[译]使用ML.Net和C#/VB.Net进行机器学习
By robot-v1.0
本文链接 https://www.kyfws.com/ai/machine-learning-with-ml-net-and-csharp-vb-net-zh/
版权声明 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
- 26 分钟阅读 - 12730 个词 阅读量 0使用ML.Net和C#/VB.Net进行机器学习(译文)
原文地址:https://www.codeproject.com/Articles/1249611/Machine-Learning-with-ML-Net-and-Csharp-VB-Net
原文作者:Dirk Bahle
译文由本站 robot-v1.0 翻译
前言
Solving the Classification problem with ML.Net Version 0.2.
使用ML.Net版本0.2解决分类问题. |
-
Wikipedia_SentimentAnalysis.zip(Wikipedia_SentimentAnalysis.zip)
-
Wikipedia_SentimentAnalysis_VB.zip(Wikipedia_SentimentAnalysis_VB.zip)
-
IrisClassification_uint_VB.zip(IrisClassification_uint_VB.zip) |

指数(Index)
介绍(Introduction)
本文介绍了.Net中的机器学习,但并未涉及到数学方面的问题.它将集中于.Net中数据处理的基本工作流程及其结构,以促进对开放源代码项目中可用内容的试验.(This article introduces machine learning in .Net without touching the mathematical side of things. It will focus on essential work-flows and their structures of the data handling in .Net to facilitate experimentation with what is available in an open source project) ML.Net版本0.2(ML.Net version 0.2) .(.)
ML.Net项目版本(*The ML.Net project version*)**0.2(*0.2*)**可用于(*is available for*)**.Net Core 2.0(*.Net Core 2.0*)**和(*and*)**.Net标准2.0(*.Net Standard 2.0*)**支持(*with support for*)**x64(*x64*)*仅限体系结构(任何CPU现在都无法编译).因此,它应适用于以下任何框架(architecture only (Any CPU will not compile right now). It should, thus, be applicable in any framework where*) .Net Standard 2.0).Net标准2.0( (例如:.Net Framework 4.6.1)适用.该项目目前正在审查中.((eg.: .Net Framework 4.6.1) is applicable. The project is currently on review.)**API可能会改变(APIs may change)**在将来.(in the future.)
背景(Background)
如果要使用面向对象的语言(例如C#或VB.Net),学习机器学习的基础知识并不容易.因为大多数时候您必须先学习Python,然后才需要学习其他内容,而您必须先找到带有示例数据的教程.即使查看诸如[1] Accord.Net,Tensor.Flow或CNTK之类的面向对象的项目也不容易,因为它们每个人都有自己的API,以不同方式实现相同事物的方式,等等. Build 2018 [2]上的演示让我感到很兴奋,因为它们表明我们可以使用通用的工作流程方法,该方法使我们能够利用本地数据,本地.Net程序,本地模型和结果来评估主题,而无需使用服务或其他编程语言(例如Python).(Learning the basics of machine learning has not not been easy, if you want to use an object oriented language like C# or VB.Net. Because most of the time you have to learn Python, before anything else, and then you have to find tutorials with sample data that can teach you more. Even looking at object oriented projects like [1] Accord.Net, Tensor.Flow, or CNTK is not easy because each of them comes with their own API, way of implementing same things differently, and so on. I was thrilled by the presentations at Build 2018 [2] because they indicated that we can use a generic work-flow approach that allows us to evaluate the subject with local data, local .Net programs, local models, and results, without having to use a service or another programming language like Python.)
总览(Overview)
机器学习是人工智能(AI)的子集,它可以回答5种类型的问题[3]:(Machine learning is a subset of Artificial Intelligence (AI) and it can answer 5 types of questions [3]:)
监督下(Supervised)
-
分类(二进制和多类)(Classification (Binary and Multiclass)) 问题:它属于哪一类?(Question: What class does it belong to?)
-
回归(Regression) 问题:多少?(Question: How much or how many?)
无监督(Unsupervised)
-
排行(Ranking) 问题:下一步我该怎么办?(Question: What should I do next?)
-
聚类(Clustering) 问题:这是如何组织的?(Question: How is this organized?)
-
异常检测(Anomaly Detection) 问题:这很奇怪吗?(Question: Is this weird?)
每种类型的问题都有很多应用,并且为了使用正确的机器学习方法,我们必须首先尝试确定我们是否要回答任何给定的问题,如果是,那么我们是否有数据来支持它.(Each type of question has many applications and in order to use the correct machine learning approach we must first try to determine if we want to answer any of the given questions, and if so, whether we have the data to support it.)
