的纵向数据可能是非常有用的模型.第二个推论是,如果模型是好的,那么关于此类模型的推论也可能是好的.可以以各种方式对性能轨迹进行分类的机器学习模型无疑将成为数据驱动决策的有益工具.(The principal conclusion drawn from the first demonstration in this series was that Bezier curves can be very useful models for noisy longitudinal data collected at varying time or X-axis points. A second inference was that if models are good, then inferences about such models may be good as well. Machine learning models that could classify performance trajectories in various ways would surely be a beneficial tool for data-driven decision-making.)
学校和学区使用商业学生信息系统(SIS)不断收集数据.但是,这种"原始"信息很少可以访问.一旦掌握了经过训练的模型,仪表板和其他可视化方法就可以访问该数据,对其进行分析,并向教育工作者提供决策工具,以实时进行单个或汇总队列分析.这些也许是本系列将来文章的主题.如果您对使用此项目系列中描述的方法进行的某些实际研究感兴趣,则可能对最近的AERA演讲感兴趣(Schools and school districts constantly gather data using commercial student information systems (SIS). But this “raw” information is seldom accessible. Once a trained model is in hand, dashboards and other visualization methods can access that data, analyze it, and present educators with decision-making tools for individual or aggregated cohort analyses in real time. These perhaps are topics for future articles in this series. If you are interested in some of the actual research done using approaches described in this project series, you may be interested in this recent AERA presentation entitled) 公共教育中的数据可视化(Data Visualizations in Public Education) .(.)
除此之外,该项目还提供了多种有用的技术和方法,用于处理Bezier曲线以及训练机器学习模型,以识别可被其他类似项目采用的此类曲线所反映的模式和趋势.(Beyond that, this project presents a variety of useful techniques and methods for working with Bezier curves and for training machine learning models to recognize patterns and trends reflected by such curves that can be adapted for other similar projects.)
历史(History)
- 3(3)rd(rd)2018年9月:1.0版(September, 2018: Version 1.0)
许可
本文以及所有相关的源代码和文件均已获得The Code Project Open License (CPOL)的许可。
XML C# VS2013 text machine-learning VS2017 CNTK AI 新闻 翻译