[译]使用Azure ML对代码段进行分类
By robot-v1.0
本文链接 https://www.kyfws.com/ai/classifying-code-snippets-with-azure-ml-zh/
版权声明 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
- 9 分钟阅读 - 4412 个词 阅读量 0使用Azure ML对代码段进行分类(译文)
原文地址:https://www.codeproject.com/Articles/1230612/Classifying-Code-Snippets-with-Azure-ML
原文作者:Scott Clayton
译文由本站 robot-v1.0 翻译
前言
Detect the programming language of a code snippet using neural networks in Azure ML Studio
在Azure ML Studio中使用神经网络检测代码段的编程语言
- 源代码-627.3 KB ZIP(Source Code - 627.3 KB ZIP)
- 源代码-GitHub(Source Code - GitHub)
- 培训模型-Azure(Training Model - Azure)
- Web服务-Azure(Web Service - Azure)
内容(Contents)
- 介绍(Introduction)
- 运行代码(Running the Code)
- 预处理数据(Preprocessing the Data)
- 训练模型(Training the Model)
- 改善结果(Improving the Results)
- 概要(Summary)
介绍(Introduction)
在本文中,我将说明如何使用Azure Machine Learning Studio训练神经网络分类器,以在识别代码段的编程语言时达到90%的准确性.(In this article, I explain how I trained a neural network classifier using Azure Machine Learning Studio to achieve 90% accuracy in identifying the programming language of a code snippet.)
这是针对具有现有ML Studio经验的个人的.有关ML Studio基础的更全面的演练,请阅读(This is targeted towards individuals with existing ML Studio experience. For a more thorough walkthrough on the basics of ML Studio, please read) 我的另一篇文章(my other article) .(.)
运行代码(Running the Code)
这是运行示例应用程序所需要做的.(Here is what you need to do to run the sample application.)
-
注册一个(Sign up for a) 免费的Azure ML Studio帐户(free Azure ML Studio account)
-
复制我的(Copy my) Azure Web服务(Azure web service) .(.)
- 点击"在Studio中打开"(Click “Open in Studio”)
- 点击"运行"(Click “Run”)
- 点击"设置Web服务"(Click “Set up Web Service”)
- 复制您的私有API密钥(Copy your private API Key)
- 点击"请求/响应"(Click “Request/Response”)
- 复制您的请求URI(端点)(Copy your Request URI (endpoint))
-
克隆我的(Clone my) GitHub存储库(GitHub repository)
- 编译并运行(Compile and run)
- 出现提示时输入服务端点(Enter your service endpoint when prompted)
- 出现提示时输入您的API密钥(Enter your API key when prompted)
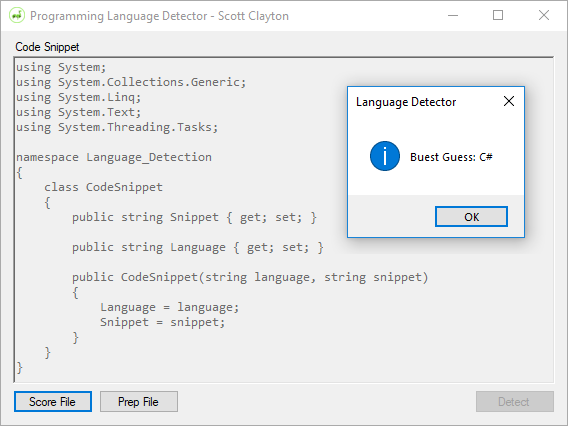
- 在文本字段中输入代码段,然后点击"检测"(Enter a code snippet into the text field and click “Detect”)
预处理数据(Preprocessing the Data)
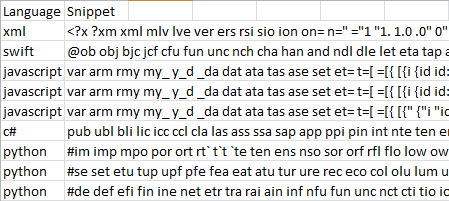
我们将使用的数据包含来自25种不同编程语言的677个标记代码段.每个片段都包裹在一个(The data we will be using contains 677 labelled code snippets from 25 different programming languages. Each snippet is wrapped in a) <pre> 标签并使用(tag and labelled using the) lang 属性.(attribute.)
