[译]非负矩阵分解的文档聚类
By robot-v1.0
本文链接 https://www.kyfws.com/ai/document-clustering-with-non-negative-matrix-facto-zh/
版权声明 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
- 6 分钟阅读 - 2559 个词 阅读量 0非负矩阵分解的文档聚类(译文)
原文地址:https://www.codeproject.com/Articles/34390/Document-Clustering-with-Non-Negative-Matrix-Facto
原文作者:Jack_Dermody
译文由本站 robot-v1.0 翻译
前言
A WPF application that uses Non Negative Matrix Factorization to cluster documents.
使用非负矩阵分解对文档进行聚类的WPF应用程序.

介绍(Introduction)
该WPF应用程序在AAAI 2014(人工智能会议)的认可论文列表中找到簇.它显示了每个群集中的关键字,并允许您根据群集中的成员资格对结果列表进行排序.(This WPF application finds clusters within a list of accepted papers to AAAI 2014 (an artificial intelligence conference). It shows the keywords in each cluster, and allows you to sort the list of results based on membership in a cluster.)
非负矩阵分解(NNMF)是一种相对简单的技术,使用矩阵分解在某个单个矩阵中创建预定数量的簇.(Non Negative Matrix Factorization (NNMF) is a relatively simple technique that uses matrix factorisation to create a predetermined number of clusters within some single matrix.)
NNMF聚类可应用于任何统一的正矩阵,但在此应用中,它将应用于从文档及其元数据列表创建的文档/术语矩阵.(NNMF clustering can be applied to any uniformly positive matrix, but in this application, it is applied to the document/term matrix that has been created from the list of documents and their meta data.)
背景(Background)
向量空间模型技术已经在信息检索和索引中使用了数十年.(Vector space model techniques have been used in information retrieval and indexing for many decades.)
如果我们有一个文档集合,我们可以对每个文档中的单词进行计数并将结果存储在二维数组(或矩阵)中,如下所示:(If we have a collection of documents, we can count the words in each of those documents and store the result in a two dimensional array (or matrix) like this:)
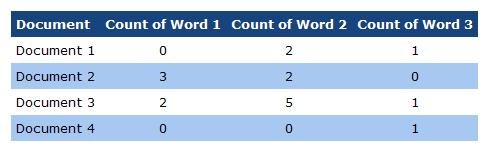
这称为文档/术语矩阵,仅列出文档及其包含的术语数.上面的文档/术语矩阵也可以进行归一化,以使每个值都介于0和1之间.(This is called a document/term matrix, and simply lists the documents and the count of the terms that they contain. The above document/term matrix can also be normalised so that each value falls between 0 and 1.)
然后,从该矩阵中,我们可以将每一行视为一维数组(或向量),并使用两个向量的内积来计算它与同一矩阵中任何其他向量的相似性.该技术在信息检索中有一种经典用法,其中从查询中构造一个向量,然后计算每个文档相对于该查询的点积,从而得出文档的有序列表,并按与查询的相关性进行排序.(From this matrix, we can then think of each row as a single dimensional array (or vector), and compute the similarity of it against any other vector in the same matrix by using the inner product of the two vectors. There is a classic use of this technique in information retrieval, in which a vector is constructed from the query and then the dot product of each document against the query is calculated, which results in an ordered list of documents, sorted by relevance to the query.)
NNMF超出了单行比较的范围,并尝试找到两个矩阵((NNMF goes beyond single row comparisons, and tries to find two matrices ()特征(features)和(and)重量(weights))从文档/术语矩阵中得出,将它们相乘即可重建它.这些特征和权重不能包含负值,因此() from the document/term matrix, that when multiplied together will reconstruct it. These features and weights cannot contain negative values, hence the)**非负数(Non Negative)**部分.(part.)
的(The)特征(features)矩阵为每个要素包含一行,为每个术语包含一列,其值给出了该术语在要素中的归属程度.(matrix contains a row for each feature and a column for each term, with the value giving the degree to which the term belongs in the feature.)
的(The)重量(weights)矩阵包含每个文档的行和每个功能的列,该值给出了每个文档在功能中的归属程度.(matrix contains a row for each document and a column for each feature, with the value giving the degree to which each document belongs in the feature.)
线性代数(Linear Algebra)
该应用程序使用(The application uses the) 开源Bright Wire机器学习库(open source Bright Wire machine learning library) 创建并规范化术语文档矩阵并将该矩阵转换为供文档使用的密集向量(to create and normalise the term document matrix and to convert that matrix into dense vectors that are used by the) NNMF 类.(class.)
使用应用程序(Using the Application)
该示例应用程序立即下载文档数据集并聚集链接.单击一个群集将按文档列表在该群集中的相关性对其进行排序.点击每个文档,即可在Google上搜索该文档.(The sample application immediately downloads the document data set and clusters the links. Clicking on a cluster sorts the document list by its relevance in that cluster. Clicking each document searches for that document on Google.)
使用代码(Using the Code)
数据集是从(The dataset is downloaded from the) UCI机器学习存储库(UCI machine learning repository) .然后,将CSV解析为数据表,提取特征并将其标准化,然后从稀疏特征集中创建密集矢量.(. Then the CSV is parsed into a data table, features are extracted and normalised and then dense vectors are created from the sparse feature sets.)
