[译]更多神经网络数学和代码(C#)
By robot-v1.0
本文链接 https://www.kyfws.com/ai/more-neural-network-mathematics-and-code-csharp-zh/
版权声明 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
- 21 分钟阅读 - 10169 个词 阅读量 0更多神经网络数学和代码(C#)(译文)
原文地址:https://www.codeproject.com/Articles/497314/More-Neural-Network-mathematics-and-code-Csharp
原文作者:Lucas Allen
译文由本站 robot-v1.0 翻译
前言
Running, Initializing and Training a Neural Network.
运行,初始化和训练神经网络.
内容(Contents)
-
介绍(Introduction)
-
神经网络变量(Neural network variables)
-
运行神经网络(Running a neural network)
-
初始化神经网络(Initializing a neural network)
- 初始化变量(Initialization variables)
- 网络掩码(The network mask)
- 选择A矩阵(Selecting the A matrix)
- 建立方程式(Setting up the equations)
- 当c> =r时求解w [k](Solving w[k] when c >= r)
- 当c <r时解w [k](Solving w[k] when c < r)
-
训练神经网络(Training a neural network)
- 学习算法(Learning algorithms)
- 输入过饱和(Over-saturated inputs)
- 欠饱和输入(Under-saturated inputs)
-
结论(Conclusion)
- 争论点(Points of contention)
- 兴趣点(Points of interest)
- 未来发展方向(Future directions)
-
参考文献(References)
-
参考书目(Bibliography)
介绍(Introduction)
在神经网络上已经做了很多工作,其中大多数将为您提供一组概率,其中最高的概率是选定的选择.但是,本文将涉及神经网络,其中神经元只能被激活或不被激活,而中间则没有.它的灵感来自于神经学,希望与其他类型的神经网络一样有用.(There has been a lot of work done on neural networks, most of which will give you a set of probabilities with the highest probability being the selected choice. However, this article will deal with neural networks where neurons can only be activated or not activated, with no in-between. The inspiration for this comes from neurology, and hopefully will be as useful as other types of neural networks.)
大多数神经网络由三层组成:输入层,隐藏层和输出层,本文中的神经网络是相似的,但是隐藏层中的神经元可以相互连接,不需要连接到输入层或输出层.(Most neural networks consist of three layers: an input layer, a hidden layer and an output layer, the neural networks in this article are similar, however, the neurons in the hidden layer are able to be connected with each other and don’t need to be connected to either the input layer or the output layer.)
由于本文的数学内容,计数将从数字一(1)开始,而在代码中计数将从零(0)开始.选择这种处理方式是为了清楚起见,希望它不会太混乱.(Because of the mathematical content of this article, counting will begin with the number one (1), while counting in the code will begin with zero (0). This way of doing things was chosen for clarity, and hopefully it’s not too confusing.)
神经网络变量(Neural network variables)
这些是用于神经网络的变量:(These are the variables used for neural networks:)
- n-神经网络具有n个神经元.(n - The neural network has n neurons.)
- i-输入向量的长度.(i - The length of the input vectors.)
- o-输出向量的长度.(o - The length of the output vectors.)
- W-n * n矩阵,其中W [k] [j]是从第j个神经元到第k个神经元的突触权重.(W - An nn matrix, where W[k][j] is the synapse weight from the jth neuron to the kth neuron.*)
- t-长度为n的向量,其中t [k]是第k个神经元的阈值(偏差).当k> i时,t [k]必须大于零,以使神经元无法激活自己. t [k],其中k <=i,可以设置为任何值,因为它们对应于输入神经元的阈值并且不使用.(t - A vector of length n, where t[k] is the threshold (bias) of the kth neuron. t[k] must be greater than zero when k > i, so that neurons can’t activate themselves. t[k] where k <= i, can be set to anything because they correspond to the thresholds of the input neurons and are not used.)
- a-长度为n的向量,如果第k个神经元未激活,则a [k]为0;如果为第n个向量,则a [k]为1.(a - A vector of length n, a[k] is 0 if the kth neuron is not activated and is 1 if it is.)
