[译]使用Node.JS,JavaScript和Ajax请求的朴素贝叶斯反垃圾邮件过滤器
By robot-v1.0
本文链接 https://www.kyfws.com/ai/na-ve-bayesian-anti-spam-filter-using-node-js-java-zh/
版权声明 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
- 26 分钟阅读 - 12578 个词 阅读量 0使用Node.JS,JavaScript和Ajax请求的朴素贝叶斯反垃圾邮件过滤器(译文)
原文地址:https://www.codeproject.com/Articles/1229337/Na-ve-Bayesian-Anti-Spam-Filter-Using-Node-JS-Java
原文作者:Arthur V. Ratz
译文由本站 robot-v1.0 翻译
前言
In this article we’ll formulate and thoroughly discuss about probabilistic Bayesian classification algorithm and its implementation in Node.JS and JavaScript that can be actively used to detect and locate messages containing potential spam and other unsolicited data.
在本文中,我们将制定并彻底讨论概率贝叶斯分类算法及其在Node.JS和JavaScript中的实现,这些算法可有效地用于检测和定位包含潜在垃圾邮件和其他未经请求的数据的邮件. Microsoft Azure上的(客户端+服务器端Node.JS)Web应用程序((Client-Side + Server-Side Node.JS) Web Application on Microsoft Azure)
JavaScript(仅客户端)(JavaScript (Client-Side Only))
- 下载antispamnb_nodejs_azure_deploy_final.zip-15.6 MB(Download antispamnb_nodejs_azure_deploy_final.zip - 15.6 MB)
- 下载演示-1.2 MB(Download demo - 1.2 MB)
- 下载antispam_bayes_wparallel.zip-5.1 KB(Download antispam_bayes_wparallel.zip - 5.1 KB)
- 下载antispam_bayes.zip-4.8 KB(Download antispam_bayes.zip - 4.8 KB)
- 下载nodejsantispamnbapp.zip-5.1 MB(Download nodejsantispamnbapp.zip - 5.1 MB)
介绍(Introduction)
“我讨厌垃圾邮件,这就是当您让企业进入网络时发生的事情.” -Jan Koum.(“I hate spam, and that’s what happens when you let businesses onto the network.” - Jan Koum.)
在本文中,我们将讨论基于著名的朴素贝叶斯分类算法的简单反垃圾邮件控件的实现,该算法可用于从本地消息中查找和过滤那些文本(电子邮件,SMS等).最有可能包含垃圾邮件或其他未经请求的数据的数据库.(In this article we’ll discuss about the implementation of a simple anti-spam control based on the famous naïve Bayesian classification algorithm that can be actively used to locate and filter out those texts (E-Mail, SMS, …) from a local messages database that the most likely might contain spam or other unsolicited data.)
由Jason Rennie提出并在1998年由Paul Graham进一步改进后,贝叶斯算法成为最著名的基于AI机器学习的分类算法之一,与此同时,贝叶斯算法在大多数现有的反垃圾邮件保护软件中得到了积极的应用,从而提供了基于确定每个特定文本消息的垃圾邮件概率,一种有效且可靠的方式来识别潜在的垃圾邮件和其他有害内容.(Proposed by Jason Rennie and further improved by Paul Graham in 1998, Bayesian algorithm became one of the most famous AI machine learning-based classification algorithms that, at the meanwhile, is actively used in the most of existing anti-spam protection software hence it provides an efficient and reliable way to recognize potential spam and other unwanted content based on determining spamliness probability of each particular text message.)
在讨论中,我们将介绍执行以贝叶斯算法表述的垃圾邮件分类的基本思想,例如朴素的贝叶斯分类算法的数学背景,该算法基本依赖于著名的贝叶斯定理的主要概念.具体来说,我们将讨论有关公式,这些公式可让我们根据特定邮件可能是垃圾邮件的假设来估计给定训练集中每个邮件及其碎片(即单独的"单词")的垃圾邮件概率.垃圾邮件或合法邮件.我们将找到如何通过使用两个包含"垃圾邮件"和"火腿"(非"垃圾邮件")消息的输入数据集来训练贝叶斯模型.这些数据集中的每个数据集都是一系列概率模式,我们将在算法的学习阶段使用这些概率模式.(During the discussion, we’ll introduce the basic ideas of performing spam messages classification formulated as Bayesian algorithm such as the mathematical background of naïve Bayesian classification algorithm that basically relies on the main concepts formulated as famous Bayesian theorem. Specifically, we’ll discuss about the formulas that allow us to estimate the probability of spam for each message as well as its fragments (i.e. separate “words”) in the given training set, based on the hypothesis that a particular message can be a spam or legitimate. We’ll find out how to train the Bayesian model by using a pair of two input datasets consisting of “spam” and “ham” (not “spam”) messages. Each one of these datasets is an array of probabilistic patterns that we’re about to use during the algorithm’s learning phase.)
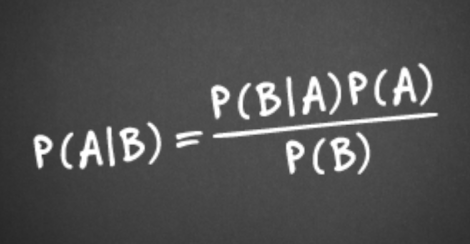
为了计算实际垃圾邮件概率的值,我们将使用概率公理中的总概率公式,该公式涉及使用平凡的线性搜索算法来计算统计信息,例如完全满足特定搜索条件的邮件数量.(To compute the value of actual spam probability, we’ll use the total probability formula from the probability axiom that involves of using the trivial linear search algorithm to compute the statistics such as amounts of messages that exactly meet certain criteria of search.)