监督机器学习(Supervised Machine Learning)
本文讨论了适用于二进制和多类分类的.Net示例(包括示例数据的源代码).这种类型的机器学习算法假定我们可以标记一个项目以确定它是否属于:(This article discusses working .Net examples (source code including sample data) for binary and multiclass classifications. This type of machine learning algorithm assumes that we can tag an item to determine whether it belongs to:)
- 两组之一(二进制分类)或(One of two groups (binary classification) or)
- 多个组之一(多类分类)(One of many groups (multiclass classification)) 当您想用正确或错误答案回答问题时,可以应用二进制分类.您通常会发现自己将一项(图像或文本)分类为2类之一.例如,考虑一个问题,即客户对您最近调查的反馈是否处于良好状态(正面)或负面(负面).(A binary classification can be applied when you want to answer a question with a true or false answer. You usually find yourself sorting an item (an image or text) into one of 2 classes. Consider, for instance, the question of whether a customer feedback to your recent survey is in a good mood (positive) or not (negative).)
用机器学习来回答这个问题需要我们将样本项(例如图像或文本)标记为属于这两个组.正常的工作流程需要两组独立的标记数据:(Answering this question with machine learning requires us to tag sample items (eg: images or text) as belonging to either group. The normal work-flow requires two independent sets of tagged data:)
-
训练数据集(用于训练机器学习算法)和(A Training Data Set (to train the machine learning algorithm) and)
-
评估数据集(用于测量ml算法的效率).(An Evaluation Data Set (to measure the efficiency of the ml algorithm).) 带标记的文本行可能看起来像这样:(A tagged line of text may look like this:)
-
1长大你有偏见的孩子.(1 Grow up you biased child.)
-
0我希望这会有所帮助.(0 I hope this helps.) 其中第一列中的" 1"表示负面情绪,而第一列中的" 0"表示正面情绪.经验法则通常是,如果我们拥有更多的训练数据,则ml算法会更好地工作.并且还应确保训练数据和以后使用的数据是干净的且高质量的,以支持有效的算法.(where “1” in the first column denotes a negative sentiment and “0” in the first column denotes a positive sentiment. The rule of thumb is usually that the ml algorithm will work better if we have more training data. And it should also be assured that the training data and the data used later on is clean and of high quality to support an effective algorithm.)
下方左侧的图表示了使用KPI确定有效算法的总体工作流程,在这里我们(理想地)找到了一个(The overall work-flow to determine an effective algorithm using KPIs is denoted by the diagram on the left side below, where we (ideally) find a)**模型(model)**最能反映我们的分类问题.在此不对模型进行更详细的说明.对于ML.Net,它是一个zip文件,其中包含从标记的训练数据中学到的持久性事实.(that reflects our classification problem best. The model is not explained in more detail here. It is, in the case of ML.Net, a zip file containing the persisted facts learned from the tagged training data.)
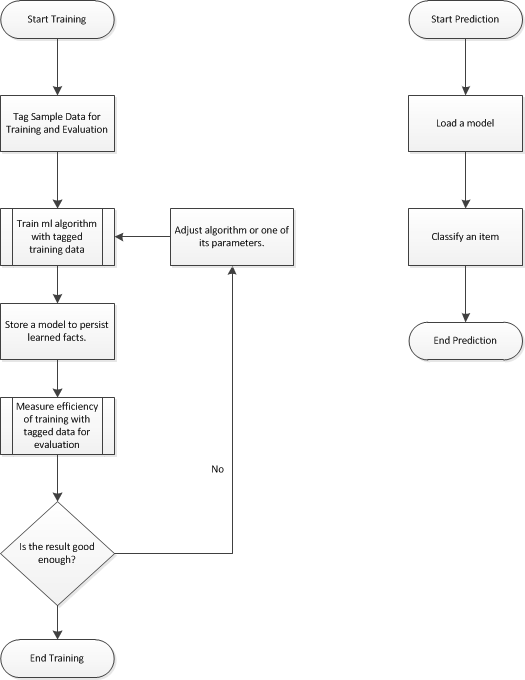
用于评估的第二个独立数据集用于确定朝着学习分类效率的KPI.通过将机器学习算法的结果与可用标签(不使用算法中的标签)进行比较,此步骤可估算出我们的算法将来对商品进行分类的效果.衡量效率的KPI例如是正确分类项目与错误分类项目的百分比.如果我们发现KPI不能满足我们的期望,并且我们需要优化模型的方法,那么我们总是可以返回到训练步骤,调整参数,或者将一种算法替换为另一种算法.(The second independent data set for evaluation is used to determine KPIs towards the efficiency of the learned classification. This steps estimates how good our algorithm will classify items in the future by comparing the result from the machine learning algorithm with the available tag (without using the tag in the algorithm). A KPI to measure efficiency is, for example, the percentage of the number of items classified right versus the wrong classified items. We can always go back to the training step, and adjust parameters, or swap one algorithm for the other, if we find that our KPIs do not meet our expectations and we need ways to optimize the model.)