运行神经网络(Running a neural network)
运行神经网络是将长度为i的二进制输入向量(I)输入到网络中,并将长度为o的二进制输出向量(O)从网络中输出的过程.这是一个三步过程:(Running a neural network is the process where a binary input vector (I) of length i is inputted into the network and a binary output vector (O) of length o is outputted from the network. This is a three step process:)
- 对于(k =1至i)a [k] =I [k](for (k = 1 to i) a[k] = I[k])
- 对于(k =i + 1至n),如果(DotProduct(W [k],a)> =t [k])a [k] =1(for (k = i+1 to n) if (DotProduct(W[k], a) >= t[k]) a[k] = 1)
- 对于(k =n-o + 1至n)O [k + o-n] =a [k](for (k = n-o+1 to n) O[k + o - n] = a[k])
示例:XOR问题(Example: The XOR problem)
根据我的书(大脑和计算机中的魔法织机,意识网络; Rodney Cotterill; 1998年),一个叫Andrei Kolmogorov的人设计了一个定理,该定理用来证明神经网络可以充当XOR逻辑运算符这么长时间.因为网络包含一个隐藏的神经元.本书中的XOR网络如下所示(尽管权重和偏见略有不同):(According to my book (Enchanted Looms, Consciousness networks in brains and computers; By Rodney Cotterill; 1998) in 1957 a man called Andrei Kolmogorov devised a theorem which was used to show that a neural network could act as an XOR logic operator, so long as the network contained a hidden neuron. The XOR network in the book looks like this (Although the weights and biases are slightly different):)
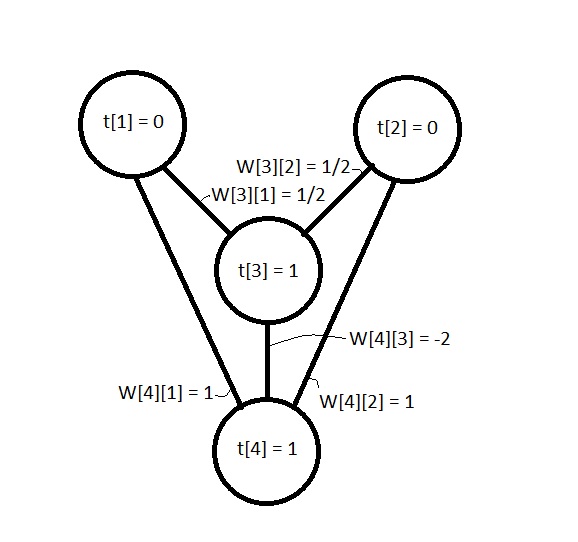 **
图1. XOR网络及其权重和阈值偏差.(Figure 1. The XOR network and its weights and thresholds biases).)**
**
图1. XOR网络及其权重和阈值偏差.(Figure 1. The XOR network and its weights and thresholds biases).)**
XOR网络的权重矩阵为:(The weight matrix for the XOR network is:)

其阈值向量为:(And its threshold vector is:)
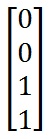
如果我们遵循运行神经网络的三个步骤并将输入向量(I)设为[0,1]或[1,0],则:(If we follow the three steps for running a neural network and let the input vector (I) be [0, 1] or [1, 0] then:)
-
a =[0,1,0,0]或[1,0,0,0](a = [0, 1, 0, 0] or [1, 0, 0, 0])
-
W 3a =1/2,小于t [3],因此a [3]保持为零. W 4a =1,它大于或等于t [4],因此将a [4]设置为1.(W[3] (dot) a = ½ which is less than t[3] so a[3] remains zero. W[4] (dot) a = 1 which is greater than or equal to t[4] so set a[4] to 1.)
-
因此,两个输入的O =[1],这与XOR逻辑运算符一致.(Therefore O = [1] for both inputs, which is consistent with the XOR logic operator.) 如果让I =[1,1],则:(If we let I = [1, 1] then:)
-
a =[1,1,0,0](a = [1, 1, 0 , 0])
-
W 3a =½+½=1,它大于或等于t [3],因此将a [3]设置为1,现在a =[1\1\1\0]. W 4a =1 + 1-2 =0,小于t [4],因此a [4]保持为零.(W[3] (dot) a = ½ + ½ = 1 which is greater than or equal to t[3] so set a[3] to 1, now a = [1, 1, 1, 0]. W[4] (dot) a = 1 + 1 – 2 = 0 which is less than t[4] so a[4] remains zero.)
-
因此,对于输入[1,1],O =[0],这也与XOR逻辑运算符一致.(Therefore O = [0] for the inputs [1, 1] which is also consistent with the XOR logic operator.)
初始化神经网络(Initializing a neural network)
初始化神经网络的原因是提供一个允许网络学习的框架.初始化过程涉及使用基本数据输入和输出.例如,如果您希望它学习不同字母的外观,则可以使用一些基本外观的" a"," b"等作为基本数据输入和"概念",因为缺少更好的单词," a"," b"等,用于基本数据输出.网络初始化之后,可以开始训练阶段,在该阶段以" a"," b"等的所有变化形式训练网络.(The reason for initializing a neural network is to provide a framework which allows the network to learn. The initialization process involves using basic data inputs and outputs. For example, if you wanted it to learn what different letters look like, you’d use some basic looking ‘a’, ‘b’, etcetera, as the basic data inputs, and the ‘concepts’, for lack of a better word, of ‘a’, ‘b’, etcetera, for the basic data outputs. After the network has been initialized the training phase can begin, where the network is trained with all the variations of what ‘a’, ‘b’, etcetera, can look like.)
