[译]CNeuralNetwork:使您的神经网络学习更快
By robot-v1.0
本文链接 https://www.kyfws.com/ai/cneuralnetwork-make-your-neural-network-learn-fast-zh/
版权声明 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
- 12 分钟阅读 - 5797 个词 阅读量 0CNeuralNetwork:使您的神经网络学习更快(译文)
原文地址:https://www.codeproject.com/Articles/38933/CNeuralNetwork-Make-Your-Neural-Network-Learn-Fast
原文作者:auralius manurung
译文由本站 robot-v1.0 翻译
前言
An article on making neural network learn faster
有关使神经网络学习更快的文章
介绍(Introduction)
The Code Project上有很多可用的文章,讨论了有关神经网络的概念和实现.但是,当我想了解如何实现Nguyen-Widrow初始化算法时,我找不到一个.因此,我通过互联网进行搜索,阅读了一些科学论文和书籍,最后尝试将我阅读的那些内容实现为C ++中适用的算法.对于我们来说,作为学生,我们在课堂上学习的东西与如何将其实现到现实世界中的应用之间存在很大的差距.通过将我设法学习的所有内容都放在一个C ++类中((There are many available articles on The Code Project discussing about neural network concept and implementation. But when I wanted to find out how to implement Nguyen-Widrow initialization algorithm, I could not find one. So I searched through the internet, read some scientific papers and books and finally tried to implement those things I read into an applicable algorithm in C++. For us, as students, there are big gaps between things we learn in class and how to implement them into real world applications. By putting all things that I managed to learn into a single C++ class () CNeuralNetwork )并与他们分享,希望我能帮助遇到相同问题的其他人.这里的主要神经网络代码基于() and share them, I hope I can help others who encounter the same problem. The main neural network code here is based on) 丹尼尔`阿德马苏(Daniel Admassu)(Daniel Admassu) 工作.我在此类中设法实现的事情是:(work. Things I managed to implement in this class are:)
- 权重初始化算法(一些常规方法和Nguyen-Widrow方法)(Weight initialization algorithm (some ordinary methods and Nguyen-Widrow method))
- 动量学习(Momentum learning)
- 适应性学习(Adaptive learning) 这三个概念将使我们创建的神经网络能够更快地学习(迭代次数更少).尽管这些仍然是小事,但我认为在这里分享它们是个好主意.(Those three concepts will make the neural network we created able to learn faster (with less iterations). Although those are still minor thingies, I think it is a good idea to share them here.)
背景(Background)
您可能需要对神经网络理论有基本的了解.由于我使用的是反向传播方法(一种简单的方法),因此我相信您可以找到很多有关它的教程.(You might need a basic understanding of neural network theory. Since I am using back propagation method (the simple one), I am sure you can find a lot of tutorials about it.)
概念(Concepts)
前馈(Feed-forward)
在这里,我们使用多层感知器(MLP)神经网络体系结构. MLP由几层组成,通过加权连接相互连接. MLP至少具有三层,分别是输入层,隐藏层和输出层.我们可以有几个隐藏层.在每个神经元中,我们分配一个激活函数,该函数将由加权输入信号触发.这个想法是:我们希望为所有权重找到合适的值,以便我们提供的一组输入将导致我们想要的一组输出.(Here we are using multilayer percepteron (MLP) neural network architecture. MLP consists of several layers, interconnected through weighted connections. MLP has at least three layers, they are input layer, hidden layer, and output layer. We can have several hidden layers. In each neuron, we assign an activation function which will be triggered by weighted input signal. The idea is: we want to find the appropriate value for all weights so that one set of input that we give will results in one set of output as we desire.)
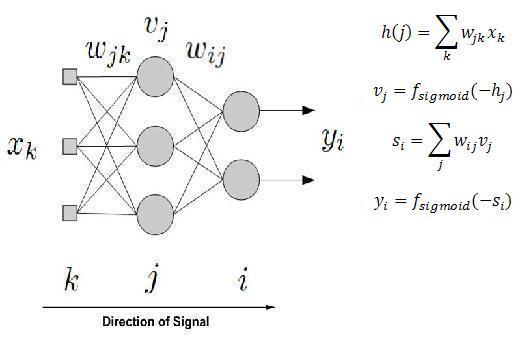 在这里(Here, for)
在这里(Here, for) CNeuralNetwork 在隐藏和输出层中,我将双极逻辑函数用作激活函数.在输入层中,我使用单位函数.选择合适的激活功能也可以加快学习速度.从理论上讲,具有较低饱和速度的S型函数将产生更好的结果.(, I use bipolar logistic function as the activation function in hidden and output layer. While in input layer, I use unity function. Choosing an appropriate activation function can also contribute to a much faster learning. Theoretically, sigmoid function with less saturation speed will give a better result.)
