[译]使用ClassifyBot在.NET中创建ML分类管道
By robot-v1.0
本文链接 https://www.kyfws.com/ai/create-a-ml-classification-pipeline-in-net-with-cl-zh/
版权声明 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
- 31 分钟阅读 - 15418 个词 阅读量 0使用ClassifyBot在.NET中创建ML分类管道(译文)
原文地址:https://www.codeproject.com/Articles/1233098/Create-a-ML-Classification-Pipeline-in-NET-with-Cl
原文作者:Allister Beharry
译文由本站 robot-v1.0 翻译
前言
We’ll use the ClassifyBot program to put together an ML pipeline to solve a text classification problem using open-source ML components
我们将使用ClassifyBot程序将ML管道组合在一起,以使用开源ML组件解决文本分类问题
介绍(Introduction)
分类机器人(ClassifyBot) 是一个开源的跨平台.NET库,它尝试使用不同的开源ML和NLP库(例如斯坦福大学NLP,NLTK,TensorFlow,CNTK等)来自动化并重现创建用于对象分类的机器学习管道所需的步骤. ML项目通常可以被认为是"管道"或工作流,其中数据按顺序移动到不同阶段,每个阶段对数据集执行特定操作.原始数据或存档数据中的数据很少采用特定ML工具或任务所需的格式,因此所有ML项目通常都以代码开始,以某种方式检索和预处理并准备数据,以便可以将其加载到特定机器中.学习图书馆.拥有正确格式的数据源后,您将需要执行以下操作:选择分类任务的功能,以不确定性的方式将数据拆分为训练和测试数据集,基于训练数据集创建模型,进行测试测试数据集上的模型并报告结果,根据测试结果调整模型和分类器参数,等等.对于不同的数据源,不同的数据集,不同的分类模型和参数以及不同的分类器库,必须重复此过程的每个步骤.(is an open-source cross-platform .NET library that tries to automate and make reproducible the steps needed to create machine learning pipelines for object classification using different open-source ML and NLP libraries like Stanford NLP, NLTK, TensorFlow, CNTK and on. An ML project can often be thought of as a ‘pipeline’ or workflow where data moves sequentially through different stages that each perform a specific operation on the dataset. Data in the wild or archived data is rarely in the format needed for specific ML tools or tasks, so all ML projects usually begin with code to retrieve and preprocess and prepare the data in a certain way so that it can be loaded into a particular machine learning library. Once you have a data source in the right format, you will want to do operations like select the features for your classification task, split the data into training and test datasets in a non-deterministic way, create models based on your training dataset, test the model on your test dataset and report the result, adjust model and classifier parameters based on the results of your tests, and so on. Each step of this process has to be repeated for different data sources, different datasets, different classification models and parameters and different classifier libraries.)
对于您启动的每个ML项目,您都可以编写代码来实现每个步骤,并手动将参数和不同步骤连接在一起.但是,许多此类操作可以以Python或R或F#或其他代码创建可重用和可再现的数据操作的名义实现自动化,这些操作也可以与其他应用程序集成,并通过共享服务部署到不同的环境中,例如日志.在这种情况下,自动化也不是特定于工具,库或语言的,这样您就可以独立于特定技术来设计管道.这些类型的需求通常发生在"数据工程"或" ScienceOps"的环境中,其中部署了由数据科学家或程序员创建的ML模型和管道来支持公司的日常运营.但是,凡是对ML和数据科学感兴趣的人,只要能够学习和使用不同的工具和语言来构建ML实验,同时最大程度地减少重复和编写样板代码,都将发现这种自动化非常有用.(For each ML project you start, you can write the code to implement each step and wire the parameters and different steps together manually. However a lot of this can be automated in the name of creating reusable and reproducible data operations out of your Python or R or F# or other code, that can also integrate with other applications and be deployed to different environments with shared services for things like logging. It should also be the case that the automation is not tool or library or language specific to allow you to design your pipeline independently of a specific technology. These kinds of requirements often occur in the context of “data-engineering” or “ScienceOps” where ML models and pipelines created by data scientists or programmers are deployed to support day-to-day operations of a company. But anyone interested in ML and data science who would like to be able to learn and use different tools and languages to build ML experiments while minimizing duplication and writing boilerplate code, will find such automation useful.)
通过为数据处理管道提供逻辑模型,ClassifyBot尝试自动化构建此类ML分类项目和实验的过程,其中每个管道被分成不同的独立的独立阶段,这些阶段根据不同的参数执行特定的操作.每个阶段都可以使用任何库或语言来对输入数据集实施所需的操作,并且仅需要公开由管道驱动程序调用的精简.NET接口.不同于像这样的数据管道库(ClassifyBot tries to automate the process of building these kinds of ML classification projects and experiments by providing a logical model for data processing pipelines where each pipeline is split into different discrete self-contained stages that perform a specific operation according to different parameters. Each stage can use any library or language to implement the required operation on the input dataset and is only required to expose a thin .NET interface that is called by the pipeline driver. Unlike data pipeline libraries like) 级联(Cascading,) 对于如何在管道中实现每个阶段,ClassifyBot并没有意见.每个阶段的默认行为是仅生成文件(通常为JSON),供以后的阶段以及用户要使用的任何工具或语言使用.使用以下库提供与Python,R和Java代码的互操作(ClassifyBot isn’t opinionated on how you implement each stage in your pipeline. The default behaviour for each stage is to simply produce files (usually JSON) that can be consumed by later stages and by any tool or language the user wants to use. Interop with Python and R and Java code is provided using libraries like) pythonnet(pythonnet) 或通过命令行调用执行.使用命令行调用来产生单独的过程对于与R之类的语言进行互操作很有用,这些语言具有已获得完整GPL许可的工具链和库,并且无法链接到其他非GPL代码.例如,这是(or by execution through command-line invocation. Using command-line invocation to produce a separate process is useful for interoperating with languages like R that have toolchains and libraries licensed under the full GPL and can’t be linked to other non-GPL code. For instance, here’s the) 斯坦福大学NLP分类器(Stanford NLP Classifier) 它是用Java编写的,并通过GPL许可作为外部过程调用:(which is written in Java and GPL-licensed being invoked as an external process:)
流水线阶段中的数据项或记录源自(Data items or records in a pipeline stage derive from) Record<TFeature> 代表包含一个或多个的单个数据项(which represents a single data item containing one or more) string 标签或具有相关分数的类别,以及一个或多个(labels or classes with associated scores, and one or more) TFeature 代表数据项具有的单个功能.拥有统一的数据模型可以最大程度地减少数据操作中的重复:您可以编写适用于数据项,类和功能的任意组合的通用代码.每个阶段都实现一个或多个接口,例如(s which represent individual features that a data item has. Having a uniform data model minimizes duplication in data operations: you can write generic code that works with any combination of data items, classes, and features. Each stage implements one or more interfaces like) IExtractor<TRecord, TFeature> 表示它可以执行的操作类型.阶段的参数只是.NET类属性,装饰有一个属性,该属性指示应作为一个选项将其公开在用户界面中.整个管道由易于使用的CLI界面驱动,该界面自动将管道阶段及其参数公开为CLI动词和选项. ClassifyBot自动将阶段参数连接到命令行选项,例如:(which indicate the kind of operation it can perform. A parameter for a stage is just a .NET class property decorated with an attribute indicating it should be exposed in the user interface as an option. The whole pipeline is driven by an easy-to-use CLI interface that automatically exposes pipeline stages and their parameters as CLI verbs and options. ClassifyBot does the wiring of stage parameters to command-line options automatically e.g.:)
[Option('u', "url", Required = true, HelpText = "Input data file Url.
A file with a .zip or .gz or .tar.gz extension will be automatically decompressed.")]
public virtual string InputFileUrl { get; set; }
声明一个名为(declares a parameter called) InputFileUrl 可以使用以下命令在命令行上指定(that can be specified on the command line using) -u 要么(or) --url .(.)
您可以使用标准的OOP机制(例如继承,组合等)在不同的管道中创建和重用不同的阶段.例如,(You can create and re-use different stages in different pipelines using the standard OOP mechanisms like inheritance, composition et.al. For instance, the) WebFileExtract 阶段是从(stage is a class that derives from the) FileExtract 类并共享大多数相同的代码:(class and shares most of the same code:)
public abstract class WebFileExtract<TRecord, TFeature> :
FileExtract<TRecord, TFeature> where TFeature : ICloneable, IComparable,
IComparable<TFeature>, IConvertible, IEquatable<TFeature> where TRecord : Record<TFeature>
{
public WebFileExtract() : base("{0}-clbot-web-extract-dl.tmp".F(DateTime.Now.Ticks))
{
Contract.Requires(!InputFileUrl.Empty());
if (Uri.TryCreate(InputFileUrl, UriKind.RelativeOrAbsolute, out Uri result))
{
InputFileUri = result;
}
else throw new ArgumentException
("The input file Url {0} is not a valid Uri.".F(InputFileUrl));
}
基地(The base) FileExtract 创建阶段以在孩子下载的临时本地文件上运行(stage is created to run on a temporary local file downloaded by the child) WebFileExtract 类.要实现管道中的各个阶段,您只需创建一个以'(class. To implement stages in a pipeline, you just need to create a .NET assembly that starts with ‘) ClassifyBot 并从您的主程序中引用该项目或程序集. ClassifyBot将在运行时从程序集中发现并加载适当的类型. ClassifierBot随附一个(’ and reference that project or assembly from your main program. ClassifyBot will discover and load the appropriate types from your assemblies at runtime. ClassifierBot ships with a) ConsoleDriver 您可以用来轻松地从程序中启动ML管道的类,例如(class you can use to easily start the ML pipeline from your program, e.g.)
class Program
{
static void Main(string[] args) => ConsoleDriver.RunAndExit(args);
}
是在.NET控制台程序中使用ClassifyBot所需的全部.最终,将添加其他驱动程序以允许从不同的用户界面(如ASP.NET Web应用程序)执行管道.(is all that is needed to use ClassifyBot in your .NET console program. Eventually, other drivers will be added to allow executing pipelines from different user interfaces like ASP.NET web apps.)