另外,如果已经计算出单个邮件中每个单词的部分概率值,我们将彻底讨论如何计算每个邮件的总体垃圾邮件概率值.同时,我们将重点介绍如何使用改进的概率计算公式对整个训练集中的消息进行两个以上不同类别的分类.(Also, we’ll thoroughly discuss how to compute the value of overall spam probability of each message in case when the partial probability value of each word in a single message has already been computed. Simultaneously, we’ll make an emphasize on how to perform classification of messages from the entire training set by more than two distinct classes by using an improved probability computation formula.)
最后,我们将提供有用的指南,说明如何通过添加"噪声"并使用Laplass k自适应平滑技术消除零频问题,从而提高贝叶斯算法的效率.(Finally, we’ll provide useful guidelines on how to improve the efficiency of Bayesian algorithm by eliminating such issues as zero-frequency problem by adding “noise” and using Laplass k-adaptive smoothing.)
在上面讨论了旨在对抗垃圾邮件和其他有害数据的朴素贝叶斯分类算法之后,我们将演示用HTML5和JavaScript编写的邪恶代码,该代码实现了轻量级的反垃圾邮件过滤器网络应用程序示例,该示例可让我们计算出基于贝叶斯分类算法的消息数据库中每个消息的垃圾邮件概率.(After we’ve discussed above the naïve Bayesian classification algorithm intended to combat against spam and other unwanted data, we’ll demonstrate the wicked code written in HTML5 and JavaScript that implements a lightweight anti-spam filter web application sample that allows us to compute the spamliness probability of each message in the messages database based on using Bayesian classification algorithm.)
此外,我们将讨论如何通过使用Parallel.JS框架来显着提高JavaScript中执行复杂概率计算的代码的性能.(Additionally, we’ll discuss on how to significantly improve the performance of code in JavaScript that performs the complex probability computations by using Parallel.JS framework.)
在本文的结尾,我们将花费更多的时间来分析和评论所讨论的Web应用程序提供的垃圾邮件预测结果.(At the end of this article, we’ll spend a bit more time to analyze and comment the spam prediction results provided by the web application being discussed.)
背景(Background)
在本节中,我们将彻底讨论朴素贝叶斯分类器的数学背景和算法,以及其在揭示一堆文本消息中潜在的垃圾邮件时的应用,这些消息通常以电子邮件的形式到达我们的计算机,平板电脑和手机或短信.(In this section, we’ll thoroughly discuss about the mathematical backgrounds and algorithm of the naïve Bayesian classifier as well as its application to reveal potential spam in a stack of text messages, that often arrives to our computers, tablets and cellphones as E-mail or SMS.)
朴素贝叶斯分类算法要点(Naïve Bayesian Classification Algorithm Essentials)
在当今世界,解决潜在的垃圾邮件泛滥问题存在着各种各样的观点和策略.同样,甚至有一整类计算机算法都可以解决传入垃圾邮件和有害邮件检测问题的解决方案.下一课基本上包括各种AI机器学习算法,这些算法允许执行垃圾邮件检测,例如,基于经过训练的人工神经网络的实施,这些人工神经网络通过训练使用从连续长期学习过程中获得的"经验"来揭示垃圾邮件消息使用包含大量垃圾邮件的数据库.这些AI算法通常很复杂,需要大量时间进行训练才能执行高质量的垃圾邮件预测.(In today’s world, there is a vast of various opinions and strategies of solving the potential spam flood problem. As well, there’s even an entire class of computer algorithms addressing the solution of incoming spam and unwanted messages detection problem. The following class basically includes the either various AI machine learning algorithms that allow to perform spam detection based, for example, on the implementation of artificial neural networks trained to reveal spam messages by using the “experience” acquired from the continuous long-term learning process using database containing a huge number of spam messages. Those AI algorithms are typically complex and require large amounts of time to be trained for performing a quality spam prediction.)
实际上,朴素的贝叶斯分类器是受概率论简单性(特别是贝叶斯定理)启发的算法的一个很好的例子,该算法基于以下假设而专门设计用于解决快速可靠的垃圾邮件检测问题:垃圾邮件或合法邮件.(In fact, naïve Bayesian Classifier is a good example of an algorithm that inspired by the simplicity of probability theory, specifically Bayesian theorem, designed especially to solve the problem of fast and reliable spam detection based on the hypothesis that a certain message could be persistent among the either spam or legitimate messages.)