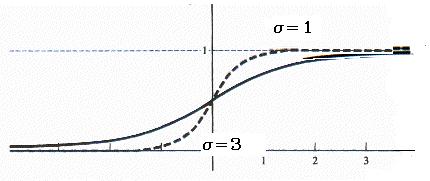
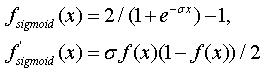 在(In)
在(In) CNeuralNetwork ,我只提供双极物流功能.但是您可以操纵它的斜率,看看它如何影响学习速度.较大的斜率将使权重值更快地移至饱和区域(收敛更快),而较小的斜率将使权重值更慢地移动,但可以进行精确的权重调整.(, I only provide bipolar logistic function. But you can manipulate its slope (s) and see how it affects the learning speed. A larger slope will make weight values move faster to saturation region (faster convergence), while smaller slope will make weight values move slower but it allows a refined weight adjustment.)
反向传播(Back-propagation)
在前馈过程中,网络将基于给定的输入来计算输出.接下来,它将将此计算的输出与所需的输出进行比较以计算误差.下一个任务是最大程度地减少此错误.我们选择哪种方法来最大程度地减少此错误也将决定学习速度.梯度下降法是最小化此误差的最常用方法.最后,它将更新权重值,如下所示:(In feed-forward process, the network will calculate the output based on the given input. Next, it will compare this calculated output to the desired output to calculate the error. The next mission is to minimize this error. What method we choose for minimizing this error will also determine the learning speed. Gradient descent method is the most common for minimizing this error. Finally, it will update the weight value as the following:)
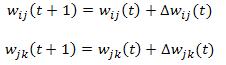 哪里:(where:)
哪里:(where:)
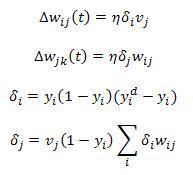 除了这种梯度下降方法外,还有其他几种方法可以保证更快的学习速度.它们是共轭梯度法,拟牛顿法,Levenberg-Marquardt法等.但是对我来说,这些方法太复杂了.因此,代替使用这些方法,我们可以通过添加动量项或使用自适应学习率来加快学习过程.(Besides this gradient descent method, there are several other methods that will guarantee a faster learning speed. They are conjugate gradient method, quasi-Newton method, Levenberg-Marquardt method, and so on. But for me, those methods are too complicated. So, instead of using those methods, we can make the learning process much faster by adding momentum term or by using adaptive learning rate.)
除了这种梯度下降方法外,还有其他几种方法可以保证更快的学习速度.它们是共轭梯度法,拟牛顿法,Levenberg-Marquardt法等.但是对我来说,这些方法太复杂了.因此,代替使用这些方法,我们可以通过添加动量项或使用自适应学习率来加快学习过程.(Besides this gradient descent method, there are several other methods that will guarantee a faster learning speed. They are conjugate gradient method, quasi-Newton method, Levenberg-Marquardt method, and so on. But for me, those methods are too complicated. So, instead of using those methods, we can make the learning process much faster by adding momentum term or by using adaptive learning rate.)
增加动量项(Adding Momentum Term)
在动量学习中,时间(t + 1)的权重更新包含先前学习的动量.因此,我们需要保留先前的error和输出值.(In momentum learning, weight update at time (t+1) contains momentum of the previous learning. So we need to keep the previous value of error and output.)
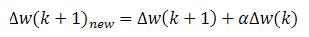 上面的等式可以如下实现.变量a是动量值.该值应大于零且小于一.(The equation above can be implemented as the following. Variable a is the momentum value. The value should be greater than zero and smaller than one.)