学习本质上是一个反复试验的过程,因此拥有一个可以减少在数据上重复类似操作的摩擦和精力的过程可能会非常有益. ClassifyBot处理ML管道中的常见操作,例如解析命令行参数,记录,计时,从Internet下载和提取压缩的存档数据文件,以及读取和写入XML,JSON和CSV等常见数据格式.最终,ClassifyBot将合并诸如(Learning is inherently a trial-and-error process so having a process in place that can reduced the friction and effort of repeating similar operations on data can be very beneficial. ClassifyBot takes care of the common operations in a ML pipeline like parsing command-line parameters, logging, timing, downloading and extracting compressed archive data files from the internet, and reading and writing common data formats like XML and JSON and CSV. Eventually, ClassifyBot will incorporate ontologies like) 墨西哥(MEX) 用于自动创建描述ML管道的每个阶段的元数据. ClassifyBot的长期目标是用来实现(for automatically creating metadata that describes each stage of a ML pipeline. A long-term goal for ClassifyBot is to be used to implement) 可复制的(reproducible) 和(and) 可存档的(archivable) ML实验并成为元数据的自动生成者,例如(ML experiments and be a automatic producer of metadata like) PMML(PMML) .(.)
背景(Background)
为什么要编写自己的管道?(Why Code Your Own Pipeline?)
有很多商业托管产品,例如(There are a lot of commercial hosted products like) 亚马逊机器学习(Amazon Machine Learning) ,(,) 猴子学习(MonkeyLearn) ,(,) Azure ML Studio(Azure ML Studio) 等等,您可以使用GUI创建ML工作流和管道.建立自己的管道似乎是很多不必要的工作,但与使用预先安装的解决方案相比,它实际上具有很多优点:(et.al that let you create ML workflows and pipelines using a GUI. Building your own pipeline may seem like a lot of unnecessary effort, but it actually has a lot of advantages over using pre-canned solutions:)
- 使用所需的ML库和工具.(Use the ML libraries and tools you want.)使用商业托管的ML工作流解决方案意味着您在选择可以使用的技术和工具方面受到限制.商业ML解决方案通常会提供易用性,这是您应该为其服务付费的原因,通常这意味着必须使用他们基于其解决方案构建的任何框架或库.大多数预构建的ML产品不允许您利用当今可用的高质量开放源代码ML库,框架和工具的数量激增.使用ClassifyBot,您可以使用任何您选择的开源MLP或ML组件来构建管道:Mallet,Vowpal Wabbit,Apache MXNet,Scikit-Learn,spaCy等.(Using a commercial hosted ML workflow solution means that you are limited in the choice of technologies and tools that you can use. Commercial ML solutions often offer ease-of-use as a reason you should pay for their services which usually translates into having to use whatever framework or libraries they have built their solution on. Most pre-built ML products don’t allow you to take advantage of the huge explosion in the number of high-quality open-source ML libraries, frameworks and tools available today. With ClassifyBot, you can build pipelines using any open-source MLP or ML component you choose: Mallet, Vowpal Wabbit, Apache MXNet, Scikit-Learn, spaCy,…whatever you want.)
- 使用您要编码的ML语言(Use the ML language you want to code in). ClassifyBot无法确定在管道阶段中特定操作的实际实现语言.只要您可以通过嵌入式解释器,外部命令行或REST API或来自的其他类型的IPC或RPC互操作来调用所需的代码即可. NET,您可以为其编写管道阶段接口.您可以在管道中使用现有的代码或混合匹配的语言和技术,而不必局限于Python,R或Java等特定语言.(. ClassifyBot is agnostic about what language a particular operation in a pipeline stage is actually implemented in. As long as you can call the desired code via an embedded interpreter or external command-lines or REST APIs or some other kind of IPC or RPC interop from .NET, you can write a pipeline stage interface for it. You can use your existing code or mix-and-match languages and tech in your pipeline however you want without being constrained to a particular language like Python or R or Java.)
- 简单的版本控制和应用程序生命周期管理(Straightforward version control and Application Lifecycle Management).使用诸如Azure ML Studio之类的GUI工具创建的ML工作流通常具有一个整体(. ML workflows created using GUI tools like Azure ML Studio usually have a whole) 分离(separate) 您必须了解(并担心)版本控制和ALM流程.使用ClassifyBot实现的ML项目只是.NET项目和解决方案中的.NET代码.您可以像其他.NET项目一样对ML项目进行版本控制.您可以使用NuGet来管理依赖项,并将ML pipleline阶段组织到单独的程序包中,就像处理其他.NET项目一样,然后可以将其分发给其他开发人员或在CI管道中进行测试和部署.(version-control and ALM process you have to understand (and worry about). An ML project implemented using ClassifyBot is just .NET code in a .NET project and solution. You can version-control your ML project just as you would your other .NET projects. You can use NuGet to manage your dependencies and organize your ML pipleline stages into separate packages just as you do with other .NET projects, that can then be distributed to other developers or tested and deployed in a CI pipeline.)
- 可扩展性(Extensibility).您可以无缝扩展管道,以添加其他步骤,例如注释或可视化或在DevOps环境中进行部署.将来,您将能够使用ClassifyBot将ML管道公开为ASP.NET Core Web App或Web Service.您可以在自己的ML管道中实现任何模式,例如主动学习.(. You can extend your pipeline seamlessly to add other steps like annotation or visualization or deployment in a DevOps environment. In the future, you will be able to use ClassifyBot to expose your ML pipelines as an ASP.NET Core Web App or Web Service. You can implement any pattern, like Active Learning, in your ML pipeline that you want.)
- 学习东西(Learn stuff).机器学习是一个永无止境的有趣主题,学习不同的工具和库如何工作以及可以组合起来解决ML问题是从大量可用资源中吸收知识的绝佳方法.我最初创建ClassifyBot是为了扩展和归纳我为客户所做的一些分类工作,尽管我仍然是ML新手,但在开发它的时间中,我学到了很多有关ML的知识.使用预装的解决方案将限制您将学习的内容仅限于提供商选择的任何工具和技术.(. Machine Learning is an endlessly fascinating subject and learning how different tools and libraries work and can be put together to solve a ML problem is a terrific way to absorb knowledge from the vast number of resources available. I originally started ClassifyBot as a way to extend and generalize some classification work I did for a client, and although I’m still a ML novice, in the time spent developing it I’ve learnt a lot about ML . Using a pre-canned solution limits the kind of learning you will do to whatever tools and tech the provider chooses.)
问题(The Problem)
我们将为最近结束的CodeProject解决语言检测问题(We’re going to solve the language detection problem for the recently concluded CodeProject) 机器学习和AI挑战.(Machine Learning and AI Challenge.) 基本挑战是,在给定一堆现有示例已使用正确语言标记的现有示例的情况下,准确检测短文本示例的编程语言.这是一个典型的文本分类问题,其中存在一个类或标签(编程语言),可以为其分配多个值,例如" C#“或” Python"或" JavaScript".我们可以使用机器学习分类器来识别编程语言,但是首先我们需要从CodeProject网站上托管的存档文件中提取数据,然后必须从给定的编程语言示例中提取或设计功能.(The basic challenge is to accurately detect the programming language of a short text sample, given a bunch of existing samples that have been tagged with the correct language. This is a typical text classification problem where there is one class or label – the programming language – which can be assigned multiple values like “C#” or “Python” or “JavaScript”. We can use a machine learning classifier to identify the programming language, but first we need to extract the data from an archive file hosted on the CodeProject website, and then we must extract or engineer features from the given programming language sample.)
我们可以识别出至少四个阶段来解决问题:(There are at least 4 stages for solving the problem we can identify:)
提取(Extract):数据文件位于CodeProject URL上,因此我们需要下载文件并将其解压缩,根据特定格式从文件中读取文本数据,然后提取各个数据项.如果我们以可移植的形式保存提取的数据,则此阶段仅需要一次,因为管道的其余部分将根据提取的数据工作.(: The data file is located at a CodeProject URL, so we need to download the file and unzip it, read the text data from the file according to the specific format, and then extract the individual data items. If we save the extracted data in a portable form then this stage will only needed once as the rest of the pipeline will work off of the extracted data.)