的(The)**训练(Training)**阶段希望以有效的模型结束,该模型可以在第二阶段中应用(stage hopefully ends with an effective model which can be applied in the second)**预测(Prediction)**阶段对我们将来看到的每个项目进行分类.此阶段需要上一阶段的模型和要分类的项目,该项目用于输出分类的预测(例如:正面或负面情绪).(stage to classify each item that we see in the future. This stage requires the model from the previous stage and the item to classify, which is used to output a prediction of a classification (eg.: positive or negative sentiment).)
这是有关参加机器学习的工作流程的简要概述.我们需要了解这一点,才能与本文下面进一步讨论的代码示例一起使用.因此,让我们依次查看每个样本.(This is a brief overview on the work-flow for attended machine learning. We need to understand this to work with the code samples discussed in this article further below. So, lets look at each sample in turn.)
二进制分类(Binary Classification)
情绪分析维基百科(Sentiment Analysis Wikipedia)
本节中讨论的示例基于(The sample discussed in this section is based on) 情感分析二元分类方案(A Sentiment Analysis Binary Classification Scenario) 来自ML.Net教程.(from the ML.Net tutorial.)
训练阶段(Training Stage)
上一节中讨论的工作流程在本文所附的演示项目中得到了一定程度的实现.该演示项目包含两个可执行项目:(The work-flow discussed in the previous section is implemented to some degree in the demo projects attached to this article. The demo project contains two executable projects:)
- 培训和(Training and)
- 预测(Prediction) 如果编译并启动以下命令,则将获得以下输出:(We get the following output if we compile and start the)**训练(Training)**项目:(project:)
Training Data Set
-----------------
Not adding a normalizer.
Making per-feature arrays
Changing data from row-wise to column-wise
Processed 250 instances
Binning and forming Feature objects
Reserved memory for tree learner: 1943796 bytes
Starting to train ...
Not training a calibrator because it is not needed.
Evaluating Training Results
---------------------------
PredictionModel quality metrics evaluation
------------------------------------------
Accuracy: 61,11%
Auc: 96,30%
F1Score: 72,00%
我们在这里看到程序如何首先训练模型并在第二步中评估结果.(We see here how the program first trains a model and evaluates the result in the second step.)
的(The)**训练(Training)**和(and the)**预测(Prediction)**模块化共享对前面提到的参考(modul share a reference to the previously mentioned)**模型.zip(Model.zip)**文件(大多数是手动复制的-请参见下面的详细信息),对ML.Net库的引用以及数据输入和分类输出中定义的通用模型.(file (most be copied manually - see details below), a reference to ML.Net library, and a common model of the data input and the classification output defined in the) Models 项目:(project:)
在中定义的属性(The properties defined in) ClassificationData 将每一列映射到文本输入文件中存在的输入中.的(map each column into an input that is present in the text input file. The)**标签(Label)**列定义了包含我们要针对每一行文本进行训练的类定义的项目.的(column defines the item that contains the class definition that we want to train against for each line of text. The) Text 属性本身不能被标记为"功能",因为它由多个"列"(int文本文件)组成.这就是为什么我们需要添加(property itself cannot be labeled as a “Feature” because it consists of more than one “column” (int the text file). This is why we need to add the) new TextFeaturizer("Features", "Text") 在下面的管道中的一行将文本读取到输入数据结构中.(line in the pipeline below to read the text into the input data structure.)
的(The) ClassificationData 是对我们的输入的粗略描述,以及应如何将其映射到(is a rough description of our input and how it should be mapped into either a)**标签(Label)**或一个(or a)特征(Feature).尝试删除(. Try removing the)**标签(Label)**列定义,编译和执行,以验证系统是否将引发异常(如果列名为(column definition, compile and execute, to verify that the system will throw an exception, if a column named)**标签(Label)**在输入文本中找不到.(cannot be found in the input text.)
的(The) ClassPrediction 仅陈述一个二进制输出结果,该结果应为(states only one binary output result, which is expected to be a) Boolean 将输入映射到任一二进制类的值.此部分与以下内容有关:(value that maps the input to either binary class. This part is relevant to:)
- 验证学习是否成功(在测试阶段具有已知输入),并(Verify whether learning was succesful (with known input in the test phase) and)
- 在生产中使用模型时,确定机器学习算法的实际分类.(Determine the actual classifiaction of the machine learning algorithm when using its model in production.)
总结:(In summery: The)
ClassificationData用于描述我们希望如何处理输入(总是由(is used to descripe how we whish to process the input (always consisting of)**标签(Label)**和(and)特征(Features)),以及(), and the)ClassPrediction将此输入映射到学习的结果.(maps this input to a learned result.)
的(The)**训练(Training)**使用通过管道输入文本的管道(pipline that consumes the text input via the) ClassificationData 定义如下所示:(definition looks like this:)
ML.Net框架带有可扩展的管道概念,其中可以插入不同的处理步骤,如上所示.的(The ML.Net framework comes with an extensible pipeline concept in which the different processing steps can be plugged in as shown above. The) TextLoader 步骤从文本文件中加载数据,然后(step loads the data from the text file and the) TextFeaturizer 步骤将给定的输入文本转换为特征向量,该向量是给定文本的数字表示.然后,将这种数字表示形式输入到ML社区称为学习者的事物中.在这种情况下,学习者(step converts the given input text into a feature vector, which is a numerical representation of the given text. This numerical representation is then fed into something that the ML community calls a learner. The learner in this case a) FastTreeBinaryClassifier .(.)