上面的等式可以如下实现.变量a是动量值.该值应大于零且小于一.(The equation above can be implemented as the following. Variable a is the momentum value. The value should be greater than zero and smaller than one.)
void CNeuralNetwork::calculate_weights()
{
for(unsigned int i=1;i<m_layer_num;i++){
for(unsigned int j=0;j<m_neuron_num[i];j++){
for(unsigned int k=0;k<m_neuron_num[i-1];k++){
float delta = m_learning_rate * m_error[i][j] * m_node_output[i-1][k];
float delta_prev = m_learning_rate * m_error_prev[i][j]
* m_node_output_prev[i-1][k];
m_weight[i][j][k] = (float) m_weight[i][j][k] + delta +
m_momentum * delta_prev;
}
}
}
}
适应性学习(Adaptive Learning)
对于自适应学习,其思想是根据当前误差和先前误差自动更改学习率.有很多方法可以执行此想法.这是我能找到的最简单的方法.(For adaptive learning, the idea is to change the learning rate automatically based on current error and previous error. There are many methods to perform this idea. Here is the easiest that I can find.)
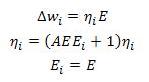 这个想法是观察最后两个错误,并在减少第二个错误的方向上调整学习率.两者都可变(The idea is to observe the last two errors and adjust the learning rate in the direction that would have reduced the second error. Both variable) `` 和(and)
这个想法是观察最后两个错误,并在减少第二个错误的方向上调整学习率.两者都可变(The idea is to observe the last two errors and adjust the learning rate in the direction that would have reduced the second error. Both variable) `` 和(and) Ei 是当前和先前的错误.参数(are the current and previous error. Parameter) A 是确定学习速度调整速度的参数.参数(is a parameter that will determine how rapidly the learning rate is adjusted. Parameter) A 应该小于1并大于零.如果当前误差小于先前误差,您还可以尝试通过将当前学习率乘以大于一的因数来尝试另一种方法.如果当前误差大于先前误差,则可以将其乘以小于一的因数.在马丁哈根(Martin Hagan)的书中,还建议如果错误增加,则放弃更改.这会带来更好的结果.您可以在功能中找到自适应学习例程(*should be less than one and greater than zero. You can also try another method by multiplying the current learning rate with a factor greater than one if current error is smaller than previous error. And if current error is bigger than previous error, you can multiply it with a factor less than one. In Martin Hagan book, it is also suggested that you discard the changes if the error is increasing. This will lead into a better result.You can find adaptive learning routine in function*) ann_train_network_from_file` 每个时期执行一次学习率更新.(where learning rate update is performed once per epoch.)
int CNeuralNetwork::ann_train_network_from_file
(char *file_name, int max_epoch, float max_error, int parsing_direction)
{
int epoch = 0;
string line;
ifstream file (file_name);
m_average_error = 0.0F;
if (file.is_open()){
for (epoch = 0; epoch <= max_epoch; epoch++){
int training_data_num = 0;
float error = 0.0F;
while (! file.eof() ){
getline(file, line);
if (line.empty()) break;
parse_data(line, parsing_direction);
calculate_outputs();
calculate_errors();
calculate_weights();
error = error + get_average_error();
training_data_num ++;
}
file.clear(); // clear buffer
file.seekg(0, ios::beg); // go to beginning of file
float error_prev = m_average_error;
m_average_error = error/training_data_num;
if (m_average_error <= max_error)
break;
// update learning rate
m_learning_rate = m_learning_rate*
(m_lr_factor*m_average_error*error_prev + 1);
}
}
file.close();
return epoch; // returns number of required epochs
}
权重初始化算法(Weight Initialization Algorithm)
从我读过的几篇论文中可以知道,特定的初始化值会影响收敛速度.有几种方法可用于此目的.最常见的方法是在一定数量的小范围内以均匀的分布随机初始化权重.在(From several papers I read, it is known that the particular initialization values give influences to the speed of convergence. There are several methods available for this purpose. The most common is by initializing the weights at random with uniform distribution inside the interval of a certain small range of number. In) CNeuralnetwork ,我称这种方法(, I call this method) HARD_RANDOM 因为找不到该方法的现有名称.另一个更好的方法是限制范围,如以下公式所示.在(because I cannot find the existing name for this method. Another better method is by bounding the range as expressed in the equation below. In) CNeuralNetwork ,我只用这种方法(, I call this method with just) RANDOM .(.)