转变(Transform):使用提取的数据,我们需要将其转换为适合构建分类模型的形式.我们既要确定语言样本的特征(可用作分类算法的输入),又要消除会对模型的准确性产生不利影响的无关数据或噪声.由于某些特征未在文本数据中明确给出,因此必须使用文本分析进行构建.(: With the extracted data, we need to transform it into a form suitable for building a classification model. We want to both identify features of a language sample that can be used as inputs into a classification algorithm and also to remove extraneous data or noise that will adversely affect the accuracy of our model. Some features will have to be constructed using text analysis as they are not explicitly given in the text data.)
加载(Load):对于模型的初始训练,我们需要将数据分为两个子集:训练集和测试集,并以正确的格式为我们要使用的分类器库创建输入数据文件.我们也可以使用类似的技术(: For the initial training of our model, we need to split the data into 2 subsets: a training set and test set and create input data files in the correct format for the classifier library we want to use. We can also use techniques like)ķ(k)–(-)交叉折叠(fold cross)–(-)**验证(validation)**数据分为k折,其中一折用于验证其他k-1折.(where the data is split into k folds and one fold is used for validating the other k - 1 folds.)
培养(Train):我们需要使用训练和测试数据集来训练分类器,并测量模型的估计准确性.我们可以调整很多参数来定义模型的构建方式,我们希望有一种简单的方法来评估不同参数如何影响模型的准确性.(: We need to train the classifier using the training and test datasets and measure the estimated accuracy of our model. There are lots of parameters we can tweak defining how our model is built and we’d like an easy way to evaluate how different parameters affect the accuracy of the model.)
建造(Building)
数据(Data)
CodeProject提供的培训数据如下所示:(The training data provided by CodeProject looks like this:)
<pre lang="Swift">
@objc func handleTap(sender: UITapGestureRecognizer) {
if let tappedSceneView = sender.view as? ARSCNView {
let tapLocationInView = sender.location(in: tappedSceneView)
let planeHitTest = tappedSceneView.hitTest(tapLocationInView,
types: .existingPlaneUsingExtent)
if !planeHitTest.isEmpty {
addFurniture(hitTest: planeHitTest)
}
}
}</pre>
<pre lang="Python">
# Import `tensorflow` and `pandas`
import tensorflow as tf
import pandas as pd
COLUMN_NAMES = [
'SepalLength',
'SepalWidth',
'PetalLength',
'PetalWidth',
'Species'
]
# Import training dataset
training_dataset = pd.read_csv('iris_training.csv', names=COLUMN_NAMES, header=0)
train_x = training_dataset.iloc[:, 0:4]
train_y = training_dataset.iloc[:, 4]
# Import testing dataset
test_dataset = pd.read_csv('iris_test.csv', names=COLUMN_NAMES, header=0)
test_x = test_dataset.iloc[:, 0:4]
test_y = test_dataset.iloc[:, 4]</pre>
<pre lang="Javascript">
var my_dataset = [
{
id: "1",
text: "Chairman & CEO",
color: "#673AB7",
css: "myStyle",
},
{
id: "2",
text: "Manager",
color: "#E91E63"
},
...
]</pre>
<pre lang="C#">
public class AppIntents_Droid : IAppIntents
{
public void HandleWebviewUri(string uri)
{
var appUri = Android.Net.Uri.Parse(uri);
var appIntent = new Intent(Intent.ActionView, appUri);
Application.Context.StartActivity(appIntent);
}
}</pre>
每种语言的示例都在HTML中(Each language sample is in an HTML) `` 语言名称为的元素(element that has the name of the language as the) lang 属性.(attribute.)
从逻辑上讲,我们将处理的数据项包含一个(Logically, the data items we will work on consist of a single) string 表示源代码语言名称的标签或类,以及源代码文本示例的一个或多个功能.我们将数据项建模为(label or class which represents the source code language name, and one or more features of the source code text sample. We’ll model a data item as the) LanguageItem 类:(class:)
public class LanguageItem : Record<string>
{
public LanguageItem(int lineNo, string languageName, string languageText) :
base(lineNo, languageName, languageText) {}
}
由于训练数据中没有提供ID属性,因此我们将使用行号.特定文本样本元素的开头作为ID,这将允许我们映射(Since there’s no ID attribute provided in the training data, we’ll use the line no. of the start of a particular text sample element as the ID, which will allow us to map) LanguageItem 返回原始数据.每(s back to the original data. Each) LanguageItem 源自于(derives from) Record<string> 并将有一个或多个(and will have one or more) string 要素,这是最通用的要素类型,可以表示数字和非数字可转换要素数据.(features, which is the most general feature type that can represent both numeric and non-numeric convertible feature data.)
提取(Extract)
的(The) 码(code) 整个语言样本数据提取器如下所示:(for the entire language samples data extractor is shown below:)
[Verb("langdata-extract", HelpText = "Download and extract language samples data
from https://www.codeproject.com/script/Contests/Uploads/1024/LanguageSamples.zip
into a common JSON format.")]
public class LanguageSamplesExtractor : WebFileExtractor<LanguageItem, string>
{
public LanguageSamplesExtractor() : base
("https://www.codeproject.com/script/Contests/Uploads/1024/LanguageSamples.zip") {}
[Option('u', "url", Required = false, Hidden = true)]
public override string InputFileUrl { get; set; }
protected override Func<FileExtractor<LanguageItem, string>,
StreamReader, Dictionary<string, object>, List<LanguageItem>> ReadRecordsFromFileStream
{ get; } = (e, r, options) =>
{
HtmlDocument doc = new HtmlDocument();
doc.Load(r);
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//pre");
L.Information("Got {0} language data items from file.", nodes.Count);
return nodes.Select(n => new LanguageItem(n.Line, n.Attributes["lang"].Value.StripUTF8BOM(),
n.InnerText.StripUTF8BOM())).ToList();
};
}
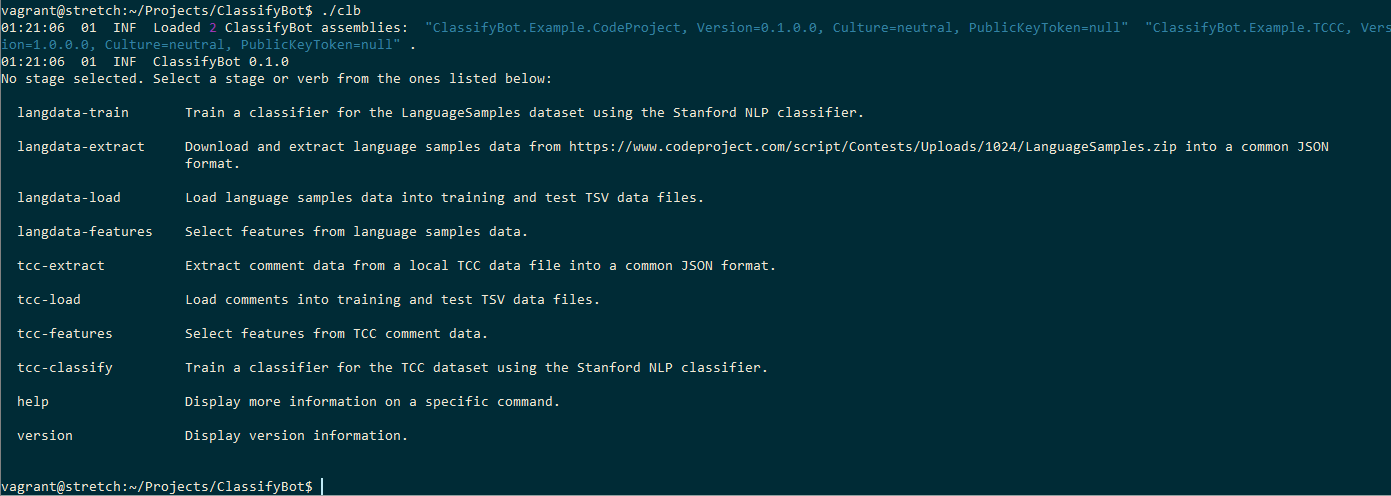
它相对简单而简短:首先,我们从基础中得出(It’s relatively simple and short: first, we derive from the base) WebFileExtractor 使用我们的课程(class using our) LanguageItem 输入为记录类型,然后(type as the record type and) string 作为要素类型.我们将URL传递给构造函数中的CodeProject数据文件,以(as the feature type. We pass the URL to the CodeProject data file in the constructor to) WebFileExtractor .由于我们不要求用户指定文件的URL,因此我们覆盖了(. Since we are not asking the user to specify a URL to the file we override the) InputFileUrl 属性,以隐藏此特定参数作为向用户提供的选项.我们装饰(property to hide presenting this particular parameter as an option to the user. We decorate the) LanguageSamplesExtractor 与类(class with the) Verb 属性,指示用于从CLI实例化此阶段的命令行动词.从控制台运行ClassifiyBot时,您将在帮助屏幕中看到此动词以及其他类定义的阶段的其他动词:(attribute to indicate the command-line verb to use to instantiate this stage from the CLI. When you run ClassifiyBot from the console, you will see this verb in the help screen along with other verbs for stages defined by other classes:)