运行过程涉及将权重矩阵的行与激活向量相乘,但是,通过初始化过程,我们希望找到权重矩阵的条目以及阈值.为此,创建一个激活矩阵(A),其中其列是基本数据输入和输出的激活向量,然后可以使用该矩阵创建一组线性方程,其解是权重矩阵的项.(The run process involves multiplying the rows of a weight matrix with an activation vector, however, with the initialization process we would like to find what the entries of the weight matrix are, as well as the thresholds. To do this an activation matrix (A) is created where its columns are activation vectors for the basic data inputs and outputs, this matrix can then be used to create a set of linear equations whose solutions are the entries of the weight matrix.)
初始化变量(Initialization Variables)
用于初始化神经网络的变量为:(The variables used to initialize a neural network are:)
- r-输入/输出对的数量.(r - The number of input/output pairs.)
- c-网络掩码的第k行中的非NULL条目数.(c - The number of non-NULL entries in the kth row of the network mask.)
- A-n * r矩阵,其中每一列代表一个激活向量(a).(A - An nr matrix, where each column represents an activation vector (a).*)
- T-一个n * r矩阵,其中T [k] [j] =DotProduct(W [k],A [j]).如果A [k] [j] =1,则T [k] [j]> =t [k];如果A [k] [j] =0,则T [k] [j] <t [k].(T - An nr matrix, where T[k][j] = DotProduct(W[k], A[j]). T[k][j] >= t[k] if A[k][j] = 1 and T[k][j] < t[k] if A[k][j] = 0.*)
网络掩码(The network mask)
网络掩码是找到初始权重之前的权重矩阵(W).它用于了解允许存在哪些权重或突触.如果允许存在突触,则网络掩码中的条目为零(0),否则为NULL(N).权重矩阵的区域为:(The network mask is the weight matrix (W) before the initial weights have been found. It is used to know which weights or synapses are allowed to exist. An entry in the network mask is zero (0) if the synapse is allowed to exist or is NULL (N) if it is not. The regions of the weight matrix are:)
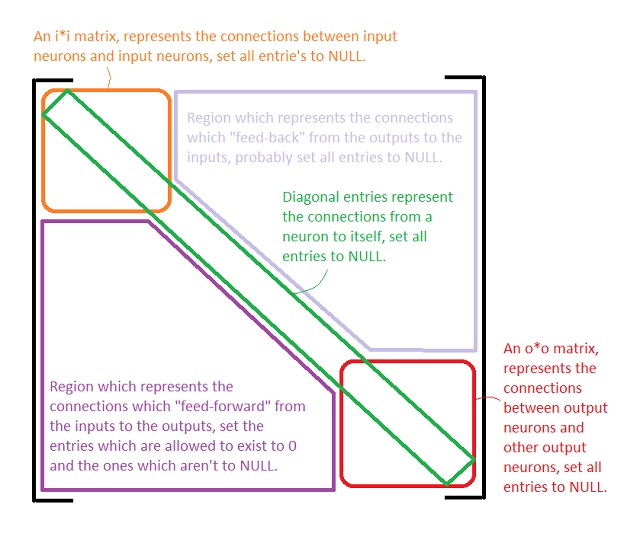 图2.网络掩码的区域.(Figure 2. The regions of the network mask.)
图2.网络掩码的区域.(Figure 2. The regions of the network mask.)
示例:XOR问题(Example: The XOR problem)
用于初始化XOR问题的网络掩码如下所示:(The network mask for initializing the XOR problem would look like:)
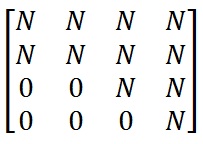
这里N用于表示NULL,即突触不存在.(Here N is used to represent NULL, i.e. the synapse cannot exist.)
选择A矩阵(Selecting the A matrix)
A矩阵表示通过神经网络的路径,并用作一组线性方程的矩阵,其中解是权重矩阵的权重,为了具有最大数量的解,A矩阵的行应为线性独立. A矩阵的区域是.(The A matrix represents the pathways through the neural network and is used as the matrix for a set of linear equations where the solutions are the weights of the weight matrix, in order to have the highest number of solutions the rows of the A matrix should be linearly independent. The regions of the A matrix are.)
