[译]使用多卷积神经网络的在线手写识别
By robot-v1.0
本文链接 https://www.kyfws.com/ai/online-handwriting-recognition-using-multi-convolu-zh/
版权声明 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
- 19 分钟阅读 - 9170 个词 阅读量 0使用多卷积神经网络的在线手写识别(译文)
原文地址:https://www.codeproject.com/Articles/523074/Online-handwriting-recognition-using-multi-convolu
原文作者:Vietdungiitb
译文由本站 robot-v1.0 翻译
前言
This article has been presented at The Ninth International Conference on Simulated Evolution And Learning (SEAL 2012). I would like to post it here with my previous articles to everybody can more understand to my project.
本文已在第九届模拟进化与学习国际会议(SEAL 2012)上发表.我想将它与以前的文章一起发布在这里,以使每个人都能对我的项目有更多的了解.
本文已在第九届模拟进化与学习国际会议(SEAL 2012)上发表.我想在这里发布(This article has been presented at The Ninth International Conference on Simulated Evolution And Learning (SEAL 2012). I would like to post it here with) 我以前的文章(my previous articles) 每个人都可以对我的项目有更多的了解.(to everybody can more understand to my project.)
抽象.(Abstract.)
本文介绍了一种使用C#语言编写的,用于使用UNIPEN在线手写训练集的在线手写识别系统的库.基于卷积神经网络的识别引擎,对MNIST训练集的识别率高达99%,对UNIPEN的数字训练集的识别率高达97%(1a),对44022个大写字母和数字的集合(1a,1b)的识别率高达89%小写字母(1c).将这些网络组合在一起,可以创建一个更大的系统,该系统可以识别62个英文字符和数字.提出了一种可以从手写文本中提取句子,单词和字符的手写分割算法.然后将字符作为网络的输入.(This paper presents a library written by C# language for the online handwriting recognition system using UNIPEN-online handwritten training set. The recognition engine based on convolution neural networks and yields recognition rates to 99% to MNIST training set, 97% to UNIPEN’s digit training set (1a), 89% to a collection of 44022 capital letters and digits (1a,1b) and 89% to lower case letters (1c). These networks are combined to create a larger system which can recognize 62 English characters and digits. A proposed handwriting segmentation algorithm is carried out which can extract sentences, words and characters from handwritten text. The characters then are given as the input to the network.) 关键字:(Keywords:)人工智能,卷积,神经网络,UNIPEN,模式识别.(artificial intelligent, convolution, neural network, UNIPEN, pattern recognition.)
介绍(Introduction)
人工神经网络(ANN)起源于1950年代末,直到1980年代计算机热潮时代才开始普及.如今,人工神经网络主要用于解决复杂的现实世界问题.本文提供了针对一个非常特定的目的(识别手写数字和字母)而构建的一个非常特定的神经网络(卷积神经网络)的简要信息.作者还为使用C#语言编写的神经网络创建了一个库,该库使用两种基本技术在手写识别任务(MNIST和UNIPEN)上表现出最佳性能:弹性变形极大地扩展了训练集的大小;以及卷积神经网络.通过使用库中的网络原型,识别系统可以在运行时创建,加载多个不同的神经网络.此外,系统可以组合多个组件网络来识别更大的模式数据集.(Originated in late 1950’s, Artificial neural networks (ANN) did not gain much popularity until 1980s when a computer boom era. Today, ANNs are mostly used for solution of complex real world problems. This paper provides brief information of one very specific neural network (a convolutional neural network) built for one very specific purpose (to recognize handwritten digits and letters). The author also created a library for the neural network written by C# language which has shown the best performance on handwriting recognition task (MNIST and UNIPEN) using two essential techniques: elastic distortion that vastly expanded the size of the training set and convolution neural network. By using a network prototype in the library, the recognition system can create, load multi different neural networks on runtime. Furthermore, the system can combine several component networks to recognize a larger pattern dataset.)
卷积神经网络(CNN)(Convolution neural network (CNN))
通过梯度下降训练的多层神经网络从大量示例中学习复杂的高维非线性映射的能力使其成为图像识别任务的明显候选者.在传统的模式识别模型中,手动设计的特征提取器从输入中收集相关信息,并消除无关的可变性.训练器分类器(通常,标准的,完全连接的多层神经网络可以用作分类器),然后将所得的特征向量分类为类.但是,它可能会有一些问题会影响识别结果.卷积神经网络解决了传统方法的这一缺点,从而在模式识别任务上实现了最佳性能.(The ability of multi-layer neural networks trained with gradient descent to learn complex, high-dimentional, non-linear mappings from large collections of examples make them obvious candidates for image recognition tasks. In the traditional model of pattern recognition, a hand-designed feature extractor gathers relevant information from input and eliminates irrelevant variabilities. A trainer classifier (normally, a standard, fully-connected multi-layer neural network can be used as a classifier) then categorizes the resulting feature vectors into classes. However, it could have some problems which should influent to the recognition results. The convolution neural network solves this shortcoming of traditional one to achieve the best performance on pattern recognition task.)