最后,我们覆盖(Finally, we override the) ReadFileStream lambda函数指定我们如何从数据文件流中提取数据.我们将使用HTML Agility Pack .NET库来解析输入的HTML文档并选择每个(lambda function to specify how we will extract the data from the data file stream. We will use the HTML Agility Pack .NET library to parse the input HTML document and select each) `` 包含语言样本的元素,然后我们将其构造为(element that contains a language sample which we then construct as a) LanguageItem .一些分类器对文本中是否存在UTF-8字节顺序标记(BOM)敏感,因此我们将这些字符剔除掉.您可以在此提取阶段添加提取的数据所需的任何必要的数据清理操作.有了这段代码,我们现在有了一个完整的ClassifyBot阶段,可以从ClassifyBot CLI调用它:(. Some classifiers are sensitive to the presence of a UTF-8 Byte Order Mark (BOM) in text so we strip these characters out. You can add any necessary data scrubbing operations your extracted data needs during this extract stage. With this code, we now have a complete ClassifyBot stage we can call from the ClassifyBot CLI:)

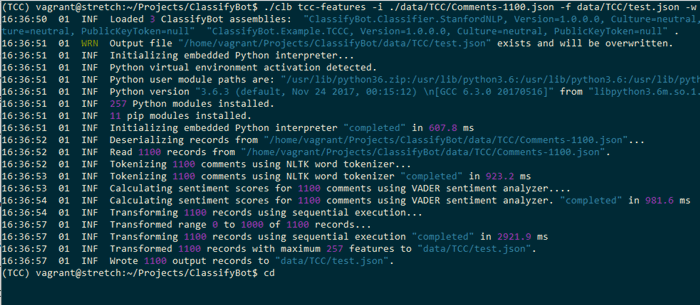
当…的时候(When the) langdata-extract 阶段被调用,文件被下载,解压缩并将数据提取为可存储在磁盘上的可移植JSON格式.当存储的JSON使用gzip压缩时,(stage is called, the file is downloaded, unzipped and the data extracted into a portable JSON format that is stored on-disk. This JSON stored is compressed with gzip when the) -c 指定了选项. ClassifyBot假定任何具有扩展名的文件(option is specified. ClassifyBot assumes any file that has the extension)**.gz(.gz)**被压缩并透明地读取压缩的流.现在,可以将该JSON文件用作后面任何阶段的输入.提取阶段生成的JSON如下所示:(is compressed and reads the compressed stream transparently. This JSON file can now be used as input to any of the latter stages. The JSON produced by the extract stage looks like this:)
[
...
{
"_Id": 121,
"Id": null,
"Labels": [
{
"Item1": "C#",
"Item2": 1.0
}
],
"Features": [
{
"Item1": "TEXT",
"Item2": "\r\n public class AppIntents_Droid : IAppIntents\r\n
{\r\n public void HandleWebviewUri(string uri)\r\n
{\r\n var appUri = Android.Net.Uri.Parse(uri);\r\n
var appIntent = new Intent(Intent.ActionView, appUri);\r\n
Application.Context.StartActivity(appIntent);\r\n }\r\n }"
}
]
},
{
"_Id": 133,
"Id": null,
"Labels": [
{
"Item1": "Python",
"Item2": 1.0
}
],
"Features": [
{
"Item1": "TEXT",
"Item2": "\r\n# Import `tensorflow` and `pandas`\r\nimport tensorflow as
tf\r\nimport pandas as pd\r\n\r\nCOLUMN_NAMES = [\r\n
'SepalLength', \r\n 'SepalWidth',\r\n
'PetalLength', \r\n 'PetalWidth', \r\n
'Species'\r\n
]\r\n\r\n# Import training dataset\r\ntraining_dataset = pd.read_csv
('iris_training.csv', names=COLUMN_NAMES, header=0)\r\ntrain_x =
training_dataset.iloc[:, 0:4]\r\ntrain_y = training_dataset.iloc[:, 4]\r\n\r\n#
Import testing dataset\r\ntest_dataset = pd.read_csv('iris_test.csv',
names=COLUMN_NAMES, header=0)\r\ntest_x = test_dataset.iloc[:,
0:4]\r\ntest_y = test_dataset.iloc[:, 4]"
}
]
},
{
"_Id": 28,
"Id": null,
"Labels": [
{
"Item1": "JavaScript",
"Item2": 1.0
}
],
"Features": [
{
"Item1": "TEXT",
"Item2": "\r\nvar my_dataset = [\r\n {\r\n id: \"1\",\r\n
text: \"Chairman & CEO\",\r\n title: \"Henry Bennett\"\r\n },\r\n
{\r\n id: \"2\",\r\n text: \"Manager\",\r\n
title: \"Mildred Kim\"\r\n },\r\n {\r\n id: \"3\",\r\n
text: \"Technical Director\",\r\n title: \"Jerry Wagner\"\r\n },\r\n
{ id: \"1-2\", from: \"1\", to: \"2\", type: \"line\" },\r\n
{ id: \"1-3\", from: \"1\", to: \"3\", type: \"line\" }\r\n];"
}
]
},
您无需编写任何代码即可下载或解压缩或将提取的数据另存为JSON,因为基础已经完成了此操作(You don’t have to write any code to download or unzip or save the extracted data as JSON as this is already done by the base) WebileExtractor 类我们的(class that our) LanguageSamplesExtractor 类继承自.每个语言样本最初都有1个标签或类(仅是文本所使用的语言)和1个功能(仅是语言文本本身).现在,该数据已准备好由Transform阶段处理,该阶段将提取并构造其他功能.(class inherits from. Each language sample initially has 1 label or class which is just the language the text is in, and 1 feature that is just the language text itself. This data is now ready to be processed by a Transform stage which will extract and construct additional features.)
转变(Transform)
在"转换"阶段,我们选择或设计文本的功能,这些功能将作为分类器的输入.我们希望识别语言样本的特征,以帮助识别所使用的语言,同时删除那些不会使用的元素.以常见的重复方式(如JSON)布置数据有助于比较和识别过程,仅通过查看数据,我们就可以猜测应该如何进行.(The Transform phase is where we select or engineer the features of our text that will be the input to our classifier. We want to identity characteristics of a language sample that can help identify the language being used while also removing those elements that will not. Having the data laid out in a common repeating way like our JSON aids the comparison and identification process and just by eyeballing the data we can make some guesses as to how we should proceed.)
我们应该做的第一件事是从语言示例文本中删除所有字符串文字.这些字符串文字是特定于正在创建的程序的,而不是特定于所使用的语言的,仅充当噪音,会降低我们模型的准确性.(The first thing we should do is remove all string literals from the language sample text. These string literals are specific to the program being created, not the language being used, and only serve as noise that will decrease the accuracy of our model.)
要观察的第二件事是,编程语言文本的许多词汇或标记功能都是重要的,并且可以用作标识功能,而在分析自然语言时则不会如此.诸如JavaScript和C ++之类的某些语言使用分号作为行定界符,并使用花括号分隔代码块.像Python这样的其他语言则完全避免使用此类分隔符,而倾向于可读性. " C"系列的编程语言都具有某些词汇特征,例如使用(The second thing to observe is that many lexical or token features of the programming language text are significant and serve as identification features, which would not be the case in analyzing natural language. Some languages like JavaScript and C++ use a semi-colon as a line delimiter and curly-braces to delimit code blocks. Other languages like Python eschew such delimiters completely in favor of readability. Programming languages in the “C” family all share certain lexical characteristics like the use of)功能(function)和(and)类(class)关键字来声明函数,方法和类,并使用"//“进行注释.其他语言(例如Python和Objective-C)具有其他特征,例如使用诸如(keywords to declare functions and methods and classes, and the use of “//” for comments. Other languages like Python and Objective-C have other characteristics like the use of keywords like) def 要么(or) let 或使用”(or the use of the ‘) @ ‘属性符号或’(’ symbol for attributes or ‘) # ‘进行评论,而C系列语言通常不会提供评论.诸如XML和HTML之类的标记语言依赖于用尖括号分隔的元素.像React这样的混合语言也将这些元素与JavaScript的功能混合在一起.但是,文本分类器库并未考虑许多自然识别的词汇特征,这些分类器库主要查看类似于单词的文本中的语言术语.像"(’ for comments, which C-family languages usually don’t. Markup languages like XML and HTML rely on elements delimited by angled-brackets; hybrid languages like React will also have these kinds of elements mixed with features from JavaScript. But many of these naturally identifying lexical features aren’t considered so by text classifier libraries which mainly look at language terms in the text that are word-like. Symbols like ‘) : ‘就像标点符号一样对待,在分类器将应用于文本的标记化阶段可能会被完全忽略.所有这些功能都必须从给定的语言样本中构建,以便分类器将它们识别为重要的.(’ are treated like punctuation and may be ignored all-together during the tokenization phase that the classifier will apply to the text. All these features must be constructed from a given language sample so that the classifier recognizes them as significant.)