一种(A) 学习者或培训者(learner or trainer) 是将数字特征向量转换为模型的组件,以后可用于将来对输入进行分类.这些学习者的文档目前正在构建中,但并不是所有学习者都已完全实施和测试.对于二进制分类,有一些替代学习器可以用作替代学习器(只需编辑构造函数,如下所示):(is the component that converts the numerical feature vectors into a model that can later be used to classify input in the future. The documentation for these learners is currently under construction and not all learners are fully implemented and tested, yet. For binary classifications, there are a few alternative learners that could be used as an alternative (just edit the constructor as shown below):)
| 分类方法(Classification Method) | 准确性(Accuracy) | 澳柯(Auc) | F1分数(F1Score) |
|---|---|---|---|
new AveragedPerceptronBinaryClassifier() |
61.11% | 81.48% | 72.00% |
new FastForestBinaryClassifier() { NumThreads=2, NumLeaves = 25, NumTrees = 25, MinDocumentsInLeafs = 2 } |
72.22% | 97.53% | 78.26% |
new FastTreeBinaryClassifier() { NumLeaves = 5, NumTrees = 5, MinDocumentsInLeafs = 2 } |
61,11% | 96,30% | 72,00% |
new GeneralizedAdditiveModelBinaryClassifier() |
50.00% | 83.95% | 66.67% |
new LinearSvmBinaryClassifier() |
72.22% | 90.12% | 76.19% |
new LogisticRegressionBinaryClassifier() |
50.00% | 86.42% | 66.67% |
new StochasticDualCoordinateAscentBinaryClassifier |
83.33% | 98.77% | 85.71% |
new StochasticGradientDescentBinaryClassifier() |
55.56% | 90.12% | 69.23% |
测试以上所有学习者并显示(Testing all of the above learners and shows that the) StochasticDualCoordinateAscentBinaryClassifier 根据测得的KPI效果最佳.这些KPI是通过以下方式衡量的:(works best based on the measured KPIs. These KPIs are measured by an instance of the) BinaryClassificationMetrics 它还提供其他KPI,例如Precision和Recall.请注意,您仍然可以分析更多的KPI,例如内存消耗和处理时间,这里也没有测量.提出的测试相当小而简短.我们还可以对单个学习者使用不同的设置,这可能仍会显示出明显的改进.当我们面对大量项目(文本或图像等)的自动分类问题时,能够使用这些不同的场景看起来像是一个有趣的练习.(which also offers other KPIs, such as, Precision and Recall. Note that you can still analyse more KPIs, , such as, memory consumption and processing time, which are also not measured here. The test presented is rather small and brief. We can also use different settings of individual learners which may still reveal significant improvements. Being able to play with these different scenarious looks like an interesting excercise when we face the problem of an automated classification of a large amount of items (text or images etc).)
因此,这简而言之就是机器学习如何工作.机器使用数据(文本),将其转换为数值向量,并将向量化的数据集成到模型中.的(So, this in a nutshell how machine learning can work. The machine consumes data (text), converts it into numerical vectors, and integrates the vectorized data into a model. The)模型是第一阶段的主要输出(Model is the main output of the first stage).让我们看一下分类阶段,以了解完整的工作流程.(. Lets have a look at the Classification stage to understand the complete work-flow.)
预测阶段(Prediction Stage)
预测阶段是表示生产中运行的代码的模块,并在新项目到达系统时对数据进行分类.这部分在(The Prediction stage is the modul that represents the code that runs in production and classifies data as new items arrive in the system. This part is implemented in the)**PredictAsync(PredictAsync)**的方法(method of the)**预测(Prediction)**在的项目(project in the)**Wikipedia_SentimentAnalysis(Wikipedia_SentimentAnalysis)**解.此方法的代码如下所示:(solution. The code for this method looks like this:)
的(The) PredictionModel.ReadAsync 方法中的一行将模型从文件系统加载到内存中(line in the method loads the model from the file system into an in-memory) PredictionModel :(:)
加载的模型存储在项目的(The model loaded is stored in the project’s)**学到了(Learned)**夹.这个(folder. This)**模型.zip(Model.zip)**文件(file)**必须从培训模块输出中复制(has to be copied from the Training moduls output)**只要我们发现明显的改进并希望在Prediction模块中加以利用.(whenever we find a significant improvement and want to take advantage of it in the Prediction modul.)