学习过程(Learning Process)
贝叶斯数据挖掘概率算法也属于AI算法类别的主要原因是,它最适合在每个"时代"内部署简单的机器学习过程,其中已经包含了大量的训练消息.到目前为止,已处理消息数据库.实际上,以下算法允许计算每个特定邮件的垃圾邮件概率,在垃圾邮件概率值计算结束时,将其进一步附加到"垃圾邮件"或"火腿"(非垃圾邮件)邮件集.此后,垃圾邮件检测引擎将对从输入数据集中检索到的下一封邮件进行概率计算,直到确定所有现有邮件的垃圾邮件概率为止.对于刚刚到达消息数据库的每个新消息,执行类似的过程.下图说明了贝叶斯算法的学习过程:(The main reason why, the Bayesian data mining probabilistic algorithm belongs also to the class of AI algorithms is that it is the most suitable to deploy a simple process of machine learning during each “epoch” of which a large set of training messages already contained in the messages database so far is processed. Actually, the following algorithm allows to compute the spamliness probability of each particular message, that is further appended to either set of “spam” or “ham” (not spam) messages at the end of the spam probability value computation. After that, the spam detection engine proceeds with the probability computation for the next message retrieved from an input dataset, until it has determined the probability of spam for all existing messages. The similar process is performed for each new message that has just arrived at the messages database. The Bayesian algorithm learning process is illustrated on figure below:)

如上所示,朴素的贝叶斯分类算法使用了三个消息输入数据集.第一个数据集仅包含那些被识别为"垃圾邮件"的邮件.第二个数据集分别由不包含垃圾邮件片段的邮件组成.最后,第三个数据集是一组用于执行实际贝叶斯模型训练的消息,其中包括我们旨在计算垃圾邮件概率的消息.正如我们已经讨论的那样,根据垃圾邮件的可能性,将来自第三训练数据集的每条消息分类并存储到"垃圾邮件"或"火腿"数据集中.(As it’s shown above, naïve Bayesian classification algorithm uses three input datasets of messages. The first dataset contains only those messages recognized as “spam”. Respectively, the second dataset consists of messages that do not contain any spam fragments. Finally, the third dataset is a set of messages used for performing the actual Bayesian model training and includes messages for which we’re aiming to compute the spamliness probability. As we’ve already discussed each message from the third training dataset is classified and stored into the “spam” or “ham” datasets depending on the spam probability.)
朴素的贝叶斯分类算法最有用的好处之一是,它在学习阶段或垃圾邮件检测过程中使用相同的概率计算程序.反过来,这使得以下算法易于制定和实施.因此,我们实际上在学习和检测阶段都不需要两个单独的过程,使用以下算法可以大大加快垃圾邮件的检测过程.(One of the most useful benefits of naïve Bayesian classification algorithm is that it uses the same probability computation procedure for either learning phase or the process of spam detection. This, in turn, makes the following algorithm an easy to formulate and implement. Hence we actually do not need two separate processes for either learning and detection phase, the using of the following algorithm allows to drastically accelerate the spam detection process.)
既然我们已经讨论过贝叶斯算法的训练场景,那么现在让我们深入研究基于执行垃圾邮件概率计算的邮件分类过程.(Since we’ve already discussed about the Bayesian algorithm’s training scenario, let’s now delve into the explanation of the process of messages classification based on the performing the spamliness probability computation.)
初始化(Initialization)
所讨论算法的初始化阶段实际上非常简单.在此阶段,我们真正需要做的就是在执行实际训练之前,为给定数据集中的每个测试消息在区间[-1; 1]中分配随机初始概率值.实际上,生成的初始随机值必须很小,可以忽略不计,以防止我们在计算过程中分配非法值,从而获得概率大小的不可信值:(The initialization phase for the algorithm being discussed is actually very simple. During this phase, all what we actually need is to assign the random initial probability value in the interval [-1;1] for each test message in the given dataset prior to performing the actual training. In fact, those initial random values being generated must be negligibly small preventing us from assigning the illegitimate values during the computation process and thus obtaining untrustworthy values of probability magnitude:)
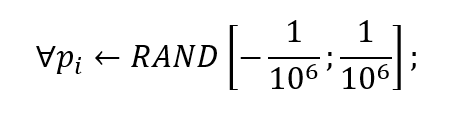
正如我们已经讨论的那样,使用贝叶斯概率模型来计算包含"稀有"单词的邮件的垃圾邮件概率,该单词的出现频率通常很小,通常导致获得的结果值为0或NaN.(As we’ve already discussed, the using of Bayesian probabilistic model to compute the spam probability for messages containing “rare” words, which occurrence frequency is typically small, normally leads to obtaining the resulting value equal to 0 or NaN.)
在大多数情况下,可以通过使用自适应平滑以及为每个特定测试消息提供初始随机概率值来解决以下问题.换句话说,通过分配这些初始随机值,我们实际上是在概率计算过程中添加一些"噪声",以避免出现概率大小预测不起作用并且特定测试消息的后续值仍然存在的情况执行这些特定的计算后,保持等于0或NaN.(In the most cases, the following issue can be resolved by using an adaptive smoothing as well as providing an initial random probability value for each particular test message. In the other words, by assigning those initial random values we’re actually adding some “noise” to the probability computation process in order to avoid a case in which the probability magnitude prediction takes no effect and the following value for a particular test message still remains equal to 0 or NaN after performing those specific computations.)
言语不清(Spamliness of Words)
由于我们已经完成了贝叶斯预测过程的输入数据集初始化,因此,花一点时间来了解预测过程本身.正如我们可能从一开始就已经知道的那样,在整个预测过程中,我们旨在针对训练数据集中给定消息集中的每个单词分别计算垃圾邮件的概率.通常使用以下公式完成此操作:(Since we’ve performed the input dataset initialization for Bayesian prediction process, let’s spend a moment to understand the process of prediction itself. As we might already know from the very beginning, during the entire prediction process we’re aiming to compute the spam probability individually for each word in the given set of messages from the training dataset. This is typically done by using the following formula:)
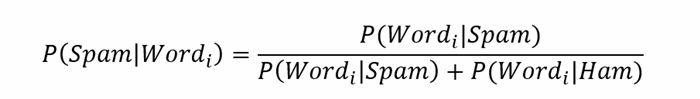
哪里:(where:)P(Word_i | Spam)–特定单词至少出现在垃圾邮件之一中的概率;(P(Word_i | Spam) – the probability that a specific word will occur at least in one of the spam messages;)
P(字_i |火腿)(P(Word_i | Ham))-某个特定字词至少会在其中一个火腿(“非垃圾邮件”)消息中出现的可能性;(- the probability that a specific word will occur at least in one of the ham (“not spam”) messages;)
P(垃圾邮件| Word_i)(P(Spam | Word_i))–特定词是垃圾邮件或垃圾邮件消息一部分的总体概率;(– the overall probability that a specific word is spam or a part of spam message;)
上面显示的公式是贝叶斯定理的特例,它允许基于已实现另一个相互关联的事件的知识条件来计算某个事件的概率.而且,以下公式与概率论中积极使用的总概率定律密切相关,该概率通过通过几个不同事件固有的部分概率集来表示总概率的值,从而将边际概率与条件概率幅度相关联.(The formula shown above is a special case of Bayesian theorem that allows to compute the probability of a certain event based on the condition of knowledge that another interrelated event has been realized. Also, the following formula is closely related to the law of total probability actively used in probability theory to relate the marginal to conditional probability magnitudes by expressing the value of total probability via the set of partial probabilities inherent to several distinct events.)