 图3. A矩阵及其区域.(Figure 3. The A matrix and its regions.)
图3. A矩阵及其区域.(Figure 3. The A matrix and its regions.)
当我试图弄清楚这些东西是如何工作的时,我得出的结论是,A的行是二进制代码字,需要在二进制中线性独立,对于数学家而言,字段F(While I was trying to figure out how this stuff works I came to the conclusion that the rows of A are binary code words and need to be linearly independent in binary, or for mathematicians, the field F)2(2)(q)((q)).这是1 + 1 =0而不带1的地方,因此101 + 110例如为011.但是,我不确定.(. This is where 1 + 1 = 0 without carrying the 1, so 101 + 110, for example, would be 011. However, I’m not sure about this.)
由于A的元素只能是0或1,所以可以通过使每行中的1的数量为奇数来实现行的线性独立性.这应该适用于隐藏层中的权重,但是如果代表输入的行不是线性独立的,则可能导致将输入层连接到隐藏层的权重出现问题.(Since the elements of A can only ever be 0 or 1 linear independence of the rows can be achieved by having the amount of 1’s in each row be an odd number. This should work for the weights in the hidden layer but may cause problems for the weights connecting the input layer to the hidden layer if the rows representing the inputs are not linearly independent.)
示例:XOR问题(Example: The XOR problem)
A矩阵有多种选择.放入输入向量和输出向量后,A矩阵如下所示:(There are multiple choices for the A matrix. After putting in the input vectors and output vectors the A matrix looks like:)
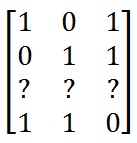
由于只有4行,只有3列,我们不能使A的所有行都线性独立,但是,我们只需要前3行就线性独立.这是由于选择了网络掩码,该掩码将最后一列中的所有条目都设置为NULL.(Since there are 4 rows and only 3 columns we can’t make all the rows of A be linearly independent, however, we only need the first 3 rows to be linearly independent. This is due to the selection of the network mask which has all the entries in the last column set to NULL.)
3个共有4个选项(There are 4 options for the 3)rd(rd)行,它们是:[1\0\0],[0\1\0],[0\0\1],[1\1\1].这些将使前3行线性独立.我们可以使用这些向量中的任何一个,尽管生成的网络会稍有不同,每个网络的权重都不同,但它们都是同构网络.对3使用未列出的选项之一(row, they are: [1, 0, 0], [0, 1, 0], [0, 0, 1], [1, 1, 1]. These will make the first 3 rows linearly independent. We can use any of these vectors, although the resulting networks will be slightly different, each with different weights, they will all be isomorphic networks. Using one of the unlisted options for the 3)rd(rd)行将导致t [3]或t [4]不大于零的解决方案.(row will result in a solution where t[3] or t[4] will not be greater than zero.)
对于此示例,将选择矢量[0,0,1],使其与运行部分中给出的XOR示例一致. A矩阵为:(For this example the vector [0, 0, 1] will be chosen to be consistent with the XOR example given in the run section. The A matrix is:)
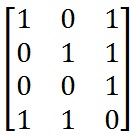
建立方程式(Setting up the equations)
我们从激活矩阵(A)中知道一个神经元是否被激活取决于网络中的其他神经元.从网络掩码中,我们还知道哪些连接(突触)可以存在,哪些不存在.这意味着我们知道,如果A [k] [j] =1,则DotProduct(A [j],W [k])大于或等于t [k];如果A [k,则小于t [k] ] [j] =0.(We know whether a neuron is activated depending on the other neurons in a network from the activation matrix (A). We also know which connections (synapses) can exist and which ones can’t from the network mask. This means that we know that DotProduct(A[j], W[k]) is greater than or equal to t[k] if A[k][j] = 1, or less than t[k] if A[k][j] = 0.)
因为我们知道矩阵乘积(WITH,A)=T,所以我们从矩阵代数知道矩阵乘积(A(Since we know that MatrixProduct(W, A) = T, we know from matrix algebra that MatrixProduct(A),W(, W))=T() = T).这使我们可以为W的每一行建立线性方程,其形式为:(. This lets us set up linear equations for each row of W which take the form:)
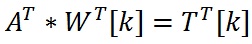
本质上发生的事情是,对于网络中的每个神经元,我们根据激活了哪些神经元以及何时激活神经元来找到突触的权重.既然我们知道何时激活神经元,何时不激活神经元,我们可以创建一组线性方程.(Essentially what’s happening is that for each neuron in the network we find the weights of the synapses into the neuron based on which neurons are activated and when. Given that we know when the neuron is activated and when it’s not we can create a set of linear equations.)