我们创建一个(We create a) 类(class) 从(that derives from) Transformer<LanguageItem, string> 和(and) `` 添加(add the) Verb 指示此阶段的选项将使用以下命令从CLI调用(option to indicate this stage will be invoked from the CLI with the) langdata-features 动词(verb).(.)
[Verb("langdata-features", HelpText = "Select features from language samples data.")]
public class LanguageSamplesSelectFeatures : Transformer<LanguageItem, string>
{
protected override Func<Transformer<LanguageItem, string>,
Dictionary<string, object>, LanguageItem, LanguageItem>
TransformInputToOutput { get; } = (l, options, input) =>
{
string text = input.Features[0].Item2.Trim();
...
};
protected override StageResult Init()
{
if (!Success(base.Init(), out StageResult r)) return r;
FeatureMap.Add(0, "TEXT");
FeatureMap.Add(1, "LEXICAL");
FeatureMap.Add(2, "SYNTACTIC");
return StageResult.SUCCESS;
}
protected override StageResult Cleanup() => StageResult.SUCCESS;
我们覆盖(We override the) TransformInputToOutput 详细说明如何处理每种语言示例文本的方法.我们的语言样本功能可以分为词汇和句法等类别,因此我们将其添加到阶段的(method to detail how the text of each language sample will be processed. Our language sample features can be grouped into categories like lexical and syntactic so we add those to the stage’s) FeatureMap 字典.在此阶段,我们没有任何要清除的中间文件或资源,因此我们只是忽略了(dictionary. We don’t have any intermediary files or resources to clean up in this stage, so we just ignore the) Cleanup 现在的方法.让我们看一下我们的实现(method for now. Let’s look at our implementation of) TransformInputToOutput .首先,我们删除任何(. First, we remove any) string 使用正则表达式的文字:(literals using regular expressions:)
Regex doubleQuote = new Regex("\\\".*?\\\"", RegexOptions.Compiled);
Regex singleQuote = new Regex("\\\'.*?\\\'", RegexOptions.Compiled);
text = singleQuote.Replace
(text, new MatchEvaluator(ReplaceStringLiteral)); //Remove any quote string literals
text = doubleQuote.Replace
(text, new MatchEvaluator(ReplaceStringLiteral)); //Remove any doublequote string literals
然后,我们使用正则表达式挑选出可以识别所用语言的令牌,并将表示这些令牌的标识符添加到"(Then, we use regular expressions to pick out tokens that are identifying for the language being used and add identifiers representing those tokens to the “) LEXICAL “功能类别:(” feature category:)
string lexicalFeature = string.Empty;
Regex semiColon = new Regex(";\\s*$", RegexOptions.Compiled | RegexOptions.Multiline);
Regex curlyBrace = new Regex("\\{\\s*$", RegexOptions.Compiled | RegexOptions.Multiline);
Regex at = new Regex("^\\s*\\@\\w+?", RegexOptions.Compiled | RegexOptions.Multiline);
Regex hashComment = new Regex("#.*$", RegexOptions.Compiled | RegexOptions.Multiline);
Regex doubleSlashComment = new Regex("\\/\\/\\s*\\.*?$",
RegexOptions.Compiled | RegexOptions.Multiline);
Regex markupElement = new Regex("<\\/\\w+>", RegexOptions.Compiled);
if (hashComment.IsMatch(text))
{
lexicalFeature += "HASH_COMMENT" + " ";
text = hashComment.Replace(text, new MatchEvaluator(ReplaceStringLiteral));
}
else if (doubleSlashComment.IsMatch(text))
{
lexicalFeature += "DOUBLESLASH_COMMENT" + " ";
text = doubleSlashComment.Replace(text, new MatchEvaluator(ReplaceStringLiteral));
}
if (semiColon.IsMatch(text))
{
lexicalFeature += "SEMICOLON" + " ";
}
if (curlyBrace.IsMatch(text))
{
lexicalFeature += "CURLY_BRACE" + " ";
}
if (markupElement.IsMatch(text))
{
lexicalFeature += "MARKUP" + " ";
}
if (at.IsMatch(text))
{
lexicalFeature += "AT" + " ";
}
LanguageItem output = new LanguageItem(input._Id.Value, input.Labels[0].Item1, text);
output.Features.Add(("LEXICAL", lexicalFeature.Trim()));
return output;
这将在每个输入行上运行,并产生一个输出行,该行将保存在输出文件中.现在,我们有了可以从CLI运行的功能类的第一个实现:(This will run on each input row and produce an output row that will be saved in the output file. Now we have a first implementation of our features class that we can run from the CLI:)

我们将转换后的数据写入一个名为的新JSON文件中(We write the transformed data to a new JSON file called)LanguageSamplesWithFeatures.json(LanguageSamplesWithFeatures.json).现在,数据如下所示:(. The data now looks like this:)
[
{
"_Id": 1,
"Id": null,
"Labels": [
{
"Item1": "XML",
"Item2": 1.0
}
],
"Features": [
{
"Item1": "TEXT",
"Item2": "<?xml version=?>\r\n<DevelopmentStorage xmlns:xsd= xmlns:xsi= version=>\r\n
<SQLInstance>(localdb)\\v11.0</SQLInstance>\r\n
<PageBlobRoot>C:\\Users\\Carl\\AppData\\Local\\DevelopmentStorage\\PageBlobRoot
</PageBlobRoot>\r\n
<BlockBlobRoot>C:\\Users\\Carl\\AppData\\Local\\DevelopmentStorage\\BlockBlobRoot
</BlockBlobRoot>\r\n <LogPath>C:\\Users\\Carl\\AppData\\Local\\DevelopmentStorage\\Logs
</LogPath>\r\n <LoggingEnabled>false</LoggingEnabled>\r\n</DevelopmentStorage>"
},
{
"Item1": "LEXICAL",
"Item2": "MARKUP"
}
]
},
{
"_Id": 13,
"Id": null,
"Labels": [
{
"Item1": "Swift",
"Item2": 1.0
}
],
"Features": [
{
"Item1": "TEXT",
"Item2": "@objc func handleTap(sender: UITapGestureRecognizer)
{\r\n if let tappedSceneView = sender.view as? ARSCNView {\r\n
let tapLocationInView = sender.location(in: tappedSceneView)\r\n
let planeHitTest = tappedSceneView.hitTest(tapLocationInView,\r\n
types: .existingPlaneUsingExtent)\r\n
if !planeHitTest.isEmpty {\r\n
addFurniture(hitTest: planeHitTest)\r\n }\r\n }\r\n}"
},
{
"Item1": "LEXICAL",
"Item2": "CURLY_BRACE AT"
}
]
},
{
"_Id": 28,
"Id": null,
"Labels": [
{
"Item1": "JavaScript",
"Item2": 1.0
}
],
"Features": [
{
"Item1": "TEXT",
"Item2": "var my_dataset = [\r\n {\r\n id: ,\r\n text: ,\r\n
title: \r\n },\r\n {\r\n id: ,\r\n text: ,\r\n
title: \r\n },\r\n {\r\n id: ,\r\n text: ,\r\n
title: \r\n },\r\n { id: , from: , to: , type: },\r\n
{ id: , from: , to: , type: }\r\n];"
},
{
"Item1": "LEXICAL",
"Item2": "SEMICOLON CURLY_BRACE"
}
]
语言样本的某些识别词汇特征已被突出显示.转换后的输出数据的JSON格式与输入数据相同.每个ClassifyBot转换器都产生相同的JSON格式,因此转换阶段可以彼此链接,其中一个的输出文件用作另一个的输入.(Some of the identifying lexical features of the language sample have been highlighted. The JSON format of the transformed output data remains the same as the input data. ClassifyBot transformers each produce the same JSON format so that transformation stages can be chained to each other with the output file of one serving as the input to another.)
我们可以添加更多的词汇功能,以及一些语法功能,例如使用关键字的变量赋值(There are lots more lexical features we could add plus some syntactic features, like variable assignments using the keyword) let ,即(, i.e.,)"(") let xx = yyy “.但是,让我们首先使用现有功能来查看分类器的性能.(”. But let’s first take a look at the performance of our classifier using the features we have now.)