<pre lang="ObjectiveC">
var protoModel : ProtoModel?
override func viewDidLoad() {
super.viewDidLoad()
// create and setup the model
self.protoModel = ProtoModel()
self.protoModel?.delegate = self
// setup the view
labelWorkStatus.text = "Ready for Work"
}
</pre>
我要做的第一件事是从它们的代码片段中解析出这些代码片段(The first thing I did was parse these code snippets out of their) <pre> 标签,并放入可管理的标记摘要列表中.一点正则表达式可以解决问题.(tags and into a manageable list of labelled snippets. A bit of Regex did the trick.)
public List<CodeSnippet> ExtractLabeledCodeSnippets(string html)
{
List<CodeSnippet> snippets = new List<CodeSnippet>();
MatchCollection matches =
Regex.Matches(html, "<pre.*?lang\\=\\\"(.*?)\\\".*?>(.*?)<\\/pre>",
RegexOptions.Singleline | RegexOptions.IgnoreCase);
foreach (Match m in matches)
{
snippets.Add(new CodeSnippet(m.Groups[1].Value, HttpUtility.HtmlDecode(m.Groups[2].Value)));
}
return snippets;
}
这些代码段不能作为一大段文本输入到分类器中,因此我需要找到一种方法来测量代码段中的不同功能.这是通过一种称为特征提取的方法完成的,其中将每个代码片段分解成小块,进行哈希处理,然后进行计数.(These snippets cannot be fed to a classifier as a big block of text, so I needed to find a way to measure distinct features within the snippets. This was done using a method called feature extraction, where each snippet is broken down into small chunks, hashed, and then counted.)
我的第一个尝试是简单地将代码拆分为空格和换行,以使每段代码成为其自己的功能.(My first attempt was to simply split the code on spaces and new lines so that each chunk of code became its own feature.)
class CleanFeatureExtractor : IFeatureExtractor
{
public List<string> ExtractFeatures(string input)
{
return input.Replace("\r", " ").Replace("\n", " ")
.Split(new string[] { " " }, StringSplitOptions.RemoveEmptyEntries).ToList();
}
}
这里的问题是,某些语言在没有空格的情况下可能会花费很长时间,因此,在整个数据集中仅出现一次的功能非常多.(The problem here is that you can go a long time without a space in some languages, so there were an extremely high number of features that appeared only one time in the entire data set.)
我的下一个尝试是在我之前的尝试的基础上扩展的,除了空格和换行之外,还拆分了符号.这些符号似乎对某种语言的身份至关重要,因此我也将它们作为自己的特征使用.(My next attempt expanded on my previous attempt by also splitting on symbols in addition to spaces and new lines. The symbols seemed critical to the identity of a language, so I kept them in as their own features too.)
class NGramFeatureExtractor : IFeatureExtractor
{
public List<string> ExtractFeatures(string input)
{
List<string> features = new List<string>();
// Clean input
input = input.ToLower().Replace("\r", " ").Replace("\n", " ");
// Extract words
features.AddRange(Regex.Replace(input, "[^a-z]", " ")
.Split(new string[] { " " }, StringSplitOptions.RemoveEmptyEntries));
// Extract symbols
features.AddRange(Regex.Replace(input, "[a-zA-Z0-9]", " ")
.Split(new string[] { " " }, StringSplitOptions.RemoveEmptyEntries));
return features;
}
}
不幸的是,我在这里也无法获得任何不错的结果.(Unfortunately, I was not able to get any decent results here either.)
我的最后尝试以及最终使用的尝试是将整个代码段分成一系列连续的字母.这为每个片段产生了很多功能,但这没关系,因为我们稍后将在训练之前删除无用的功能.(My final attempt, and the attempt I ended up using, was to split the entire snippet into groups of sequential letters. This produced a lot of features for each snippet, but that does not matter since we will remove useless features later before training.)
class LetterGroupFeatureExtractor : IFeatureExtractor
{
public int LetterGroupLength { get; set; }
public LetterGroupFeatureExtractor(int length)
{
LetterGroupLength = length;
}
public List<string> ExtractFeatures(string input)
{
Listt<string> features = new Listt<string>();
// Clean input
input = input.ToLower().Replace("\r", "")
.Replace("\n", "").Replace(" ", "");
for (int i = 0; i < input.Length - LetterGroupLength; i++)
{
features.Add(input.Substring(i, LetterGroupLength));
}
return features;
}
}
这将需要一个代码段(This will take a code snippet like) <b>bold</b> 并将其转换为很多N个字符的长字符串.对于(and convert it into a lot of N-character long strings. For) N=3 ,以上代码将分为9个功能:(, the above code would be split into 9 features: “) <b> “,"(”, “) b>b “,"(”, “) >bo " …您知道了.(”… You get the picture.)