有两种方法可以解决给定单词的垃圾邮件概率计算.具体来说,我们可以基于基于消息或基于单词的统计信息来计算以下概率值.在讨论中,我们基本上处理了两种方法,分别是基于消息的消息或基于单词的概率计算.(There’s the couple of approaches addressing a given word’s spamliness probability computation. Specifically, we can compute the following probability values based on either messages- or words-based statistics. During the discussion we’ve basically dealt with both approaches of either messages- or separate words-based probability computation.)
首先,我们一开始就要讨论的是基于消息的统计垃圾邮件概率计算方法.(First, what we’re about to discuss right at the very beginning is the messages-based statistics spam probability computation approach.)
要基于所收集消息的统计信息来计算特定消息中给定单词的实际垃圾邮件,我们通常需要计算上式中列出的这两个部分概率的值.通常使用从概率公理得出的常规公式完成此操作:(To compute the actual spamliness of a given word in a particular message based on the statistics of messages being collected, we normally need to compute the values of those two partial probabilities listed in the formula above. This is typically done by using the conventional formula that derives from the probability axiom:)
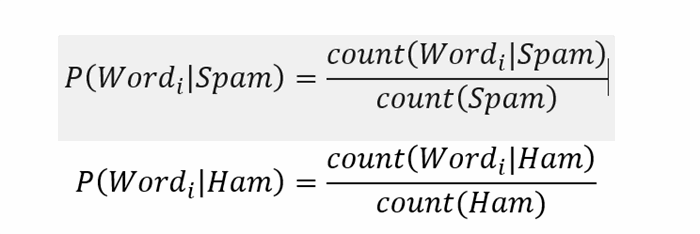
哪里:(where:)Word_i-要为其计算垃圾邮件概率值的给定单词,(Word_i - the given word for which spamliness probability value is computed,)
P(Word_i | Spam)– Word_i是垃圾邮件的部分概率,(P(Word_i | Spam) – the partial probability that Word_i is spam,)
P(Word_i | Ham)– Word_i是火腿(不是垃圾邮件!)的部分概率,(P(Word_i | Ham) – the partial probability that Word_i is ham (not spam!),)
count(Word_i | Spam)包含Word_i的"垃圾邮件"消息的总数,(count(Word_i | Spam) the total amount of “spam” message containing Word_i,)
count(Word_i | Ham)包含Word_i的"火腿"消息的总数,(count(Word_i | Ham) the total amount of “ham” message containing Word_i,)
count(Spam)-所有垃圾邮件中的单词总数,(count(Spam) - the total amount of words in all spam messages,)
count(Ham)-所有合法消息中的单词总数(count(Ham) - the total amount of words in all legitimate messages)
在这种情况下,要计算上述每种概率,我们需要在"垃圾邮件"或"火腿"邮件数据集中执行简单的线性搜索,以估算"垃圾邮件"和"火腿"训练集.同样,我们还需要计算这些数据集中消息数量的总价值.(In this case, to compute each of these probabilities mentioned above, we need to perform a trivial linear search in the either “spam” or “ham” messages datasets to estimate the number of messages containing the given word in the “spam” and “ham” training sets respectively. As well, we also need to compute the overall value of the number of messages in these datasets.)
为了获得给定单词为"垃圾邮件"的概率值,我们只需将包含给定单词的"垃圾邮件"中的邮件数除以属于"垃圾邮件"数据集的邮件总数即可.同样,我们将包含" ham"中给定单词的邮件数量除以" ham"消息的总数,以获得给定单词为" ham"的概率.(To obtain the probability value that given word is “spam” we’ve simply divided the number of messages in “spam” containing the given word by the total amount of messages belonging to the “spam” dataset. Similarly, we’ve divided the number of messages containing the given word in “ham” by the total number of “ham” messages to obtain the probability that the given word is “ham”.)
最后,我们必须将那些概率值替换为上面列出的主要公式,以获得给定单词的垃圾邮件程度的度量.(Finally, we must substitute those probability values to the main formula listed above to obtain the measure of the spamliness of the given word.)