模型加载代码行下方的所有内容都会根据加载的模型评估输入,并在方法的最后一部分中输出预测的分类.您可以使用交互式输入提示来测试您自己的示例文本,并小范围测试所学到的内容和未学到的内容.请记住,通常会清理学习到的数据(与原始输入不同),并且您只能像这样小规模测试.最后可能需要进行更好,更合理的测试(Everything below the model loading code line evaluates input against the loaded model and outputs a predicted classification in the last part of the method. You can use the interactive input prompt to test sample texts of your own and test on a small scale what was learned and what was not. Remember that the learned data is usually cleaned (not the same as the original input) and that you can only test on a small scale like this. A better and more reasonable test is probably to feed in the last)**ñ(n)**来自真实数据源的文本行,获取其分类,并查看独立审阅者是否具有紧密匹配的结果.(text lines from a real data source, get their classification, and see if an independent reviewer has a closely matching result or not.)
在本节中,我们已经看到了二进制分类如何在非常"简单"的情况下用于情感分析.但是ml的真正优势在于,每种类型的问题(这里是A还是B?)都可以应用在各种各样的应用中.让我们在下一部分中回顾另一个示例,以回顾另一种二进制分类用例.(We have seen in this section how binary classification can work for sentiment analysis in a very “simple” scenario. But the real strength of ml is that each type of question (here: Is this A or B?) can be applied in a wide variety of applications. Let’s review one more sample in the next section to review another binary classification use case.)
您收到了垃圾邮件(You Got Spam)
- YouGotSpam_Analysis.zip(YouGotSpam_Analysis.zip)
- YouGotSpam_Analysis_VB.zip(YouGotSpam_Analysis_VB.zip) 本节中讨论的样本数据基于codeproject文章(The data for the sample discussed in this section is based on the codeproject article) 您有垃圾邮件(You’ve Got Spam) .此二进制分类项目的目的是我们想知道确定是否应将给定文本分类为垃圾邮件.(. The aim of this binary classification project is that we want to know determine whether a given text should be classified as Spam or not.)
本文所附的源代码(The source code attached to this article for the)**YouGotSpam_Analysis(YouGotSpam_Analysis)**解决方案几乎与上一节中说明的代码相同.实际上,即使是可执行项目也几乎相同.这里唯一的区别是用于训练和测试评估的数据源,在这种情况下,就是来自(solution is almost identical to the code explained in the last section. Even the execute-able projects are in fact almost identical. The only difference here is the datasource for training and test evaluation, which is in this case the test data from) 以上(the above) codeproject文章(请参阅(codeproject article (see)**数据(Data)**文件夹中(folder in)**训练(Training)**项目).的(project). The)**训练(Training)**项目产生以下输出:(project produces this output:)
Training Data Set
-----------------
Not adding a normalizer.
Making per-feature arrays
Changing data from row-wise to column-wise
Processed 2000 instances
Binning and forming Feature objects
Reserved memory for tree learner: 24082752 bytes
Starting to train ...
Not training a calibrator because it is not needed.
Evaluating Training Results
---------------------------
PredictionModel quality metrics evaluation
------------------------------------------
Accuracy: 100,00%
Auc: 100,00%
F1Score: 100,00%
…这表明我们可以达到与原始指标相同的KPI(…which indicates that we can reach the same KPIs as indicated in the original) 基于Python的文章(article based on Python) .(.)
您可以再次使用(You can again use the)**预测(Prediction)**项目以从文件系统加载模型,并用进一步的输入对其进行测试.(project to load a model from the file system and test it with further input.)
到目前为止讨论的项目表明ML.Net可以帮助自动确定二进制分类.但是,如果我想对两个以上的类别进行分类(例如:消极情绪,中立情绪和积极情绪)怎么办?下一节将检查此用例的数据分类.(The projects discussed so far have shown that ML.Net can be helpful to determine a binary classification in an automated fashion. But what if I want to classify more than 2 classes (eg: negative, neutral, and positive sentiment)? The next section examines classifying data for this use case.)
多类别分类(Multiclass Classification)
语言检测(Language Detection)
- LanguageDetection.zip(LanguageDetection.zip)
- LanguageDetection_VB.zip(LanguageDetection_VB.zip) 本节中讨论的样本数据是从以下位置下载的(The data for the sample discussed in this section was downloaded from) http://wortschatz.uni-leipzig.de(http://wortschatz.uni-leipzig.de) 并进行预处理(删除了引号""),以提高解析体验.(and pre-processed (removed quote character “) for improved parsing experience.)
此处讨论的多类分类用例是基于给定文本的语言检测.想象一下,您有社交媒体代理团队,并且您正在尝试将使用不同语言的在线客户反馈(例如,聊天)传递给使用该语言的正确团队.(The multiclass classifications use case discussed here is the detection of a language based on a given text. Just imagine, you have teams of social media agents and you are trying to relay online customer feedback (eg. chats), in different languages, to the correct team that speaks that language.)