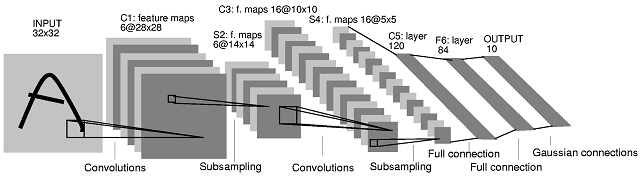
图.(Fig.)1个(1).(.)典型的卷积神经网络(LeNET 5)[1] <o:p>(A Typical Convolutional Neural Network (LeNET 5)[1]<o:p>)
CNN是多层神经网络的一种特殊形式.像其他网络一样,CNN通过反向传播算法进行训练.区别在于它们的体系结构.卷积网络结合了三种架构思想,以确保一定程度的移位,缩放和失真不变性:局部接收场,共享权重(或权重复制)空间或时间二次采样.它们专门设计用于以最少的预处理操作直接从数字图像识别图案.预处理和分类模块在单个集成方案中. CNN的架构细节已在Yahn LeCun博士和Patrice Simard博士[1],[3]的文章中进行了全面描述.(The CNNs is a special form of multi-layer neural network. Like other networks, CNNs are trained by back propagation algorithms. The difference is inside their architecture. The convolutional network combines three architectural ideas to ensure some degree of shift, scale, and distortion invariance: local receptive field, shared weights (or weight replication) spatial or temporal sub-sampling. They have been designed especially to recognize patterns directly from digital images with the minimum of pre-processing operations. The preprocessing and classification modules are in a single integrated scheme. The architecture details of CNN have been described comprehensively in articles of Dr. Yahn LeCun and Dr. Patrice Simard [1],[3].)
图中显示了用于手写数字识别的典型卷积神经网络.它由几层组成.输入层的大小为32 x32,并接收包含要识别的数字的灰度图像.像素强度在-1和+1之间归一化.第一隐藏层C1包含六个特征图,每个特征图具有25个权重(构成5x5可训练内核)和偏差.通过将输入层与相应内核进行卷积并应用激活函数来获得结果,即可计算出特征图的值.特征图的所有值都被约束为共享相同的可训练内核或相同的权重值.由于具有边框效果,要素地图的尺寸为28x28,小于输入图层.(The typical convolutional neural network for handwritten digit recognition is shown in figure. 1. It consists a set of several layers. The input layer is of size 32 x32 and receives the gray-level image containing the digit to recognize. The pixel intensities are normalized between −1 and +1. The first hidden layer C1 consists six feature maps each having 25 weights, constituting a 5x5 trainable kernel, and a bias. The values of the feature map are computed by convolving the input layer with respective kernel and applying an activation function to get the results. All values of the feature map are constrained to share the same trainable kernel or the same weights values. Because of the border effects, the feature maps’ size is 28x28, smaller than the input layer.)
每个卷积层后面都有一个子采样层,该子采样层将各个卷积层的特征图的尺寸减小了两倍.因此,隐藏层S2的子采样图的大小为14×14.类似地,C3层具有16个大小为10x10的卷积图,S4层具有16个大小为5x5的子采样图.这些功能的实现与层C1和S2完全相同. S4图层的要素图的大小为5x5,对于第三个卷积层来说太小了.该神经网络的C1到S4层可以看作是可训练的特征提取器.然后,将可训练的分类器以3个完全连接的层的形式添加到特征提取器(通用分类器).(Each convolution layer is followed by a sub-sampling layer which reduces the dimension of the respective convolution layer’s feature maps by factor two. Hence the sub-sampling maps of the hidden layer S2 are of size 14x14. Similarly, layer C3 has 16 convolution maps of size 10x10 and layer S4 has 16 sub-sampling maps of size 5x5. The functions are implemented exactly as same as the layer C1 and S2 perform. The S4 layer’s feature maps are of size 5x5 which is too small for a third convolution layer. The C1 to S4 layers of this neural network can be viewed as a trainable feature extractor. Then, a trainable classifier is added to the feature extractor, in the form of 3 fully connected layers (a universal classifier).)