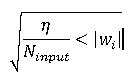 Nguyen-Widrow方法是众所周知的非常好的权重初始化方法.在(Widely known as a very good weight initialization method is the Nguyen-Widrow method. In)
Nguyen-Widrow方法是众所周知的非常好的权重初始化方法.在(Widely known as a very good weight initialization method is the Nguyen-Widrow method. In) CNeuralNetwork ,我将此方法称为(, I call this method as) NGUYEN . Nguyen-Widrow权重初始化算法可以表示为以下步骤:(. Nguyen-Widrow weight initialization algorithm can be expressed as the following steps:)
 如上述算法所述,首先,我们为所有隐藏节点分配-1到1的随机数.接下来,我们计算通过调用函数生成的这些随机数的范数(As stated in the algorithm as written above, first, we assign random number of -1 to 1 to all hidden nodes. Next, we calculate the norm of these random numbers that we have generated by calling function)
如上述算法所述,首先,我们为所有隐藏节点分配-1到1的随机数.接下来,我们计算通过调用函数生成的这些随机数的范数(As stated in the algorithm as written above, first, we assign random number of -1 to 1 to all hidden nodes. Next, we calculate the norm of these random numbers that we have generated by calling function) get_norm_of_weight .现在我们有了所有必要的数据,我们可以继续进行可用的公式.所有的权重初始化例程都位于函数中(. Now we have all the necessary data and we can proceed to the available formula. All the weight initialization routines are located in function) initialize_weights .(.)
void CNeuralNetwork::initialize_weights()
{
// METHOD 1
if (m_method == HARD_RANDOM){
for(unsigned int i=1;i<m_layer_num;i++)
for(unsigned int j=0;j<m_neuron_num[i];j++)
for(unsigned int k=0;k<m_neuron_num[i-1];k+
m_weight[i][j][k]=rand_float_range(-m_init_val, m_init_val);
}
// METHOD 2
else if (m_method == RANDOM){
float range = sqrt(m_learning_rate / m_neuron_num[0]);
for(unsigned int i=1;i<m_layer_num;i++)
for(unsigned int j=0;j<m_neuron_num[i];j++)
for(unsigned int k=0;k<m_neuron_num[i-1];k++)
m_weight[i][j][k]=rand_float_range(-range, range);
}
// METHOD 3
else if (m_method == NGUYEN){
for(unsigned int i=1;i<m_layer_num;i++)
for(unsigned int j=0;j<m_neuron_num[i];j++)
for(unsigned int k=0;k<m_neuron_num[i-1];k++)
m_weight[i][j][k]=rand_float_range(-1, 1);
for(unsigned int i=1;i<m_layer_num;i++){
float beta = 0.7 * pow((float) m_neuron_num[i], (float) 1/m_neuron_num[0]);
for(unsigned int j=0;j<m_neuron_num[i];j++){
for(unsigned int k=0;k<m_neuron_num[i-1];k++)
m_weight[i][j][k]=beta * m_weight[i][j][k] / get_norm_of_weight(i,j);
}
}
}
}
使用代码(Using The Code)
公开方法:(Public methods:)
- 创建一个新的神经网络.(Create a new neural network.)
- 设置学习率值.(Set learning rate value.)
- 设置动量值.(Set momentum value.)
- 设置自适应学习功能的学习率变化因子.(Set learning rate changing factor for adaptive learning feature.)
- 设置逻辑S形激活功能的斜率值.(Set slope value for logistic sigmoid activation function.)
- 设置所需的重量初始化方法.(Set desired weight initialization method.)
- 在输入层中为每个神经元设置当前输入.(Set current input per neuron in input layer.)
- 训练完成后,在一个纪元中获取最后的平均错误.(Get last average error in one epoch after a training completes.)
- 执行模拟后获取输出.(Get the output after performing simulation.)
- 获取完成培训所需的纪元数.(Get number of epoch needed to complete training.)
- 用来自文本文件的训练集训练神经网络.火车集的文本文件可以是逗号分隔或空格分隔的文件.设置(Train the neural network with train set from a text file. Text file for train set can be a comma separated or white-space separated file. Set the)
parsing_direction成为(to become)INPUT_FIRST如果在该文本文件中输入优先.如果首先输出,则设置(if in that text file input comes first. If output comes first, set the)parsing_direction成为(to become)OUTPUT_FIRST.训练的结果,例如重量值,所需的次数,一个时期的最终平均MSE等,将记录到文件中(. Result of the training, such as weight values, number of epochs required, final average MSE in one epoch, etc. will be logged to file)result.log(result.log).(.) - 使用参数中指定的文本文件中的测试集测试训练有素的神经网络(Test the trained neural network with test set from a text file specified in parameter)
file_name.结果将记录到参数中指定的另一个文件中(. The result will be logged to another file specified in parameter)log_file.(.) - 根据当前输入模拟神经网络.(Simulate the neural network based on the current input.)
- 删除所有先前动态创建的动态变量,避免内存泄漏.(Delete all previous dynamically created dynamic variables, avoiding memory leakage.)