我尝试了各种长度的字母组特征,而3似乎是魔幻数字.我将字母组的尺寸设置得越大,精度就会逐渐下降.(I experimented with various lengths of these letter group features, and 3 seemed to be the magic number. Accuracy gradually dropped the larger I made my letter group sizes.)
然后,将这些提取的特征保存到具有两列的CSV文件中-一列用于已知语言,一列用于提取特征的列表(基本上读起来像是很长的断断续续).这是我上传到Azure进行培训的文件.(These extracted features were then saved to a CSV file with two columns—one for the known language and one for the list of extracted features (which basically reads like a really long stutter). This is the file that I uploaded to Azure for training.)
在训练之前,我们需要对任意长的特征列表进行哈希处理,以便获得固定数量的列以供分类器使用.这就是我们如何将一组复杂的输入数据简化为可以训练的内容.(Before we can train, we need to hash our arbitrarily long list of features so that we get a fixed number of columns to feed the classifier. This is how we reduce a complex set of input data into something we can train on.)
我选择使用15位哈希(为我提供32,768个功能列),然后抛出除2,000个最有用列之外的所有列.为此,我选择了(I chose to use a 15 bit hash (to give me 32,768 feature columns) and then to throw out all but the 2,000 most useful columns. For this, I chose the) Mutual Information 计分方法,因为它导致最高的准确性(随后是Spearman Correlation和Chi Squared).(scoring method because it resulted in the higheset accuracy (followed by Spearman Correlation and Chi Squared).)
我在训练之前所做的最后一件事是在训练和测试之间将数据集划分为80%-20%,以便稍后我可以从我未训练的一组数据中计算出准确性.(The very last thing I did before training is split the data set 80%-20% between training and testing so that later I could calculate an accuracy off a set of data that I did not train on.)
训练模型(Training the Model)
为了进行训练,我尝试了所有四个可用的多类分类器,并发现神经网络给出了最好的结果(紧随其后的是逻辑回归).决策树和决策森林分类器的准确性从未超过78%.在研究了隐藏层神经元的数量之后,我最终降落到了100个.(For training, I tried all four available multiclass classifiers and found the neural network to give the best results (followed closely by logistic regression). The decision tree and decision forest classifiers never got above 78% accuracy. After playing around with the number of hidden layer neurons, I eventually landed on 100.)
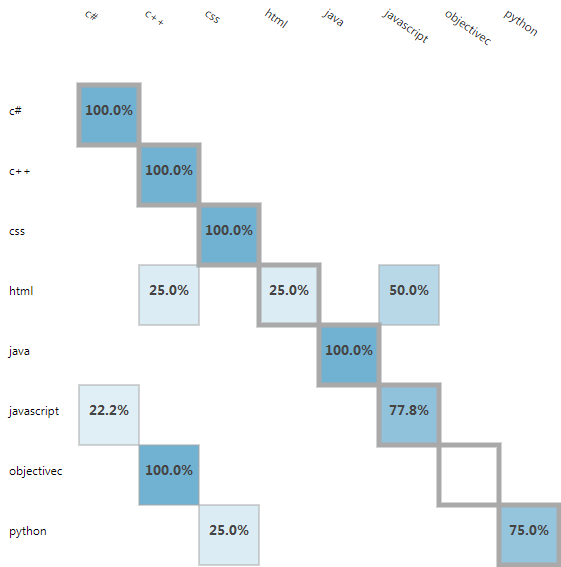
训练模型后,我很高兴看到整体精度为(After training the model, I was happy to see an overall accuracy of)90.54%(90.54%)在看不见的训练数据上.该模型将每个ObjectiveC代码片段误分类为C ++,并且似乎很难与JavaScript兼容,但是总体而言,它做得很好.(on the unseen training data. The model misclassified every ObjectiveC snippet as C++ and seemed to struggle with JavaScript, but overall it did a great job.)