当c> =r时求解W [k](Solving W[k] when c >= r)
A的列(The columns of A)是线性独立的,因为它们对应于A的行,并且A的行数(r)(are linearly independent since they correspond to the rows of A, and the number of rows (r) of A)小于列数(c).这意味着线性方程组MatrixProduct(A(are less than the number of columns (c). This means that the number of solutions to the set of linear equations MatrixProduct(A),W(, W)[k])=T([k]) = T)[k]跨越整个向量空间.这使我们可以将t [k]设置为任意值以及T的元素([k] spans the entire vector space. This allows us to set t[k] to whatever we like and the elements of T)[k]满足任何约束条件的向量.([k] to any vector which satisfies its constraints.)
示例:XOR问题(Example: The XOR problem)
找到4(To find the 4)日(th)权重矩阵的行,我们需要求解线性方程:(row of the weight matrix we need to solve the linear equations:)
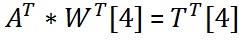
删除A的列后(After removing the columns of A)与网络掩码的NULL条目相对应的方程组如下所示:(which correspond to the NULL entries of the network mask the set of equations looks like:)
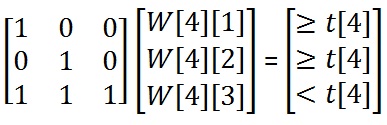
由于我们可以设置T(Since we can set T)k不管我们喜欢什么,我们都可以让T(to whatever we like within its constraints, we may as well let T)[4] =A([4] = A)[4]和t [4] =1.所以我们有:([4] and t[4] = 1. And so we have:)

得出W [4] [1] =1,W [4] [2] =1和W [4] [3] =0 – W [4] [1] – W [4] [2] =0 – 1 – 1 =-2.因此,W [4] =[1,1,-2,N].(Which gives W[4][1] = 1, W[4][2] = 1 and W[4][3] = 0 – W[4][1] – W[4][2] = 0 – 1 – 1 = -2. Therefore W[4] = [1, 1, -2, N].)
当c <r时求解W [k](Solving W[k] when c < r)
在这种情况下,找到突触的权重会比较棘手.该过程涉及三个步骤:(In this case finding the weights of the synapses is a bit trickier. The process involves three steps:)
- 在由A的列形成的r维中找到c维线性子空间(Find a c-dimensional linear subspace in r-dimensions formed by the columns of A).(.)
- 找出向量T(Find a vector T)[k]存在于c维线性子空间中,并且满足其约束.([k] which exists in the c-dimensional linear subspace and satisfies its constraints.)
- 求解线性方程MatrixProduct(A(Solve the linear equations MatrixProduct(A),W(, W)[k])=T([k]) = T)[k]获得权重.([k] to get the weights.)
示例:XOR问题(Example: The XOR problem)
找到3(To find the 3)rd(rd)权重矩阵的行,我们需要求解线性方程:(row of the weight matrix we need to solve the linear equations:)
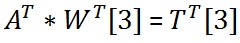
删除A的列后(After removing the columns of A)与网络掩码的NULL条目相对应的方程组如下所示:(which correspond to the NULL entries of the network mask the set of equations looks like:)
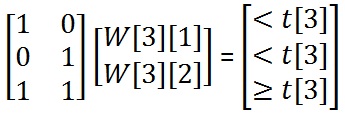
- 由于c =2和r =3,因此r维的c维线性子空间只是3D的2D平面. A列的叉积(Since c=2 and r=3 the c-dimensional linear subspace in r-dimensions is just a 2D plane in 3D. The cross product for the columns of A)是CrossProduct(A(is CrossProduct(A)[1],A([1], A)[2])=[1,1,-1],因此2D平面是x + y – z =0.([2]) = [1, 1, -1], Therefore the 2D plane is x + y – z = 0.)
- T的合适向量(A suitable vector for T)[3]是[½,½,1],其中t [3] =1.由于DotProduct([1,1,-1],[½,½,1])=0,T([3] is [½, ½, 1], where t[3] = 1. Since DotProduct([1, 1, -1], [½, ½, 1]) = 0, T)[3]位于由A的列形成的平面上([3] lies on the plane formed by the columns of A).但是,整个解决方案集可以用0 <W [3] [1] <=W [3] [2] <t [3] <=W [3] [1] + W [3] [2 ].(. However, the entire set of solutions can be described by 0 < W[3][1] <= W[3][2] < t[3] <= W[3][1] + W[3][2].)