正如我们已经讨论过的,要计算每个给定单词的垃圾邮件概率,我们将使用如下所示的略有不同的公式:(As we’ve already discussed, to compute the spam probability for each given word, we’ll use a slightly different formula shown below:)
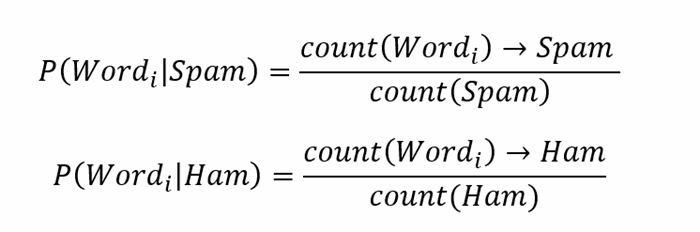
哪里:(where:)Word_i-要为其计算垃圾邮件概率值的给定单词,(Word_i - the given word for which spamliness probability value is computed,)
P(Word_i | Spam)– Word_i是垃圾邮件的部分概率,(P(Word_i | Spam) – the partial probability that Word_i is spam,)
P(Word_i | Ham)– Word_i是火腿(不是垃圾邮件!)的部分概率,(P(Word_i | Ham) – the partial probability that Word_i is ham (not spam!),)
count(Word_i)->垃圾邮件-所有垃圾邮件中Word_i的总数,(count(Word_i) -> Spam - the total amount of Word_i in all spam messages,)
count(Word_i)-> Ham-所有非垃圾邮件中的Word_i总数,(count(Word_i) -> Ham - the total amount of Word_i in all ham (not spam!) messages,)
count(Spam)-所有垃圾邮件中的单词总数,(count(Spam) - the total amount of words in all spam messages,)
count(Ham)-所有合法消息中的单词总数(count(Ham) - the total amount of words in all legitimate messages)
要根据单词的统计信息查找给定单词的垃圾邮件概率值,我们必须使用线性搜索算法来计算所有包含垃圾邮件的邮件中下一个单词出现的次数,以及与之相似的出现次数所有合法邮件中的以下字词.之后,我们只需将这两个值除以"垃圾邮件"或"垃圾邮件"中的单词总数即可获得给定单词分别属于"垃圾邮件"和" ham"邮件的特定概率值.(To find a given word’s spamliness probabilty value based on the statistics of words, we must use the liniar search algorithm to compute the count of the occurrences of the following word in all messages containing spam, as well as the similar value of the occurrences count for the following words in all legitimate messages. After that, we need to simply divide these two values by the total number of words in either “spam” or “ham” messages to obtain the specific probability values that the given word belongs to “spam” and “ham” messages respectively.)
根据大多数现有的贝叶斯垃圾邮件分类算法准则,强烈建议在所有"垃圾邮件"或"火腿"邮件中使用不同的唯一单词数量的值.但是,为了提供垃圾邮件预测过程的有效性能优化,我们将使用"垃圾邮件"或"火腿"字词的总可能值,因为使用总字数计数值不会对特定概率值计算有足够的影响.(According to the most of existing Bayesian spam classification algorithm guidelines, it’s strongy recommended to use the value of the amount of distinct unique words in either all “spam” or “ham” messages. However, to provide an efficient performance optimization of the spam prediction process, we’ll use the value of total possible amount of “spam”- or “ham”-words, since that the using of the total words count value does not have a sufficient impact on the specific probability values computation.)
计算垃圾邮件的概率(Computing Probability of Spam)
由于我们已经找到了如何计算单个邮件中每个单词的部分垃圾邮件概率的方法,因此让我们仔细研究一下整个邮件垃圾邮件概率的计算过程.(Since, we’ve already found out how to compute the partial spamliness probabilities of each word within a single message, let’s take a closer look at the process of the total message spam probability computation.)
让我们事先提醒一下,要基于基于邮件或基于单词的统计信息计算特定邮件的总体垃圾邮件概率,我们将使用下面列出的相同公式.(Let’s remind beforehand, that to compute the overall spam probability for a particular message based on the either messages- or words-based statistic, we’ll use the same formula listed below.)
不仅如此,对于特定单词的垃圾邮件概率计算,还可以通过多种方法轻松估算给定火车中特定邮件实际包含垃圾邮件的概率.(As well as, for the particular words spamliness probability computation, there’s the number of methods by using which we can easily estimate the probability that a specific message in the given trainset actually contains spam.)
提供最可信赖的预测结果的第一种方法是找到给定消息中每个特定单词的部分概率的平均值.为此,我们将使用以下公式:(The very first approach that provides the most trustworthy prediction results is to find the average value of the partial probabilities of each specific word in a given message. To do this we’ll use the following formula:)
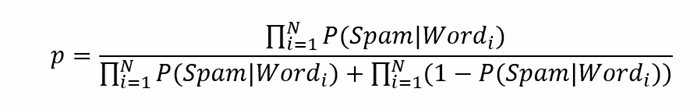
哪里:(where:)N-给定消息中的单词数,(N - the amount of words in a given message,)
P(Spam | Word_i)–垃圾邮件的部分概率,(P(Spam | Word_i) – the partial probability of spamliness,)
p –给定邮件包含垃圾邮件的总体概率;(p – the overall probability that a given message contains spam;)
但是,在特殊情况下,以下数学模型无法提供正确的垃圾邮件概率值.具体来说,对于在给定文本中很少出现的单词,概率的估计值可能等于0.为避免出现以下问题,强烈建议使用Laplass k自适应平滑并在初始概率值上添加一些"噪声"在初始化阶段,正如我们从一开始就已经讨论过的那样.通常,k自适应平滑对上述公式进行了非常简单的修改:(However, there’re special cases when the following mathematical model fails to provide the correct values of spam probability. Specifically, for the words that rarely occur in given text the estimated value of probability might be equal to 0. To avoid the ocurrence of the following issues it’s strongly recommended to use Laplass k-adaptive smoothing and add some “noise” to initial probability values during the initialization phase as we’ve already discussed right from the very beginning. Normally k-adaptive smoothing provides a very simple modification to the formula listed above:)
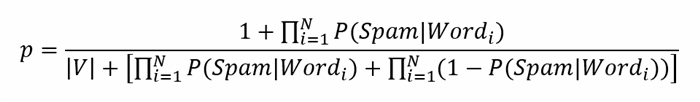
实际上,为了提供k自适应平滑,我们通常需要将1.0的值加到公式的分子上,并将不同单词总数的值分别加到公式的分母上.通常,这可以避免总邮件的垃圾邮件概率值看起来为0的情况.(Actually, to provide k-adaptive smoothing, we normally need to add up the value of 1.0 to the formula’s numerator as well as the value of the overall number of distinct words to the formula’s denominator respectively. This normally allows to avoid a case in which the value of total message’s spam probability appears to be 0.)