创建查找表以将密集向量与(A lookup table is created to associate the dense vectors with the) AAAIDocument 是从中创建它们的.(s from which they were created.)
// download the document list
var docList = new List<AAAIDocument>();
using (var client = new WebClient()) {
var data = client.DownloadData(uri);
// parse the file CSV
var dataTable = new StreamReader(new MemoryStream(data)).ParseCSV(',');
// create strongly typed documents from the data table
dataTable.ForEach(row => docList.Add(new AAAIDocument {
Abstract = row.GetField<string>(5),
Keyword = row.GetField<string>(3).Split(KEYWORD_SPLIT, StringSplitOptions.RemoveEmptyEntries).Select(str => str.ToLower()).ToArray(),
Topic = row.GetField<string>(4).Split(TOPIC_SPLIT, StringSplitOptions.RemoveEmptyEntries),
Group = row.GetField<string>(2).Split(TOPIC_SPLIT, StringSplitOptions.RemoveEmptyEntries),
Title = row.GetField<string>(0)
}));
}
// create a document lookup table
var docTable = docList.ToDictionary(d => d.Title, d => d);
// extract features from the document's metadata
var stringTable = new StringTableBuilder();
var classificationSet = new SparseVectorClassificationSet {
Classification = docList.Select(d => d.AsClassification(stringTable)).ToArray()
};
// normalise the document/term associations
var encodings = classificationSet.Vectorise(true);
// convert the sparse feature vectors into dense vectors
var documentClusterList = new List<DocumentCluster>();
using (var lap = Provider.CreateLinearAlgebra()) {
var lookupTable = encodings
.Select(d => Tuple.Create(d, lap.Create(d.Data).AsIndexable()))
.ToDictionary(d => d.Item2, d => docTable[d.Item1.Classification])
;
var vectorList = lookupTable.Select(d => d.Key).ToList();
然后,这些密集的向量通过(These dense vectors are then clustered by) NNMF .(.)
public IReadOnlyList<IReadOnlyList<IIndexableVector>> Cluster(
int numIterations,
Action<float> callback,
float errorThreshold = 0.001f
) {
for (int i = 0; i < numIterations; i++) {
using (var wh = _weights.Multiply(_features)) {
var cost = _DifferenceCost(_dataMatrix, wh);
callback(cost);
if (cost <= errorThreshold)
break;
using (var wT = _weights.Transpose())
using (var hn = wT.Multiply(_dataMatrix))
using (var wTw = wT.Multiply(_weights))
using (var hd = wTw.Multiply(_features))
using (var fhn = _features.PointwiseMultiply(hn)) {
_features.Dispose();
_features = fhn.PointwiseDivide(hd);
}
using (var fT = _features.Transpose())
using (var wn = _dataMatrix.Multiply(fT))
using (var wf = _weights.Multiply(_features))
using (var wd = wf.Multiply(fT))
using (var wwn = _weights.PointwiseMultiply(wn)) {
_weights.Dispose();
_weights = wwn.PointwiseDivide(wd);
}
}
}
// weights gives cluster membership
return _weights.AsIndexable().Rows
.Select((c, i) => Tuple.Create(i, c.MaximumIndex()))
.GroupBy(d => d.Item2)
.Select(g => g.Select(d => _data[d.Item1]).ToArray())
.ToList()
;
}
此功能重复(This function iterates) numIterations 次,每次尝试提高其得分(times, each time trying to improve its score against the) _DifferenceCost 通过略微改善矩阵分解来发挥作用.(function by slightly improving the matrix factorisation.)
因为初始值是完全随机的,所以每次运行聚类算法时,它将发现稍微不同的聚类.但是,文档集往往保持一定的固定性,即同一文档在运行之间往往会同时出现.(Because the initial values are completely random, every time the clustering algorithm runs, it will find slightly different clusters. However sets of documents tend to remain somewhat fixed - i,e. the same documents will tend to occur together between runs.)
差额成本只是找到因子矩阵与原始矩阵之间的距离:(The difference cost simply finds the distance between the factored matrices and the original matrix:)
float _DifferenceCost(IMatrix m1, IMatrix m2)
{
return m1.AsIndexable().Rows
.Zip(m2.AsIndexable().Rows, (r1, r2) => _costFunction.Compute(r1, r2))
.Average()
;
结论(Conclusion)
术语/文档矩阵的NNMF可以产生一些有趣的结果.在每个聚类中找到最紧密相关的术语集并在每个文档和聚类之间具有隶属度可能会很有用.(NNMF of a term/document matrix can yield some interesting results. Finding the the strongest correlated sets of terms with each cluster and having degrees of membership between each document and cluster can be useful.)
历史(History)
- 2009年3月22日(March 22, 2009):第一个版本.(: First version.)
- 2009年5月18日(May 18, 2009):错误修复,服务定义更新.(: Bug fixes, service definition update.)
- 2017年2月21日(February 21, 2017):主要版本和应用程序迁移到.net 4.6.1.(: Major revision and application migrated to .net 4.6.1.)
许可
本文以及所有相关的源代码和文件均已获得The Code Project Open License (CPOL)的许可。
C# .NET4.5 .NET WPF 新闻 翻译