- A的上部(The upper part of A)已经是梯形形式,因此我们可以读取W [3] =[1/2,½,N,N].(is already in echelon form so we can just read off W[3] = [½, ½, N, N].)
训练神经网络(Training a neural network)
随着时间的推移,人们开发了许多不同的学习算法,其中最流行的是神经网络的反向传播算法.我感到的问题不是算法本身,而是网络的初始化,据我所知,网络的初始化包括创建随机权重和阈值(偏差).(There are many different learning algorithms that people have developed over time, the most popular being the backward propagation algorithm for neural networks. The problem I feel is not with the algorithms themselves but with the initializing of the network, which to my knowledge consists of creating random weights and thresholds (biases).)
理想情况下,一旦使用基本数据集初始化了网络,便可以学习更广泛的数据训练集.这将允许网络在其输入和输出之间建立更复杂的关联集,从而使其能够为"噪音较大"的输入提供更准确的输出.(Ideally, once a network has been initialized with a basic data set, it would then be able to learn a more extensive training set of data. This would allow the network to develop a more complex set of associations between its inputs and outputs, giving it the ability to give more accurate outputs to ‘noisier’ inputs.)
好文章叫(A good article called)**C#上的神经网络(Neural Networks on C#)**通过(by) 安德鲁`基里洛夫(Andrew Kirillov)(Andrew Kirillov) 列出了一些学习算法,可从以下网站获得(lists some of the learning algorithms and is available at) http://www.codeproject.com/Articles/16447/Neural-Networks-on-C(http://www.codeproject.com/Articles/16447/Neural-Networks-on-C)
学习算法(A learning algorithm)
一个相当基本的学习算法涉及三个步骤:(A fairly basic learning algorithm involves three steps:)
- 使用所需的输入向量(I)运行网络(Run the network with the desired input vector (I))
- 无论给定的输出如何,都将输出神经元更改为所需的输出矢量(O)(Regardless of the outputs given, change the output neurons to the desired output vector (O))
- 对于(k =n至k =i +1){对于(j =1至n)如果(a [k] && a [j] && W [k] [j]!=NULL)W [k] [j ] + =learningRate (t [k]-DotProduct(W [k],a))(For (k = n to k = i + 1) {For (j = 1 to n) if (a[k] && a[j] && W[k][j] != NULL) W[k][j] += learningRate(t[k] - DotProduct(W[k], a)))否则if(!a [k] && a [j] && W [k] [j]!=NULL)W [k] [j]-=learningRate (t [k]-DotProduct(W [k],a ))}(else if (!a[k] && a[j] && W[k][j] != NULL) W[k][j] -= learningRate(t[k] - DotProduct(W[k], a))}) 如果所需的输入矢量类似于初始化网络时的输入矢量之一,则输入到网络中的所需的输入矢量(I)应该已经激活了初始化期间创建的某些路径,从而允许使用类似的学习算法至少取得一些成功.(If the desired input vector resembles one of the input vectors from when the network was initialized, then the desired input vector (I) which was inputted into the network should have activated some of the pathways created during the initialization, allowing a learning algorithm like this to have at least some success.)
将输入与输出相关联的路径应更强,而未使用的路径将减弱.这样可以在路径中进行一种自然选择,既保留了已使用的路径,又保留了尚未消失的路径.(The pathways which were used in associating the inputs to the outputs should be stronger, while the pathways which weren’t used would weaken. This allows for a kind of natural selection in the pathways, where the ones which are used remain, and the ones that aren’t die out.)
输入过饱和(Over-saturated inputs)
在这里,我使用"过饱和"一词来描述输入向量(I)的激活神经元过多.这是字母" A"输入过饱和的示例.(Here I use the term ‘over-saturated’ to describe when the input vector (I) has too many activated neurons. Here is an example of over-saturated inputs for the letter ‘A’.)
 图4.过度饱和的" A"示例.(Figure 4. An example of an over-saturated ‘A’.)
图4.过度饱和的" A"示例.(Figure 4. An example of an over-saturated ‘A’.)
但是,这对大数据集来说应该不是问题,在这种情况下,所需输出与输入中的噪声的关联强度不会像与所需输入的关联一样强.(This, however, shouldn’t be a problem over a large set of data, where the strength the associations of the desired outputs to the noise in the inputs would not be as strong as the associations to the desired inputs.)
欠饱和输入(Under-saturated inputs)
饱和度不足的输入描述了输入向量(I)何时没有足够的激活神经元.当涉及学习时,这可能会带来问题,因为从输入到输出的路径可能尚未激活.这是字母" A"的饱和度不足的示例.(An under-saturated input describes when the input vector (I) doesn’t have enough activated neurons. This may present a problem when it comes to learning, as the pathways from the inputs to the outputs may not have been activated. Here is an example of under-saturated inputs for the letter ‘A’.)