这是垃圾邮件吗?(Is This A Spam Message?)
既然我们已经找到了如何在给定的输入训练集中为每条消息计算垃圾邮件的可能性,那么现在让我们看一下该过程,在此过程中我们将使用概率数据来检测新邮件中的垃圾邮件,到达垃圾邮件检测队列.(Since we’ve already found out how to compute a probability of spam for each message in the given input training set, let’s now take a shor glance at the process during which we’ll use the probability data to detect spam in the new messages that arrive to the spam detection queue.)
为此,我们将使用简单的线性搜索算法,并遍历先前针对输入训练集中每个消息中找到的每个特定单词计算出的垃圾邮件概率值的数组.(For that purpose we’ll use the trivial liniar search algorithm and iterate through the array of the spamliness probability values that have already been previously computed for each particular word found in each message from the input training set.)
为此,我们首先需要将输入消息字符串分成单词数组.之后,我们将遍历下一篇文章,并对输入消息字符串中的每个特定单词在单词垃圾邮件概率数组中进行线性搜索,以查找从输入消息字符串中检索到的当前单词的垃圾邮件概率的特定值.由于我们已经获得了输入消息字符串中当前单词的垃圾邮件概率,因此我们正在检查当前单词概率是否大于0.5.如果是这样,我们将垃圾邮件单词counter的值加1.否则,如果概率值小于0.5,则我们将火腿单词counter的值加1.(To do this, we initially need to split up the input message string into an array of words. After that we’re iterating through the following article and for each particular word from the input message string performing a linear search in the array of words spamliness probabilities to find the specific value of spam probability for the current word retrieved from the input message string. Since we’ve obtain the spamliness probability for the current word in the input message string, we’re performing a check if the current word probability is greater than 0.5. If so, we’re incrementing the value of spam words counter by 1. Otherwise, if the probability value is less than 0.5, then we’re incrementing ham words counter by 1.)
最后,我们正在检查垃圾邮件计数器的值是否大于垃圾邮件计数器的值.如果是这样,则当前邮件包含垃圾邮件,或者是合法邮件,除非另有说明.同样,将邮件垃圾邮件概率的值计算为垃圾邮件单词数的值除以给定邮件内单词总数的值.(Finally, we’re performing a check if the value of spam words counter is greater than the ham words counter value. If so, the current message contains spam, or is legitimate unless otherwise. Also, the value of message spam probability is computed as the division of the value of the number of spam words by the overall number of words within a given message.)
朴素贝叶斯反垃圾邮件控制部署方案(Naїve Bayesian Anti-Spam Control Deployment Scenario)
通常,使用AI机器学习和数据挖掘算法可提供强大而有效的解决方案,以对抗垃圾邮件泛滥攻击.但是,这些算法的已知软件实现基本上需要常规PC和服务器的CPU和系统内存的足够资源,这些资源将执行特定于垃圾邮件检测的任务.(The using of AI machine learning and data mining algorithms normally provide the robust and efficient solution to combat agressive spam flood attacks. However, known software implementations of these algorithms basically require sufficient resources of CPU and system memory of regual PCs and servers that will perform the spam detection-specific tasks.)
在这种情况下,为了为PC和移动设备提供全面的反垃圾邮件保护,强烈建议维护一簇垃圾邮件保护服务器,其中每台服务器将充当群集的节点,以完成当前的垃圾邮件概率计算.活动的传入电子邮件和SMS消息队列.下图显示了维护反垃圾邮件保护群集的最常见方案:(In this case, to provide the total anti-spam protection for PCs and mobile devices, it’s strongly recommended to maintain a cluster of spam-protection servers, each one of which will serve as a cluster’s node to accomplish the spam probability computation for the currently active incoming e-mail and SMS messages queue. The most common scenario for maintaining anti-spam protection cluster is shown on figure below:)
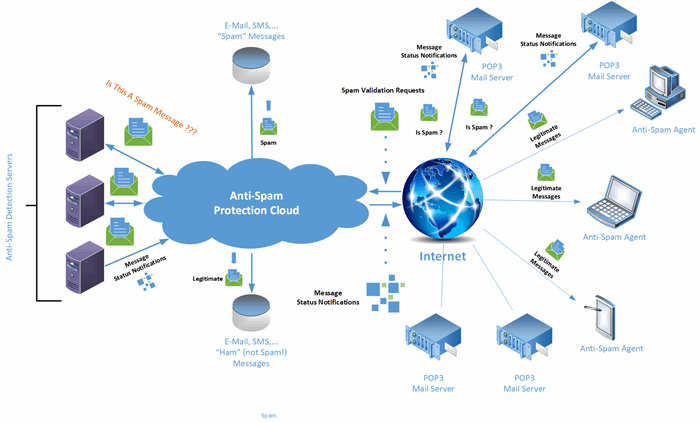
根据所介绍的部署方案,我们必须维护一个基于计算群集的反垃圾邮件保护云.以下群集中的每个计算节点将对通过Internet到达邮件服务器的每个邮件执行实时后台垃圾邮件检测任务.(According to the deployment scenario being introduced, we must maintain a computational cluster-based anti-spam protection cloud. Each computational node in the following cluster will perform a real-time background spam detection tasks for each message arrived to mailing servers over the Internet.)