的(The)**语言检测(LanguageDetection)**本节附带的解决方案遵循前面讨论的二进制分类样本的结构.我们有一个(solution attached to this section follows the structure of the previously discussed binary classification samples. We have a)**训练(Training)**项目,一个(project, a)**预测(Prediction)**项目和一个(project, and a)**楷模(Models)**在可执行文件之间共享的类库.的(class library that is shared between the executables. The)**训练(Training)**项目可以用于创建具有特定学习者的模型.然后可以从(project can be used to create a model with a particular learner. A successful model can then be copied from the)**训练(Training)**项目到(project to the)**预测(Prediction)**用于将来输入的完善和多类分类的项目.(project for consumation and multiclass classification of future input.)
的(The)**预测(Prediction)**的项目(project of the)**语言检测(LanguageDetection)**解决方案在定义方式上有所不同(solution differs in the way of how we define the) LanguageClass 物业(property in the) ClassificationData 类和(class and the) Class 物业(property in the) ClassPrediction 类.这两个属性都必须是数据类型(class. Both properties must be of the data type) float 支持多种分类:(to support multible classifications:)
输入映射在(The input mapping in) ClassificationData 与中的相同(is the same as the one in the) 二元分类(binary classification) 问题.唯一的区别不在于我们在(problem. The only difference is not that we have more than two values in the)**标签(Label)**输入的文本文件的一列.(column of the text file that is being fed in.)
输出映射在(The output mapping in) ClassPrediction 是不同的,因为我们现在必须映射到(is different because we now have to map to a) float 价值,以便分类为多个类别.(value in order to classify towards more than one class.)
所需的训练管道如下所示:(The required training pipeling looks like this:)
的(The) Dictionarizer("Label"); 步骤将带有标记输入值(0-5)的每一行映射到存储桶中.的(step maps each line with a labeled input value (0-5) into a bucket. The) PredictedLabelColumnOriginalValueConverter 将预测值(向量)映射到原始值数据类型(浮点数).(maps the predicted value (a vector) to the original values datatype (a float).)
编译并运行(Compiling and running the)**训练(Training)**modul为我们提供以下输出:(modul gets us this output:)
Training Data Set
-----------------
Not adding a normalizer.
Using 4 threads to train.
Automatically choosing a check frequency of 4.
Auto-tuning parameters: maxIterations = 48.
Auto-tuning parameters: L2 = 2.778334E-05.
Auto-tuning parameters: L1Threshold (L1/L2) = 1.
Using best model from iteration 8.
Not training a calibrator because it is not needed.
Evaluating Training Results
---------------------------
PredictionModel quality metrics evaluation
------------------------------------------
Accuracy Macro: 98.66%
Accuracy Micro: 98.66%
Top KAccuracy: 0.00%
LogLoss: 7.50%
PerClassLogLoss:
Class: 0 - 11.18%
Class: 1 - 4.08%
Class: 2 - 5.95%
Class: 3 - 10.43%
Class: 4 - 7.86%
Class: 5 - 5.52%
ML.Net版本0.2中有三个多类分类学习器.其KPI比较如下:(There are three multiclass classification learners in ML.Net Version 0.2. and their KPIs compare as indicated below:)
| 分类方法(Classification Method) | 输出量(Output) |
|---|---|
new StochasticDualCoordinateAscentClassifier() |
准确度宏:98.66%(Accuracy Macro: 98.66%) |
| 精度微:98.66%(Accuracy Micro: 98.66%) | |
| 最高命中率:0.00%(Top KAccuracy: 0.00%) | |
| 对数损失:7.50%(LogLoss: 7.50%) |
PerClassLogLoss: 等级:0-11.18%(Class: 0 - 11.18%) 类别:1-4.08%(Class: 1 - 4.08%) 等级:2-5.95%(Class: 2 - 5.95%) 等级:3-10.43%(Class: 3 - 10.43%) 等级:4-7.86%(Class: 4 - 7.86%) 等级:5-5.52%(Class: 5 - 5.52%)
|
| new LogisticRegressionClassifier() |准确度宏指令:98.52%(Accuracy Macro: 98.52%)
准确度:98.52%(Accuracy Micro: 98.52%)
最高命中率:0.00%(Top KAccuracy: 0.00%)
对数损失:8.63%(LogLoss: 8.63%)
PerClassLogLoss: 等级:0-13.32%(Class: 0 - 13.32%) 类别:1-4.67%(Class: 1 - 4.67%) 等级:2-7.09%(Class: 2 - 7.09%) 等级:3-11.50%(Class: 3 - 11.50%) 等级:4-8.98%(Class: 4 - 8.98%) 等级:5-6.19%(Class: 5 - 6.19%)
|
| new NaiveBayesClassifier() |准确度宏指令:96.58%(Accuracy Macro: 96.58%)
精度微:96.58%(Accuracy Micro: 96.58%)
最高命中率:0.00%(Top KAccuracy: 0.00%)
对数损失:3,453.88%(LogLoss: 3,453.88%)
PerClassLogLoss: 类别:0-3,453.88%(Class: 0 - 3,453.88%) 类别:1-3,453.88%(Class: 1 - 3,453.88%) 类别:2-43.58%(Class: 2 - 3,453.88%) 类别:3-3,453.88%(Class: 3 - 3,453.88%) 类别:4-3,453.88%(Class: 4 - 3,453.88%) 类别:5-3,453.88%(Class: 5 - 3,453.88%)
|
因此,这就是我们可以基于以下方式对文本进行多分类的方法(So, this is how we can multiclass classify text based on)**一个功能(one Feature)**输入列.同样的机器学习方法(多类的二进制)也可用于多个功能输入列,我们将在后面看到.(input column. The same machine learning approach (binary of multiclass) is also available for more than one feature input column, as we will see next.)