以下是如何使用的示例(The following is the example of how to use)
CNeuralNetwork.我把这个课程放在文件中(. I put this class is in file)**神经网络(Neural Network.h)**和(and)神经网络(Neural Network.cpp).如果要使用此类,则只需在项目中包括这两个文件.(. If you want to use this class, you just need to include these two files in your project.)
// main.cpp
#include "stdafx.h"
#include "Neural Network.h"
int main()
{
float *result;
CNeuralNetwork nn;
nn.ann_set_learning_rate(0.5);
nn.ann_set_momentum(0);
nn.ann_set_lr_changing_factor(0);
nn.ann_set_slope_value(1);
nn.ann_set_weight_init_method(nn.NGUYEN);
nn.ann_create_network(2,1,1,3);
int epoch = nn.ann_train_network_from_file("input.txt", 500, 0.01, nn.OUTPUT_FIRST);
printf("number of epoch: %i with final error:
%f\n",epoch, nn.ann_get_average_error());
//Test: 1 XOR 1
nn.ann_set_input_per_channel(0, 1.0F);
nn.ann_set_input_per_channel(1, 1.0F);
nn.ann_simulate();
printf("%f\n", nn.ann_get_output(0));
//Test: 0 XOR 0
nn.ann_set_input_per_channel(0, 0.0F);
nn.ann_set_input_per_channel(1, 0.0F);
nn.ann_simulate();
printf("%f\n", nn.ann_get_output(0));
//Test: 1 XOR 0
nn.ann_set_input_per_channel(0, 1.0F);
nn.ann_set_input_per_channel(1, 0.0F);
nn.ann_simulate();
printf("%f\n", nn.ann_get_output(0));
//Test: 0 XOR 1
nn.ann_set_input_per_channel(0, 0.0F);
nn.ann_set_input_per_channel(1, 1.0F);
nn.ann_simulate();
printf("%f\n", nn.ann_get_output(0));
nn.ann_clear();
}
实验(Experiment)
为了了解这些想法是如何工作的,我们将对经典XOR问题进行一些实验.对于这个XOR问题,我们将创建一个神经网络,该网络由1个隐藏层和3个神经元组成.首先,我们将了解神经网络中权重初始化问题的有效程度.然后,我们将尝试激活动量学习和自适应学习功能,并了解学习过程如何获得更快的速度.我们的目标是达到一个时期的平均均方误差=0.01.所有实验均以学习率=0.5进行,最大纪元数限制为500个纪元.从实验中,我们可以看到现有方法如何将训练过程加快两倍以上.(To see how these ideas work, we will carry out some experiments with classic XOR problem. For this XOR problem, we will create a neural network that consists of 1 hidden layer with 3 neurons. First we will see how effective weight initialization issue is in a neural network. Then we will try to activate momentum learning and adaptive learning feature and see how the learning process gains more speed. Our target is to achieve average mean squared error of one epoch = 0.01. All the experiments are conducted with learning rate = 0.5 and maximum number of epoch is limited to 500 epochs. From the experiment, we can see how the existing methods will speed up the training process more than twice.)
- 学习率变化因子=0;动量=0;权重初始化方法=HARD_RANDOM,范围为-0.3到0.3.(Learning rate changing factor = 0; Momentum = 0; Weight initialization method = HARD_RANDOM with range -0.3 to 0.3.)在500个纪元内未达到最小均方误差的目标.(Target of minimum mean square error is not achieved within 500 epochs.)
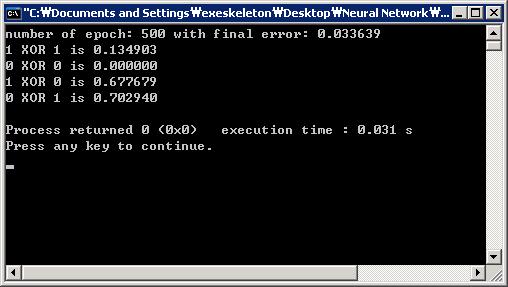
- 学习率变化因子=0;动量=0;权重初始化方法=RANDOM.(Learning rate changing factor = 0; Momentum = 0; Weight initialization method = RANDOM.)在500个纪元内未达到最小均方误差的目标.(Target of minimum mean square error is not achieved within 500 epochs.)