为了提供全面的反垃圾邮件保护,邮件服务器向反垃圾邮件保护云发送了新邮件以及垃圾邮件验证请求.然后,每个特定的邮件被发送到内部的反垃圾邮件检测服务器,这些服务器执行实际的垃圾邮件概率计算,结果以那些邮件服务器接收到的特定邮件状态通知作为响应.如果通过了垃圾邮件验证,则邮件服务器将合法邮件存储到邮件数据库中.最后,那些不包含垃圾邮件的合法邮件是通过Internet上用户PC和其他设备上安装的电子邮件客户端软件下载的.(To provide a total anti-spam protection, mailing servers sent new messages arrived along with spam validation requests to the anti-spam protection cloud. Then, each particular message is sent to the internal anti-spam detection servers that perform the actual spam probability computation, and as the result respond with specific message status notifications received by those mailing servers. If the spam validation is passed, mailing servers store legitimate messages into messages database. Finally, those legitimate messages containing no spam are downloaded by e-mail client software installed on users PCs and other devices over the Internet.)
结论…(In conclusion…)
正如我们已经讨论的那样,有很多不同的意见和方法来与每天发送到我们的电子邮件收件箱,SMS和聊天消息的潜在垃圾邮件作斗争.仅在部署上面讨论的反垃圾邮件解决方案时,才建议使用本文介绍的Naveve贝叶斯垃圾邮件分类算法.为了维护前端客户端的反垃圾邮件保护,可能存在基于其他概念的其他方法,而不是AI机器学习和数据挖掘算法.(As we’ve already discussed there’re a vast of various opinions and methods for fighting with potential spam arriving daily to our e-mail inboxes, SMS and chat-messangers. The Naїve Bayesian Spam Classification algorithm that has been introduced in this article is recommended solely for deploying an anti-spam solution discussed above. To maintain the front-end client anti-spam protection there’re probably the other methods based on the other concepts rather than AI machine learning and data mining algorithms.)
使用代码(Using the code)
在本节中,我们将深入研究用JavaScript编写的代码,该代码实现了一个Web应用程序,该应用程序基于贝叶斯分类算法来执行垃圾邮件概率计算.(In this section, we’ll delve deep into the code written in JavaScript that implements a web application that performs the spamliness probability computation based on using Bayesian classification algorithm.)
加载数据中(Loading Data)
正如我们已经讨论过的,用于此编程任务的测试数据集存储为纯文本文件:(As we’ve already discussed, the testing dataset for this programming assignment is stored as a plain-text file:)
格式很简单:每行1条消息的文本文件,每行以"垃圾邮件"或"火腿"开头(火腿是"非垃圾邮件"),然后是逗号,然后是消息.该文件分为3部分,每部分均以#开头的标头标记.有一些垃圾邮件和火腿邮件需要培训,然后是一组用于测试代码的邮件.(The format is simple: A text file with 1 message per line, each line begins with “Spam” or “Ham” (ham is “not spam”), followed by a comma and then the message. The file is in 3 parts, each part labelled by a header starting with #. There’s spam and ham messages for training, followed by a set of messages that are to be used for testing your code.)
以下JavaScript代码实现了从上传到Web应用程序的文件中加载数据:(The following JavaScript code implements loading data from files uploaded to the web application:)
隐藏(Hide)收缩(Shrink)![]() 复制代码(Copy Code)```js
var train_set = [];
var count_unique = [];
function loadData()
{
var file_reader = new FileReader();
var fp = document.getElementById(“datafile_upload”);
复制代码(Copy Code)```js
var train_set = [];
var count_unique = [];
function loadData()
{
var file_reader = new FileReader();
var fp = document.getElementById(“datafile_upload”);
file_reader.onload = function() {
var data_set = new Array();
var contents = file_reader.result;
var lines_array = contents.split("#");
for (var i = 0; i < lines_array.length; i++)
{
if (lines_array[i].length > 0 && lines_array[i] != "")
{
var count = 0;
var data_ent = new Array();
var data_s = lines_array[i].split("\n");
for (var j = 0; j < data_s.length; j++)
{
if (data_s[j].indexOf("<p>") > -1) {
var words_raw = data_s[j].replace(new RegExp("<p>", 'g'), "")
.replace(new RegExp("</p>", 'g'), "");
if(words_raw.length > 0) {
var words = new Array(words_raw.split(" "));
for (var l = 0; l < words.length && i < 3; l++)
{
if (find_wds_n(words_raw, words[0][l]) == 1) {
count++;
}
}
data_ent.push({ "content" : words, "probability" : (Math.random() - Math.random()) / Math.pow(10,3) });
}
}
}
count_unique.push(count);
data_set.push(data_ent);
}
}
train_set = data_set;
renderData(2, train_set);
}
file_reader.readAsText(fp.files[0], "UTF-8");
}
### 使用JavaScript和并行JS实现朴素贝叶斯算法:(*Implementing Naive Bayesian Algorithm Using JavaScript and Parallel JS:*)
要计算总概率的特定值,我们需要获取包含给定单词的消息数的值.为此,我们需要计算特定消息文本中单词出现的次数.为此,我们实现了以下JavaScript例程:(*To compute the specific values of total probability, we'll need to obtain the value of the number of messages containing a given word. To do this, we'll need to count the number of word's occurrences in a particular message text. For that purpose, we've implemented the following JavaScript routine:*)
隐藏(*Hide*)复制代码(*Copy Code*)```js
function find_wds_n(text, word)
{
text += ''; word += '';
if (word.length <= 0) {
return text.length + 1;
}