鸢尾花分类(Iris Flower Classification)
版本1(Version 1)
- IrisClassification.zip(IrisClassification.zip)
- IrisClassification_VB.zip(IrisClassification_VB.zip) 本节中讨论的多类分类问题是模式识别社区中一个众所周知的参考测试[4].原始数据库由Ronald Fisher于1936年创建,ML.Net样本来自(The Multiclass classification problem discussed in this section is a well known reference test in the pattern recognition community [4]. The original database was created by Ronald Fisher in 1936 and ML.Net sample reviewed here comes from the) 开始使用(Get Started) ML.Net教程的第二部分.问题陈述是创建一个算法,该算法将接受多个浮点值的输入向量(表示花朵的属性),并且该算法的输出应该是花朵的最可能名称.(section of the ML.Net tutorial. The problem statement is to create an algorithm that will accept an input vector of multiple float values (representing properties of the flower), and the output of that algorithm should be the most likely name of the flower.)
在ML.Net中执行此操作需要我们创建一个包含多列的输入映射:(Doing this in ML.Net requires us to create an input mapping with more than one column:)
我们正在输入一组要素列(即SepalLength,SepalWidth,PetalLength,PetalWidth),然后将其合并为一个(We are inputing a set of feature columns (namely SepalLength, SepalWidth, PetalLength, PetalWidth) that is later combined into one)**特征(Features)**向量.的(vector. The)**标签(Label)**在这种情况下,它是一个字符串,作为最后一列给出,以在算法的训练和测试阶段标识每个数据行.(is in this case a string that is given as last column to identify each data row during the training and test stage of the algorithm.)
预测类的结果应该是一个字符串(毫不奇怪):(The result of the predicted class should be (not surprisingly) be a string:)
这种情况的培训代码与上一节非常相似:(The training code for this case is very similar to the previous section:)
这里只有两个新事物.在这种情况下,原始输入数据是逗号分隔的列表,因此,我们必须使用(There are only two new things here. The raw input data is in this case a comma seperated list, therefore, we have to use a) separator: ',' 从管道中的文本文件加载数据时的参数.我们使用(parameter when loading the data from the text file in the pipeline. And we use the) ColumnConcatenator 将一组要素列转换为由一个名为的向量组成的列(to convert the set of feature columns into one column consisting of a vector named)特征(Features).(.)
输出类似于我们之前所看到的(并且我们可以再次对另外两个学习者进行实验,如上一节所示):(The output is similar to what we’ve seen before (and we can again experiment with the other two learners as shown in the last section):)
Training Data Set
-----------------
Automatically adding a MinMax normalization transform, use 'norm=Warn' or 'norm=No' to turn this behavior off.
Using 4 threads to train.
Automatically choosing a check frequency of 4.
Auto-tuning parameters: maxIterations = 45452.
Auto-tuning parameters: L2 = 2.667051E-05.
Auto-tuning parameters: L1Threshold (L1/L2) = 0.
Using best model from iteration 1956.
Not training a calibrator because it is not needed.
Evaluating Training Results
---------------------------
PredictionModel quality metrics evaluation
------------------------------------------
Accuracy Macro: 95.73%
Accuracy Micro: 95.76%
Top KAccuracy: 0.00%
LogLoss: 8.19%
PerClassLogLoss:
Class: 0 - 0.72%
Class: 1 - 10.62%
Class: 2 - 13.43%
同样,我们可以使用(Again, we can use the)**训练(Training)**的模块(module of the)**虹膜分类(IrisClassification)**培训不同学习者和设置并使用(solution to train different learners and settings and use the)**预测(Prediction)**模块以使用先前确定的模型预测新分类.(module to predict new classifications with the previously determined model.)