从这里开始,我将模型作为Azure中的Web服务公开((From here, I exposed my model as a web service in Azure () 读这看如何(read this to see how) ),将其连接到我的应用程序,然后遍历整个片段.结果相当令人满意.我设法获得了总体准确性(), wired it up to my application, and then ran the entire set of snippets through. The results were quite satisfying. I managed to get an overall accuracy of)96%(96%)整个培训和测试集.(across the training and testing sets.)
Total: 677
Correct: 653
Incorrect: 24
Accuracy: 96.455%
改善结果(Improving the Results)
目前,我的模型具有相当不错的准确性,但是它仅基于数百个代码样本.为了解决这个问题,我从GitHub下载了24种不同语言的数十个大型项目,并提取了46,459个标记代码示例.(My model has a pretty decent accuracy at this point, but it is only based off of a few hundred code samples. To remedy this, I downloaded dozens of large projects from GitHub for 24 different languages and extracted 46,459 labelled code samples.)
大部分代码片段仅来自3种语言,因此我决定将每种语言限制为2,000个样本.我还排除了重复项和很小的摘录,并尝试删除尽可能多的评论.这使我总共减少了17,359个摘要.(The majority of the snippets were from just 3 languages, so I decided to limit each language to 2,000 samples. I also excluded duplicates and really small snippets, and tried to remove as many comments as possible. That brought me down to 17,359 total snippets.)
然后将这些代码片段进行拆分,以便将90%的代码用于训练,将10%的代码用于测试.(These snippets were then divided up so that 90% could be used for training and 10% could be used for testing.)
培训花费了更长的时间(因为它必须处理160MB的数据),但最终使我对1,735条未见测试的代码片段的整体准确性达到了99%.(Training took a lot longer (since it had to process 160MB of data), but eventually got me an overall accuracy of 99% on the 1,735 unseen testing snippets.)
最后,我通过更大的新模型运行了原始的677个摘要集(未用于训练).不幸的是,正如您在下面的混淆矩阵中看到的那样,它只能对53%的代码片段进行分类.(Finally, I ran the original set of 677 snippets (which were not used for training) through the new, much larger model. Unfortunately, as you can see in the confusion matrix below, it was only able to classify 53% of the snippets.)

我相信结果的差异是由于我的代码片段格式与所提供的代码片段有多么不同.给定几百小时的时间,我也许可以手动清理数据并获得更好的结果,但是算了.我还考虑过编写一个刮板程序,以从Code Project文章中下载一百万个带有标签的摘要,但我想我不会被禁止.(I believe the varied results are due to just how different the format of my snippets are from the provided snippets. Given a few hundred hours, I might be able to manually clean up the data and get better results, but forget that. I also considered writing a scraper to download a million labelled snippets off Code Project articles, but figured I would rather not get banned.)
我试图找到一种方法来删除注释和字符串文字,并为已知的关键字赋予更多的权重,但这仅在您首先知道要使用哪种语言时才有效.对于训练和真实数据集,预处理步骤必须完全相同,因此使用标签是不可行的(因为未标记真实数据).(I tried to find a way to remove comments and string literals and give extra weight to known keywords, but that will only work if you first know what language you are dealing with. The preprocessing step needs to be exactly the same for both the training and real-life data sets, so using the label is off limits (since real-life data is not labelled).)
概要(Summary)
我设法训练了一个模型,该模型能够对67个看不见的摘要中的90%和所有677个摘要中的96%进行分类.(I managed to train a model capable of classifying 90% of the 67 unseen snippets and 96% of all 677 snippets.)
最初的数据集很小,所以我创建了自己的训练集,在1735个未见片段中,我获得了99%的准确度,而在原始677个片段中,我获得了53%的准确性(由于格式上的差异).(The initial data set was small, so I created my own set for training which got me 99% accuracy on 1,735 unseen snippets, but only 53% accuracy on the original 677 snippets (due to differences in format).)
这是一个非常有意义的项目,我在工作中学到了很多东西.(This was a very rewarding project, and I learned a lot while working on it.)
谢谢!(Thanks!)
历史(History)
- 2/16/2018(2/16/2018)- 初始发行(- Initial release)
许可
本文以及所有相关的源代码和文件均已获得The Code Project Open License (CPOL)的许可。
C# VS2013 Azure Dev Architect machine-learning 新闻 翻译