word = word.replace(/[.*+?^${}()|[\]\\]/g, '\\$&');
return (text.match(new RegExp(word, 'gi')) || []).length;
}
要查找包含给定单词的消息总数,我们需要实现并使用以下函数:(To find the total number of messages containing the given word, we need to implement and use the following function:)
隐藏(Hide)复制代码(Copy Code)```js function find_msg_nw(tsID, data_set, word) { var msg_count = 0; for (var i = 0; i < data_set[tsID].length; i++) { if (find_wds_n(data_set[tsID][i][“content”][0].toString(), word) > 0) msg_count++; }
return msg_count;
}
为了使用上面介绍的公式来计算单个邮件出现垃圾邮件的可能性,我们实现了以下Javascript函数:(*To compute the probability of a single message spamliness by using the formulas introduced above, we've implemented the following Javascript function:*)
隐藏(*Hide*)复制代码(*Copy Code*)```js
function predict_spam_wds(data_set, msg_index, count_spam, count_ham)
{
var p_spam = 1, p_ham = p_spam;
for (var i = 0; i < data_set[2][msg_index]["content"][0].length; i++)
{
var p_ws = find_msg_nw(0, data_set, data_set[2][msg_index]["content"][0][i]) / count_spam;
var p_wh = find_msg_nw(1, data_set, data_set[2][msg_index]["content"][0][i]) / count_ham;
var probability = ((p_ws + p_wh) != 0) ? p_ws / (p_ws + p_wh) : 0;
if (probability > 0) {
p_spam *= probability; p_ham *= 1 - probability;
}
}
return ((p_spam + p_ham != 0)) ? p_spam / (p_spam + p_ham) : 0;
}
为了通过计算每个特定消息的垃圾邮件概率来执行实际的贝叶斯模型学习,我们实现了以下用JavaScript编写的代码片段,并使用Parallel JS框架来提高以下过程的性能:(To perform the actual Bayesian model learning by computing the spamliness probability for each particular message we’ve implemented the following fragment of code written in JavaScript and using Parallel JS framework to improve the performance of the following process:)
隐藏(Hide)收缩(Shrink)![]() 复制代码(Copy Code)```
function predict_all()
{
var p = new Parallel(Array.apply(null, { length : train_set[2].length }).map(Number.call, Number),
{ env: { data_set : train_set }, envNamespace: ‘parallel’ });
复制代码(Copy Code)```
function predict_all()
{
var p = new Parallel(Array.apply(null, { length : train_set[2].length }).map(Number.call, Number),
{ env: { data_set : train_set }, envNamespace: ‘parallel’ });
document.getElementById("status").innerHTML = "<p>Processing...</p>";
p.require(find_wds_n).require(find_wds_n)
.require(find_msg_nw).require(predict_spam_wds).map(function (data) {
return predict_spam_wds(global.parallel.data_set, data,
global.parallel.data_set[0].length, global.parallel.data_set[1].length); }).then(function (data) { for (var s = 0; s < arguments[0].length; s++)
{
train_set[2][s]["probability"] += arguments[0][s];
document.getElementById("entry" + s).innerHTML = "p = " +
train_set[2][s][“probability”].toString() + " R = [" + ((Math.round(train_set[2][s][“probability”]) > 0) ? “<span style="color : red;">Spam” : “<span style="color : green;">Ham") + “]"; }
document.getElementById("status").innerHTML = "<p>Completed!!!</p>";
});
}
为了在结果消息集中呈现数据,我们已经实现了一种特定的机制,该机制通过使用DOM动态构建结果网页来执行消息输出:(*To render the data in the resulting set of messages, we've implementing the specific mechanism that performs the messages output by dynamically constructing a results web-page using DOM:*)
隐藏(*Hide*)收缩(*Shrink*)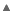
复制代码(*Copy Code*)下面列出了包含反垃圾邮件控制Web应用程序的完整html文档:(*The complete html-document containing the anti-spam control web-application is listed below:*)
index.html:(*index.html:*)隐藏(*Hide*)收缩(*Shrink*)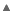
复制代码(*Copy Code*)### 使用Node.JS和Ajax请求实现(*Implementation Using Node.JS and Ajax Requests*)
index.pug:(*index.pug:*)
server.js:(*server.js:*)
## 兴趣点(*Points of Interest*)
同时,关于如何最正确地执行邮件垃圾邮件概率计算的问题,有很多意见.具体而言,可以基于基于消息或基于单词的统计信息来评估垃圾邮件概率的大小.这两种方法都提供了不同的结果和垃圾邮件预测的质量.我希望对通过使用这两种方法获得的结果进行调查非常有趣,最后,选择能够提供期望的垃圾邮件质量预测的方法.(*At the meanwhile there're many opinions regarding the question on how to perform the messages spamliness probability computation the most correctly. Specifically, the spam probability magnitude can be evaluated based on the either messages- or words-based statistics. These both approaches provide different results and quality of spam prediction. I hope that it will be rather interesting to survey the results obtained by using these both approaches, and, finally, select the approach capable of providing the desired quality of spamliness prediction.*)
## 历史(*History*)
- 2018年2月11日(*February 11, 2018*)-该文章的第一版已经出版;(*- The first revision of the article has been published;*)
- 2018年2月19日(*February 19, 2018*)-该文章的最终修订版已发布;(*- The final revision of the article has been published;*)
## 许可
本文以及所有相关的源代码和文件均已获得[The Code Project Open License (CPOL)](http://www.codeproject.com/info/cpol10.aspx)的许可。