在本节中,我们已经看到了如何将4个输入列(SepalLength,SepalWidth,PetalLength,PetalWidth)转换为一个矢量化的列(We have seen in this section how 4 input columns (SepalLength, SepalWidth, PetalLength, PetalWidth) are converted into one vectorized)**特征(Features)**列使用(column using the) ColumnConcatenator 转换器.一种等效的方法,不需要我们使用(converter. An equivalent approach that does not require us to use a) ColumnConcatenator 管道中的代码是使用以下输入类定义:(in the pipeline code is to use the following input class definition:)
但这是一个(But it is a)**坏习惯(bad practice)**通过定义实际功能集(to define the actual feature set through the) ClassificationData 定义如上所示.因此,我们应该删除(definition as shown above. We should, therefore, remove the) [ColumnName("Features")] 行并添加(line and add the) new ColumnConcatenator("Features", nameof(Digit.Features)) 在管道代码中代替.当尝试评估不同的功能配置时,这种设计可以为我们提供更大的灵活性.(in the pipeline code instead. This design can give us more flexability when trying to evaluate different feature configurations.)
版本2(Version 2)
- IrisClassification_uint.zip(IrisClassification_uint.zip)
- IrisClassification_uint_VB.zip(IrisClassification_uint_VB.zip) 让我们暂时假设我们不希望机器学习算法处理字符串(因为我们确实想对应用程序的那部分进行本地化).回到处理整数值并将每个整数作为索引来指示分类(花的类型)是一种更好的做法.但是如何才能做到这一点呢?我们可以像这样更改输入和预测输出的定义:(Let us suppose for a moment that we do not want the machine learning algorithm to handle strings (since we really want to localize that part of the application). It would be a better practice to go back to handling integer values and tread each integer as an index to indicate the classification (type of flower). But how exactly can this be done? We can change the definition of the input and predicted output like so:)
接下来,我们将必须删除(Next, we will have to remove the) PredictedLabelColumnOriginalValueConverter 从先前解决方案的流程中,这就是我们可以针对这种情况进行调整的方式(假设我们也调整了数据).该方法也可以在附件中进行验证(from the pipeline of the previous solution and this is how we can adjust for this scenario (assuming we adjusted the data as well). This approach can also be verified in the attached) IrisClassification_uint(IrisClassification_uint) 解.(solution.)
结论(Conclusions)
经审查的示例应用程序表明,在将机器学习交付到.Net框架中时,ML.Net具有令人感兴趣的价值(甚至在版本0.2中也是如此).我们已经看到,二进制和多类分类可以基于不同类型的输入和输出.此输入和输出始终要求:(The reviewed sample applications have shown that ML.Net has an interesting value (even at version 0.2) when it comes to delivering machine learning into the .Net framework. We have seen that binary and multiclass classification can be based on different types of input and output. This input and output always requires:)
- 一种(a)**标签(Label)**和一个(and a)**特征(Features)**列作为输入和(column as input and)
- 一种(a)**预测标签(PredictedLabel)**列作为输出.(column as output.) 输入和输出的数据类型是灵活的,因为在将输入提供给引擎时,可以使用转换器将值转换为数字和向量,并且当我们必须解释分类结果时,显然可以进行相同的转换.(The data types of the inputs and outputs are flexible because converters can be used to convert values into numbers and vectors when feeding the input into the engine and the same conversion is obviously possible when we have to interprete the result of a classification.)
我希望本文对您有所帮助,并有助于您入门.以星号的形式给我您的反馈,或者如果您看到需要添加或更改的必要内容,请告诉我,因为这可以帮助我们所有人进一步开发基于ML.Net的应用程序.(I hope this article was useful and helps getting started with the subject. Give me your feedback in the form of stars or let me know if you see essential things to add or change since this could help us all to develop this ML.Net based apps even further.)
参考文献(References)
-
[1]机器学习框架([1] Machine Learning Frameworks)
-
[2] Build.ML.Net([2] ML.Net at Build 2018)
-
[3]绝对初学者的机器学习([3] Machine Learning for the Absolute Beginner)
-
[4]使用虹膜数据集进行模式识别([4] Pattern Recognition with the Iris Data Set)
- 鸢尾花数据集(维基百科)(Iris flower data set (Wikipedia))
- 使用Keras实现简单的神经网络-带有Python示例(Implementing Simple Neural Network using Keras – With Python Example)
- 使用CNTK和C#批量训练虹膜数据(Train Iris Data by Batch using CNTK and C#)
- Java机器学习库(Java-ML)Java机器学习库(Java-ML)(Java Machine Learning Library (Java-ML)Java Machine Learning Library (Java-ML))
- 在Matlab中使用mlp进行鸢尾花分类(Iris flower classification using mlp in matlab)
历史(History)
- 2018年6月18日在Wikipedia示例中添加了VB.Net示例和较小的错误修复(将默认学习者更改为最佳默认学习者,而不是默认情况下使用最差的学习者).(2018-Jun-18 Added VB.Net samples and minor bugfix in Wikipedia sample (changed default learner to best default learner instead of using worst learner by default).)
许可
本文以及所有相关的源代码和文件均已获得The Code Project Open License (CPOL)的许可。
XML VB.NET C# .NET VS2013 Dev text fuzzy ML AI 新闻 翻译