加载(Load)
我们将使用(We will use the) 斯坦福分类器(Stanford Classifier) 这是一个用Java编写的ML库,专门用于文本分类.我们必须对来自我们正在使用的可移植JSON的数据进行最终转换,将其转换为特定于我们将使用的分类器的格式,然后将数据分成2个数据集.大多数分类器(例如斯坦福分类器)都接受CSV格式的文件,因此我们可以使用(which is an ML library written in Java that specializes in text classification. We must do a final transformation of the data from the portable JSON we have been working with into a format specific to the classifier we will be using, and split the data into 2 datasets. Most classifiers like Stanford Classifier accept CSV format files so we can use the) LoadToCsvFile Load阶段的基类.这是我们的代码(base class for our Load stage. Here is the code for our) Load 阶段:(stage:)
[Verb("langdata-load", HelpText =
"Load language samples data into training and test TSV data files.")]
public class LanguageSamplesLoader : LoadToCsvFile<LanguageItem, string>
{
#region Constructors
public LanguageSamplesLoad() : base("\t") {}
#endregion
}
该代码遵循其他阶段的模式.基地(The code follows the pattern of the other stages. The base) LoadToCsvFile 类和方法将处理读取和写入输入JSON和输出CSV文件的详细信息.我们只需要使用制表符作为分隔符来创建基类,因为这是斯坦福分类器接受的格式,并使用(class and methods will take care of the details of reading and writing the input JSON and output CSV files. We only need to create the base class using a tab character as the delimiter since this is the format that the Stanford Classifier accepts, and use the) Verb 属性以将此类公开为可通过CLI通过CLI调用的阶段(attribute to expose this class as a stage callable from the CLI with the) langdata-load 动词:(verb:)

加载阶段写入将输入数据集拆分为训练和测试数据集.默认情况下,80%的可用数据进入训练数据集,但是您可以使用(The load stage writes splits the input dataset into a train and test dataset. By default, 80% of the available data goes into the train dataset but you can specify what the split is using the)**** -s 选项.默认情况下,仅完成确定性拆分,这意味着对于每次加载阶段,都将相同的记录分配给2个子集中的每个子集.但是随机分配训练和测试(*option. By default, only deterministic splitting is done meaning the same records will be assigned to each of the 2 subsets for every invocation of the load stage. But random assignments to the train and test*) dataset 而其他任何需要的加载任务都可以通过覆盖(*and any others load tasks needed can easily be implemented by overriding the*) Load 基本方法(*method of the base*) LoadToCsv 类.(*class.*)
培养(Train)
我们现在有一个(We now have a) dataset 具有正确的功能和格式,可以输入分类器.我们用于分类器的数据采用TSV格式,如下所示:(with the right features and format that we can feed into our classifier. Our data for the classifier is in TSV format that looks like this:)
C++ // initializes a vector that holds the numbers from 0-9.
// std::vector<int> v = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 }; print(v);
// removes all elements with the value 5
// v.erase( std::remove( v.begin(), v.end(), 5 ), v.end() ); print(v);
// removes all odd numbers v.erase( std::remove_if(v.begin(), v.end(), is_odd), v.end() );
// print(v); SEMICOLON 9070
C++ namespace my { template<class BidirIt, class T>
BidirIt unstable_remove(BidirIt first, BidirIt last, const T& value)
{ while (true) { // Find the first instance of ...
// first = std::find(first, last, value);
// ...and the last instance of ...
//do { if (first == last)
//return last; --last; } while (*last == value);
// ...and move the latter over top of the former. *first = std::move(*last);
// Rinse and repeat. ++first; } }
// template<class BidirIt, class Pred>
// BidirIt unstable_remove_if(BidirIt first, BidirIt last, Pred predicate)
// { while (true) {
// Find the first instance of ... first = std::find_if(first, last, predicate);
// ...and the last instance of ... do {
// if (first == last) return last; --last; }
// while (predicate(*last)); // ...and move the latter over top of the former.
// *first = std::move(*last); // Rinse and repeat. ++first; } }}
// namespace my SEMICOLON CURLY_BRACE 9084
C++ // initializes a vector that holds the numbers from 0-9.
// std::vector<int> v = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 }; print(v);
// removes all elements with the value 5 v.erase( my::unstable_remove( v.begin(),
// v.end(), 5 ), v.end() ); print(v);
// removes all odd numbers v.erase( my::unstable_remove_if(v.begin(), v.end(), is_odd),
// v.end() ); print(v); SEMICOLON 9132
PYTHON class Meta(type): @property def RO(self):
return 13class DefinitionSet(Meta(str(), (), {})):
greetings = myNameFormat = durationSeconds = 3.5
color = { : 0.7, : 400 } @property def RO(self):
return 14 def __init__(self): self.greetings =
self.myNameFormat = self.durationSeconds = 3.6
self.color = { : 0.8, : 410 }instance = DefinitionSet() HASH_COMMENT AT 9146
PYTHON class DefinitionSet: def __init__(self):
self.greetings = self.myNameFormat = self.durationSeconds = 3.5
self.color = { : 0.7, : 400 }definitionSet = DefinitionSet()print (definitionSet.durationSeconds)
HASH_COMMENT 9171
XML <MediaPlayerElement Width= Height=> <i:Interaction.Behaviors>
<behaviors:SetMediaSourceBehavior SourceFile= />
<behaviors:InjectMediaPlayerBehavior MediaPlayerInjector=/>
</i:Interaction.Behaviors></MediaPlayerElement> MARKUP 9484
C# public class MediaPlayerViewModel : ViewModel{
private readonly IMediaPlayerAdapter mediaPlayerAdapter;
public MediaPlayerViewModel(IMediaPlayerAdapter mediaPlayerAdapter)
{ this.mediaPlayerAdapter = mediaPlayerAdapter; }
public IMediaPlayerAdapter MediaPlayerAdapter {
get { return mediaPlayerAdapter; } }} SEMICOLON CURLY_BRACE 9493
C# // get default implementation of IPerson
// interface containing only properties// the default property implementation
// is the auto propertyIPerson person = Core.Concretize<IPerson>();person.FirstName = ;
// person.LastName = ;person.Age = 35;person.Profession = ;
// test that the properties have indeed been assigned. Console.WriteLine($"Name=;
// Age=; Profession="); SEMICOLON 9510
C# public class Person_Concretization : NoClass, IPerson, NoInterface
{ public static Core TheCore { get; set; } public Person_Concretization () { }
public string FirstName { get; set; } public string LastName
{ get; set; } public int Age { get; set; }
public string Profession { get; set; } }
HASH_COMMENT SEMICOLON CURLY_BRACE 9530
REACT class ListBox extends React.Component { render()
{ return ( <div className=>
<select onChange={this.OnChange.bind(this)} ref=>
<option value= disabled selected hidden>{this.props.placeholder}</option>
{this.props.Items.map((item, i) =>
<ListBoxItem Item={{ : item[this.textPropertyName],
: item[this.valuePropertyName] }} />)}
</select>
</div> ); } }
SEMICOLON CURLY_BRACE MARKUP 9668
REACT class ListBoxItem extends React.Component { render()
{ return (
<option key={this.props.Item.Value}
value={this.props.Item.Value}>{this.props.Item.Text}</option>
); } } SEMICOLON CURLY_BRACE MARKUP 9687
XML <ListBox Items={this.state.carMakes} valuePropertyName=
selectedValue={this.state.selectedMake} placeholder=
textPropertyName= OnSelect={this.OnCarMakeSelect} />
<ListBox Items={this.state.carModels} selectedValue={this.state.selectedModel}
placeholder= OnSelect={this.OnCarModelSelect} /> 9700
JAVASCRIPT OnCarMakeSelect(value, text) { /
this.setState({ selectedMake: value, carModels: GetCarModels(value), selectedModel: -1 }); }
OnCarModelSelect(value, text) { this.setState({ selectedModel: value }); }
SEMICOLON CURLY_BRACE 9714
第一列是文本的类或标签,第二列是语言示例文本本身,第三列包含我们从文本中提取的词汇特征.我们在训练阶段的实施使用(The first column is the class or label of the text, the next column is the language sample text itself, and the third column contains the lexical features we extracted from the text. Our implementation of the train stage uses the) StanfordNLPClassifier 类,它提供了基于Java的分类程序的命令行程序的接口:(class which provides an interface to the Java-based classifier’s command line program:)
[Verb("langdata-train", HelpText = "Train a classifier for the LanguageSamples
dataset using the Stanford NLP classifier.")]