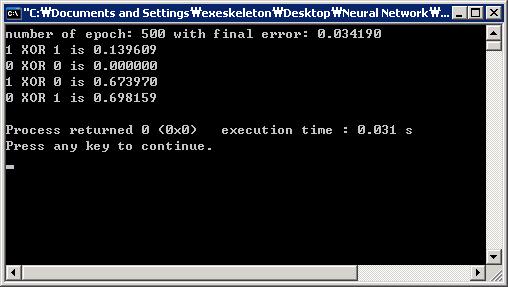
- 学习率变化因子=0;动量=0;权重初始化方法=NGUYEN.(Learning rate changing factor = 0; Momentum = 0; Weight initialization method = NGUYEN.)最小均方误差的目标在262个纪元内实现.(Target of minimum mean square error is achieved within 262 epochs.)
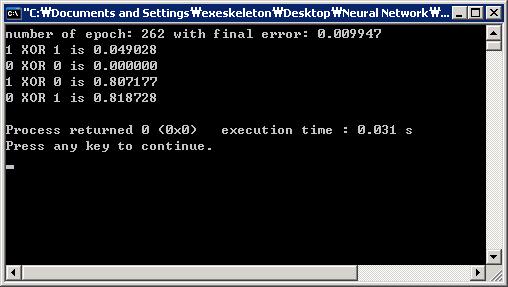
- 学习率变化因子=0;动量=0.5;权重初始化方法=NGUYEN.(Learning rate changing factor = 0; Momentum = 0.5; Weight initialization method = NGUYEN.)最小均方误差的目标在172个纪元内实现.(Target of minimum mean square error is achieved within 172 epochs.)

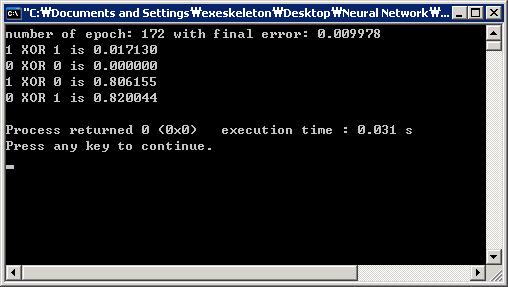
- 学习率变化因子=0.5;动量=0;权重初始化方法=NGUYEN.(Learning rate changing factor = 0.5; Momentum = 0; Weight initialization method = NGUYEN.)最小均方误差的目标在172个纪元内实现.(Target of minimum mean square error is achieved within 172 epochs.)
兴趣点(Points of Interest)
所有代码都在一个类中实现:(All the code is implemented in a single class:) CNeuralNetwork .这样,我希望对理解C ++中的神经网络实现更多信息的学生而言,它足够容易理解.对于进一步的工作,我仍然打算学习更多并实施在这里学到的东西,并期望对其他人有用.供您参考,我还提供了一个来自UCI数据库的额外培训文件.您可以使用此文件来测试您的神经网络.由于此类使用C ++的基本功能,因此它也可以在Linux中很好地运行.(. In that way, I hope it will be simple and easy enough to understand especially for students seeking more information about neural network implementation in C++. For further work, I still have an intention to learn more and to implement things I learn here with an expectation that it will be useful for others. For your information, I also included an extra training file from UCI database. You can use this file to test your neural network. Since this class is using basic function of C++, it will also run nicely in Linux.)
参考文献(References)
- 反向传播算法,温宇(Back Propagation Algorithm, by Wen Yu)
- Nguyen,D.和Widrow,B.,“通过选择自适应权重的初始值来提高2层神经网络的学习速度”,美国IJCNN,1990年(Nguyen, D. and Widrow, B., “Improving The Learning Speed of 2-layer Neural Networks by Choosing Initial Values of The Adaptive Weights”, IJCNN, USA, 1990)
- MercedesFernández-Redondo,CarlosHernández-Espinosa,“多层前馈网络的权重初始化方法之间的比较”,IJCN,意大利,2000年(Mercedes Fernández-Redondo, Carlos Hernández-Espinosa, “A Comparison among Weight Initialization Methods for Multilayer Feedforward Networks,” IJCN, Italy, 2000)
- Prasanth Kumar,韩国庆尚国立大学机械与航空航天工程学院智能控制讲义(Prasanth Kumar, Intelligent Control Lecture Note, School of Mechanical and Aerospace Engineering, Gyeongsang National University, Republic of Korea)
历史(History)
- 9(9)日(th)2009年8月:初始版本(August, 2009: Initial version)
许可
本文以及所有相关的源代码和文件均已获得The Code Project Open License (CPOL)的许可。
C++ Linux Windows Dev 新闻 翻译