 图5.饱和度较低的" A"示例.(Figure 5. An example of an under-saturated ‘A’.)
图5.饱和度较低的" A"示例.(Figure 5. An example of an under-saturated ‘A’.)
此处的解决方案可能是选择用于初始化网络的网络掩码.如果将网络设计为具有从所需输入到输出的许多路径,而这些路径彼此不交互,则有可能从输入中获得所需输出.尽管这是推测,但可以通过创建将神经元聚集到神经元彼此不相连的组的网络来实现.为此的网络掩码可能类似于:(The solution here may be in the selection of the network mask used for initializing the network. If a network is designed to have many pathways from the desired inputs to outputs which don’t interact with each other it might be possible to get the desired outputs from pieces of the inputs. This may be possible by creating a network where the neurons are clustered into groups where the neurons aren’t connected to each other, although this is speculation. The network mask for this might look like:)
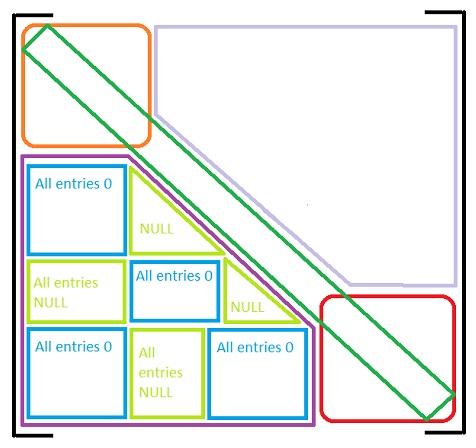 图6.网络掩码可能看起来像什么.(Figure 6. What the network mask might look like.)
图6.网络掩码可能看起来像什么.(Figure 6. What the network mask might look like.)
结论(conclusion)
总之,神经元只能被激活或不能被激活的类型的神经网络可以由突触权重的矩阵和阈值(偏倚)的向量来表示.神经网络中神经元的状态(即是否被激活)也可以通过矢量来表示.这些属性可用于创建一组线性方程,其解可用于初始化神经网络,并且一旦初始化,该网络就可以(希望)从关联的输入和输出中学习.(In conclusion, neural networks of the type where neurons can only be activated or not activated can be represented by a matrix for the synapse weights and a vector for the thresholds (biases). The state of the neurons in a neural network, i.e. whether or not they’re activated, can also be represented by a vector. These properties can be used to create a set of linear equations whose solutions can be used to initialize a neural network, and once initialized the network can (hopefully) learn from associated inputs and outputs.)
以下是本文中未涉及的一些争论点,兴趣点和未来发展方向,但我认为我应该提及:(Following are some points of contention, points of interest, and future directions which have not been covered in this article, but which I feel I should mention:)
争论点(Points of contention)
- 代码不完整(Incomplete code)– NNInitializer类不完整,对于c <r情况没有代码.这是因为我不具备解决这些问题所需的知识或技能,并且想尽一切办法,却找不到适合我的任何地方.(– The NNInitializer class is incomplete, there is no code for the c < r case. This is because I don’t have the knowledge or skills required to be able to figure it out, and try as I might, couldn’t find it already done for me anywhere.)
- 测试中(Testing)–我没有在XOR问题之外测试过代码,但是像任何未测试过代码的人一样,我相信它可以正常工作.(– I haven’t tested the code outside of the XOR problem, but like anyone who hasn’t tested their code, I’m sure it works.)
- 当c>完整A中的总列数时(When c > the total number of columns in the full A)–如果网络掩码任一行中的非NULL条目数大于激活矩阵中的列数,则可能存在错误,这可以通过减少任何一行中的最大非NULL条目数来纠正.可能存在的权重矩阵或通过向A添加更多列.(– There may be an error if the number of non-NULL entries in any row of the network mask is greater than the number of columns in the activation matrix, this may be corrected by reducing the maximum number of non-NULL entries in any row of the weight matrix that can exist or by adding more columns to A.)
兴趣点(Points of interest)
- 社团协会(Associations)–研究大脑的人喜欢说大脑通过关联来学习,通过神经网络,输入与输出相关联.看看是否有可能有一个"字符串"关联.即A与B相关联,C与C相关联,依此类推.(– People who study the brain like to say that the brain learns through associations, with neural networks the inputs are associated with the outputs. It would be interesting to see if it’s possible to have a ‘string’ of associations. I.e. A is associated with B is associated with C and so forth.)