public class LanguageDetectorClassifier : StanfordNLPClassifier<LanguageItem, string>
{
#region Overriden members
public override Dictionary<string, object> ClassifierProperties
{ get; } = new Dictionary<string, object>()
{
{"1.useSplitWords", true },
{"1.splitWordsRegexp", "\\\\s+" },
{"2.useSplitWords", true },
{"2.splitWordsRegexp", "\\\\s+" },
{"2.useAllSplitWordPairs", true },
};
#endregion
}
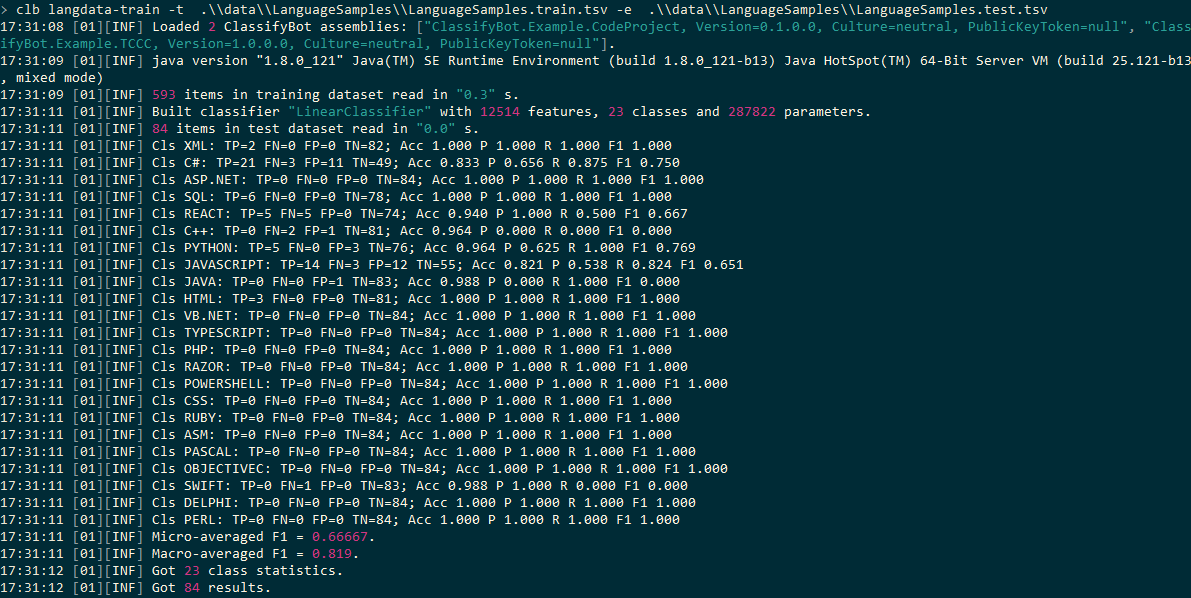
ClassifierProperties 包含特定于所使用分类器的选项. Stanford分类器采用一组特定于列的选项,这些选项具有零索引的列号作为前缀.所以我们在这里所说的是第1列(2(contains options that are specific to the classifier being used. The Stanford Classifier takes a set of column-specific options that have the zero-indexed column number as the prefix. So what we are saying here is that column 1 (2)nd(nd)列)和第2列(3(column) and column 2 (3)rd(rd)列)中的数据应该使用空格分割为多个单词.此外,包含词汇特征列表的第2列除单个单词外,还应分为单词对.诸如” SEMICOLON CURLY_BRACE"之类的词汇对对在识别文字所使用的语言方面很重要.我们可以使用很多分类器属性和参数,但让我们使用目前拥有的分类器属性和参数来进行分类运行:(column) of our datasets should be split into words using whitespace. Additionally, column 2 which contains the list of lexical features should be split into word pairs in addition to single words. Pairs of lexical features like “SEMICOLON CURLY_BRACE” are significant in identifying the language the text is written in. There are a lot of classifier properties and parameters we can play with but let’s use the ones we have for now and do a classification run:)
调(Tune)
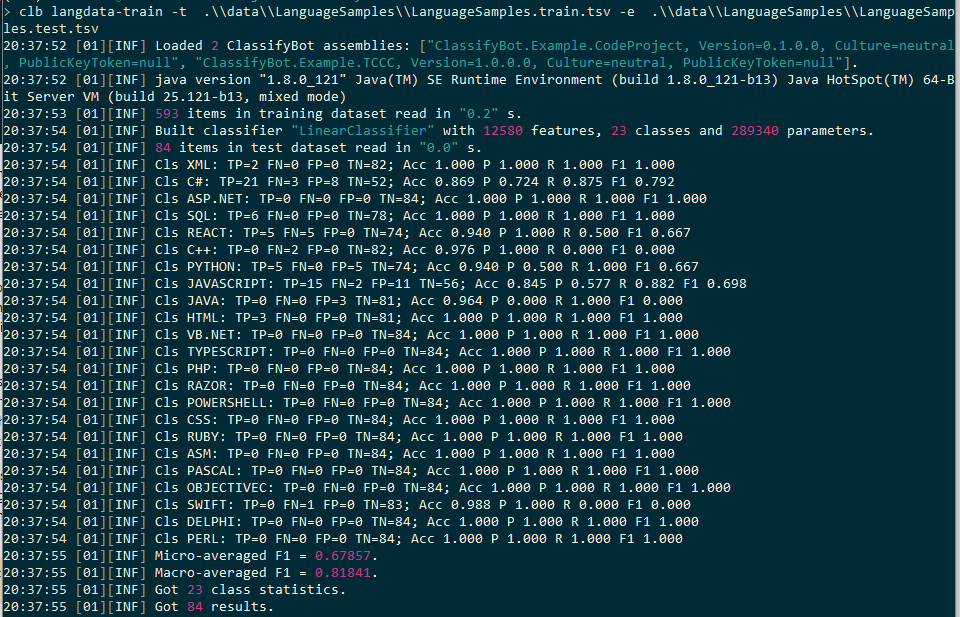
从最初的设置结果中,我们看到分类器能够在至少50%的测试数据项中正确分配语言标签或类.但是,存在很多错误识别的情况:错误肯定和错误否定.还有哪些其他的词汇或句法功能可以帮助您呢?(From the initial set results, we see that the classifier was able to correctly assign the language label or class in at least 50% of the test data items. However, there are a lot of cases of misidentification: both false positives and false negatives. What are some additional lexical or syntactic features that could help?)
特定顺序的标记组合对识别语言非常重要.我们知道,例如,Python依靠单个冒号并缩进来定义方法主体:(There are combinations of tokens in a particular order that are significant in identifying languages. We know that for instance, Python relies on a single colon and indent to define a method body:)
def RO(self):
C#允许您定义属性访问器,例如:(C# allows you to define property accessors like:)
X {get; set; }
诸如C#和C ++之类的语言包含适用于类和属性声明的访问修饰符:(Languages like C# and C++ contain access modifiers that apply to class and property declarations:)
public class X
我们还可以区分语言是如何声明类继承的.例如,React使用以下语法:(We also can distinguish in how a language declares class inheritance. React for instance uses the following syntax:)
class X extends Y
而C#使用如下语法:(while C# uses syntax like:)
class X : Y
Python的语法为:(Python’s syntax is:)
class X(Y)
一些语言利用(Some languages utilize the) let 变量声明和定义的关键字:(keyword for variable declaration and definition:)
let x = 500
这些功能可以归类为"(These features can be classified as “) SYNTACTIC “,因为它们与语言在词法分析阶段用来解析标记的规则有关.我们可以再次使用正则表达式来检测文本中的这些特征,并将特征标识符添加到”(” since they are about the rules that languages uses to parse tokens from the lexing stage. We can again use regular expressions to detect these features in the text and we’ll add feature identifiers to the “) SYNTACTIC “功能类别.我们将以下代码添加到功能阶段:(” feature category. We’ll add the following code to our features stage:)
//syntax features
string syntacticFeature = string.Empty;
Regex varDecl = new Regex("\\s*var\\s+\\S+\\s+\\=\\s\\S+",
RegexOptions.Compiled | RegexOptions.Multiline);
Regex letDef = new Regex("\\s*let\\s+\\w+\\s+\\=\\s\\w+",
RegexOptions.Compiled | RegexOptions.Multiline);
Regex defBlock = new Regex("^\\s*(def|for|try|while)\\s+\\S+\\s*\\:\\s*$",
RegexOptions.Compiled | RegexOptions.Multiline);
Regex propertyAccessor = new Regex("\\w+\\s+\\{get;", RegexOptions.Compiled);
Regex accessModifier = new Regex("^\\s*(public|private|protected|internal|friend)\\s+
\\w+?", RegexOptions.Compiled | RegexOptions.Multiline);
Regex classExtendsDecl = new Regex("^\\s*class\\s+\\S+\\s+\\extends\\s+\\w+",
RegexOptions.Compiled | RegexOptions.Multiline);
Regex classColonDecl = new Regex("\\s*class\\s+\\w+\\s*\\:\\s*\\w+",
RegexOptions.Compiled | RegexOptions.Multiline);//^\s*class\s+\w+\s*\(\w+\)
Regex classBracketsDecl = new Regex("^\\s*class\\s+\\w+\\s*\\(\\w+\\)",
RegexOptions.Compiled | RegexOptions.Multiline);
Regex fromImportDecl = new Regex("^\\s*from\\s+\\S+\\s+import\\s+\\w+?",
RegexOptions.Compiled | RegexOptions.Multiline);
Regex importAsDecl = new Regex("^\\s*import\\s+\\S+\\s+as\\s+\\w+?",
RegexOptions.Compiled | RegexOptions.Multiline);
Regex newKeywordDecl = new Regex("\\w+\\=\\s*new\\s+\\w+",
RegexOptions.Compiled);
Regex usingKeywordDecl = new Regex("^\\s*using\\s+\\w+?",
RegexOptions.Compiled | RegexOptions.Multiline);
if (varDecl.IsMatch(text))
{
syntacticFeature += "VAR_DECL" + " ";
}
if (letDef.IsMatch(text))
{
syntacticFeature += "LET_DEF" + " ";
}
if (defBlock.IsMatch(text))
{
syntacticFeature += "DEF_BLOCK" + " ";
}
if (accessModifier.IsMatch(text))
{
syntacticFeature += "ACCESS_MODIFIER" + " ";
}
if (propertyAccessor.IsMatch(text))
{
syntacticFeature += "PROP_DECL" + " ";
}
if (classExtendsDecl.IsMatch(text))
{
syntacticFeature += "CLASS_EXTENDS_DECL" + " ";
}
if (classColonDecl.IsMatch(text))
{
syntacticFeature += "CLASS_COLON_DECL" + " ";
}
if (classBracketsDecl.IsMatch(text))
{
syntacticFeature += "CLASS_BRACKETS_DECL" + " ";
}
if (fromImportDecl.IsMatch(text))
{
syntacticFeature += "FROM_IMPORT_DECL" + " ";
}
if (importAsDecl.IsMatch(text))
{
syntacticFeature += "IMPORT_AS_DECL" + " ";
}
if (newKeywordDecl.IsMatch(text))
{
syntacticFeature += "NEW_KEYWORD_DECL" + " ";
}
if (usingKeywordDecl.IsMatch(text))
{
syntacticFeature += "USING_KEYWORD_DECL" + " ";
}
我们还将添加一个选项,该选项允许我们使用或不使用语法功能来进行功能选择:(We’ll also add an option that allows us to do the feature selection with or without the syntax features:)```c# [Option(“with-syntax”, HelpText = “Extract syntax features from language sample.”, Required = false)] public bool WithSyntaxFeatures { get; set; }
现在,我们可以使用新的代码和选项来调用转换阶段:(*We can now invoke our transform stage with the new code and options:*)

我们还将在分类阶段添加一个参数,以启用斯坦福分类器的k折交叉验证功能:(*We'll also add a parameter to our classification stage to enable the k-fold cross-validation feature of the Stanford Classifier:*)
```c#
Option("with-kcross", HelpText = "Use k-fold cross-validation.", Required = false)]
public bool WithKFoldCrossValidation { get; set; }
并覆盖(and override the) Init() 指定时用于输入此参数的分类器方法:(method of the classifier to pull in this parameter when specified:)
protected override StageResult Init()
{
if (!Success(base.Init(), out StageResult r)) return r;
if (WithKFoldCrossValidation)
{
ClassifierProperties.Add("crossValidationFolds", 10);
Info("Using 10-fold cross validation");
}
return StageResult.SUCCESS;
}
我们设定折数(We set the number of folds) k 至(to) 10 .我们还可以使用整数参数来允许用户设置(. We could also have used an integer parameter to allow the user to set the value for) k 但(but) 10 现在是一个很好的默认值.现在,我们可以使用其他语法功能运行加载阶段,并使用10倍交叉验证再次运行训练阶段:(is a good default value for now. Now we can run our load stage with the additional syntactic features and run the train stage again using 10-fold cross validation:)
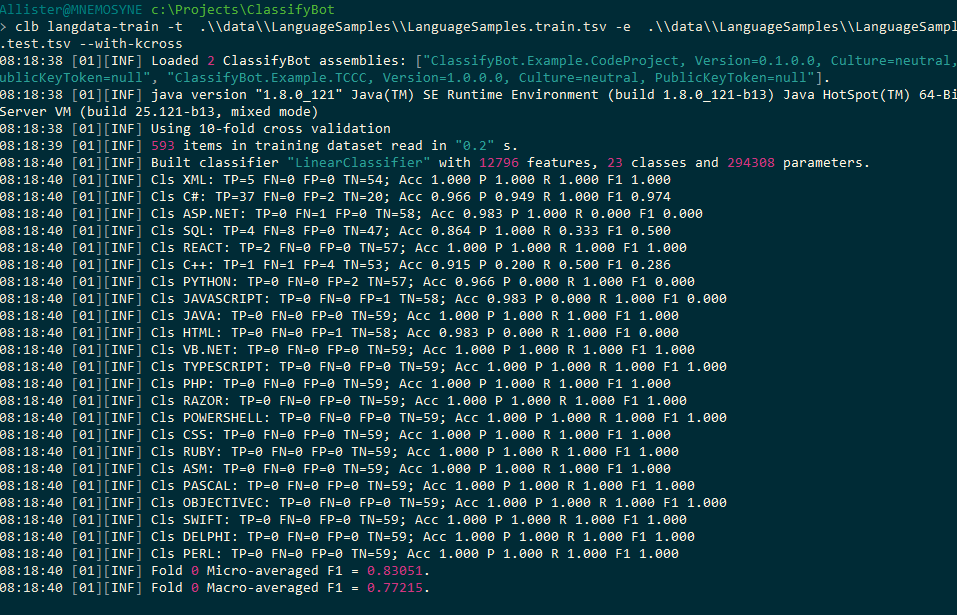
分类器为每个折叠计算结果,使您可以比较分类模型对不同数据子集的执行方式.(The classifier computes results for each fold allowing you to compare how the classification model performed on different subsets of data.)
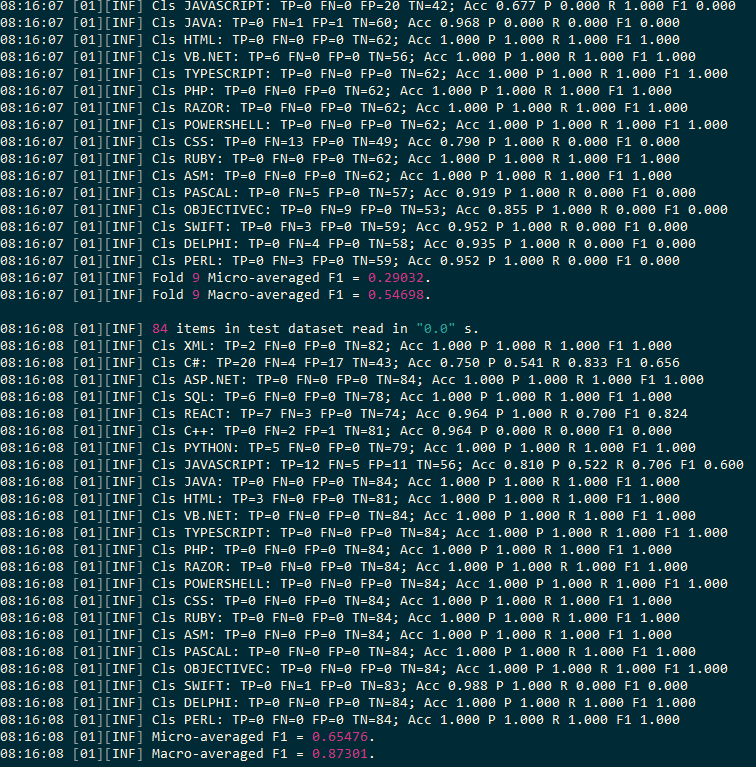
我们看到,即使具有语法功能,许多语言类别仍然存在问题,平均准确率只有65%.我们将需要进行进一步的测试,并设计出进一步的语法功能,以区分这些语言,以使分类器性能更好.积极的一点是,检测标记语言以及Python和React等语言似乎很好.(We see that even with the syntactic features many language classes remain problematic, only averaging 65% accuracy. We will need to do further testing and engineer further syntactic features that distinguish these languages to allow the classifier to perform better. On a positive note, detection of markup languages and languages like Python and React appears good.)
兴趣点(Points of Interest)
如果您习惯使用Python,您可能会觉得ClassifyBot看起来过于矫and,不必要地复杂.毕竟,使用Python或使用Shell脚本下载文件只是一种形式,并且可以使用numpy之类的库的数据处理功能直接从Python控制台处理和转换数据.但是,您应该考虑以下附加代码:(If you are accustomed to Python, you might feel that ClassifyBot seems like overkill and needlessly complicated. After all, downloading a file in Python or using shell scripts is just a one-liner and one can manipulate and transform data right from the Python console using the data manipulation capabilities of libraries like numpy. However, you should consider the additional code needed to:)
- 创建一个CLI程序,该程序可以接受用于数据操作的不同参数(Create a CLI program that can accept different parameters for the data manipulation)
- 将每个文本处理阶段的结果保存为通用格式(Save the results of each text processing stage to a common format)
- 在整个管道中实施日志记录,计时和其他常见操作(Implement logging, timing, and other common operations across your piepline)
- 开发一个OOP模型,以方便其他开发人员或其他项目重用您的代码(Develop an OOP model that facilitates reuse of your code by other developers or in other projects) 一旦您超越了简单的ML实验单用户阶段,使用像ClassifyBot这样的库的好处就会显而易见.进一步的文章将探讨ClassifyBot的不断发展的功能,包括自动为管道阶段和逻辑创建文档和图表之类的内容.(Once you go beyond the simple ML experiment single-user phase the benefits of using a library like ClassifyBot should become apparent. Further articles will look at the evolving features of ClassifyBot including things like automatically creating documentation and diagrams for the pipeline stages and logic.)
历史(History)
- 第一个版本提交给CodeProject(First version submitted to CodeProject)
许可
本文以及所有相关的源代码和文件均已获得The Code Project Open License (CPOL)的许可。
C# Dev AI 新闻 翻译