- 编码理论(Coding theory)–允许互联网和手机清晰通信的数学分支可能与神经网络密切相关.二进制线性代码的奇偶校验矩阵可以用作表示神经元隐藏层的激活矩阵的一部分.(– The branch of mathematics that allows the internet and cell phones to communicate clearly may be closely related to neural networks. A parity check matrix for a binary linear code may be used as the part of the activation matrix that represents the hidden layer of neurons.)
同样,可以将奇偶校验输入神经元添加到用于初始化神经网络的基本输入向量.该神经元将为每个基本输入向量赋予奇数权重,这可能会使表示输入神经元的激活矩阵行线性独立.(Also a parity check input neuron may be added to the basic input vectors used for initializing a neural network. This neuron would give each basic input vector an odd weight, which may make the rows of the activation matrix which represent the input neurons linearly independent.)
最后,可以将奇偶校验神经元添加到神经元的输出层,然后可以将其通过综合症解码器以检测或纠正输出中的任何错误.(And finally, parity check neurons could be added to the output layer of neurons, which could then be passed through a syndrome decoder to detect or correct any errors in the outputs.)
未来发展方向(Future directions)
- 认知力学(Cognitive mechanics)–我觉得最好在"赚钱"的同时获得良好的收益.认知力学是神经网络和人工智能之间的研究领域.它涉及定义输入和输出的集合,以及任何给定应用程序的网络掩码.(– I figured I had better ‘coin a term’ while the getting’s good. Cognitive mechanics is the field of study between neural networks and artificial intelligence. It deals with defining the set of inputs and outputs, as well as what the network mask should be for any given application.)
- 节点减少(Node reduction)–我认为,如果有可能找到一个不影响其运行的网络中最少数量的神经元,然后将现有网络中的神经元数量减少到该大小,那将很有趣.(– I think it would be interesting if it were possible to find the smallest number of neurons for a network that doesn’t affect its operation, and then reduce the number of neurons in an existing network to that size.)
- 隐藏层输入(Hidden layer inputs)–能够手动激活和停用隐藏层中的神经元,以便获得"字符串"关联.(– being able to manually activate and deactivate neurons in the hidden layer in order to have a ‘string’ of associations.)
- 神经递质(Neurotransmitters)–大脑有一束神经递质,每个神经元对每个神经元都有不同的受体.使用神经网络对这些模型进行建模可以通过为每个神经递质使用不同的权重矩阵,同时仅保留一个阈值向量和一个激活向量来实现.(– The brain has a whole bunch of neurotransmitters, and each neuron has different receptors for each one. Modelling these using neural networks could be done by using different weight matrices for each neurotransmitter while keeping only one threshold vector and one activation vector.)
每个矩阵将仅给出一个神经递质的权重,运行网络将涉及在对下一个神经元进行相同操作之前,为单个神经元添加每个矩阵的权重.但是,我不确定这些神经网络将如何完成初始化和学习.(Each matrix would give the weights for only one neurotransmitter and running the network would involve adding the weights of each matrix for a single neuron before doing the same for the next neuron. However, I’m not sure how initialization and learning would be accomplished with these types of neural networks.)
参考文献(References)
- 大脑和计算机中的魔法织机,意识网络;罗德尼`科特迪尔(Rodney Cotterill) 1998年(Enchanted Looms, Consciousness networks in brains and computers; By Rodney Cotterill; 1998)
- 基于C#的神经网络;通过(Neural Networks on C#; By) 安德鲁`基里洛夫(Andrew Kirillov)(Andrew Kirillov) ; 2006年;(; 2006;) http://www.codeproject.com/Articles/16447/Neural-Networks-on-C(http://www.codeproject.com/Articles/16447/Neural-Networks-on-C)
- DotNetMatrix:.NET的简单矩阵库;通过(DotNetMatrix: Simple Matrix Library for .NET; By) 保罗`塞洛梅(Paul Selormey) ; 2004;(; 2004;) http://www.codeproject.com/Articles/5835/DotNetMatrix-Simple-Matrix-Library-for-NET(http://www.codeproject.com/Articles/5835/DotNetMatrix-Simple-Matrix-Library-for-NET)
参考书目(Bibliograpgy)
- 编码理论的第一门课程;雷蒙德`希尔(Raymond Hill) 1986年(A first course in coding theory; By Raymond Hill; 1986)
- 生物心理学;詹姆斯
W卡拉特2009年(Biological Psychology; By James W. Kalat; 2009)
许可
本文以及所有相关的源代码和文件均已获得The Code Project Open License (CPOL)的许可。
C# Windows Visual-Studio Dev Architect mathematics AI 新闻 翻译