图.(Fig.)2(2).(.)输入图像后跟执行5×5卷积的特征图和2×2子采样图(An input image followed by a feature map performing a 5 × 5 convolution and a 2 × 2 sub-sampling map)
Partrice Simard博士在他的文章"应用于视觉文档分析的卷积神经网络的最佳实践"中,[3]提出了一种用于手写数字识别的CNN模型,该模型将卷积和子采样过程集成到单个层中.该模型以较高的分辨率提取简单的特征图,然后通过以2因子对图层进行二次采样将其转换为较粗糙的分辨率的更复杂的特征图.选择可训练内核的宽度以一个单位(奇数大小)为中心,以具有足够的重叠度而不会丢失信息(3太小,只有一个单位重叠度),但又没有冗余计算(7则是太大(5个单位或重叠率超过70%).填充输入(使其增大以使要素单元位于边框中心)不会显着提高性能.由于没有填充,两个子采样以及一个大小为5x5的可训练内核,每个卷积层将特征图的大小从n减少到(n-3)/2.由于此模型中使用的初始MNIST输入的大小为28x28,因此在2层卷积后生成整数大小的最接近值是29x29.经过2层卷积后,尺寸5x5的特征对于第三层卷积来说太小了.该神经网络的前两层可以视为可训练的特征提取器.然后,将可训练的分类器以2个完全连接的层的形式(通用分类器)添加到特征提取器.(Dr. Partrice Simard in his article “Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis,” [3] presented a different model of CNN for handwritten digit recognition which integrated convolution and sub-sampling processes in to a single layer. This model extracts simple feature maps at a higher resolution, and then converts them into more complex feature maps at a coarser resolution by sub-sampling a layer by a factor two. The width of the trainable kernel is chosen be centered on a unit (odd size), to have sufficient overlap to not lose information (3 would be too small with only one unit overlap), but yet to not have redundant computation (7 would be too large, with 5 units or over 70% overlap). Padding the input (making it larger so that there are feature units centered on the border) does not improve performance significantly. With no padding, a sub-sampling of two, and a trainable kernel of size 5x5, each convolution layer reduces the feature map size from n to (n-3)/2. Since the initial MNIST input using in this model is of size 28x28, the nearest value which generates an integer size after 2 layers of convolution is 29x29. After 2 layers of convolution, the feature of size 5x5 is too small for a third layer of convolution. The first two layers of this neural network can be viewed as a trainable feature extractor. Then, a trainable classifier is added to the feature extractor, in the form of 2 fully connected layers (a universal classifier).)
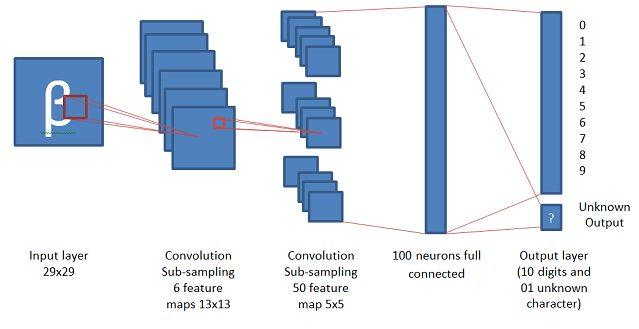
图.(Fig.)3(3).(.)基于Dr.Patrice Simard模型的卷积网络(A convolution network based on Dr. Partrice Simard’s model)<o:p>(<o:p>)
反向传播(Back Propagation)
反向传播是更新每一层权重变化的过程,该过程从最后一层开始,然后向后移动穿过各层,直到到达第一层.由于收敛速度较慢,因此不需要在网络库中使用标准的反向传播.取而代之的是,采用了LeCun博士在他的文章" Efficient BackProp" [2]中提出的称为"随机对角Levenberg-Marquardt方法"的技术.(Back propagation is the process that updates the change in the weights for each layer, which starts with the last layer and moves backwards through the layers until the first layer is reached. Standard back propagation does not need to be used in the network library because of slow convergence. Instead, the technique called “Stochastic diagonal Levenberg-Marquardt method”, which was proposed by Dr. LeCun in his article “Efficient BackProp” [2], has been applied.)
UNIPEN火车(The UNIPEN trainset)
经过大量的合作,许多研究机构和行业已经创建了UNIPEN标准和数据库[5].最初由NIST托管的数据分为两个分布,分别称为训练集(train_r01_v07集)和devset.自1999年以来,国际UNIPEN基金会(iUF)托管数据,目的是维护培训集的分发,并促进在研究和应用中使用在线手写.(In a large collaborative effort, a wide number of research institutes and industry have generated the UNIPEN standard and database [5]. Originally hosted by NIST, the data was divided into two distributions, dubbed the training set (train_r01_v07 set) and devset. Since 1999, the International UNIPEN Foundation (iUF) hosts the data, with the goal to safeguard the distribution of the training set and to promote the use of online handwriting in research and applications.)
由于UNIPEN训练集是来自不同研究机构的特定数据集的收集,因此这些数据集将使用某些特定程序进行分解.为了能够将我的系统的识别结果与已发表的研究进行比较,UNIPEN训练集用作对我的识别器的训练输入.但是,我的方法有些不同.已经发现这些数据集的结构中的一些一般要点可以创建一个过程,该过程可以在大多数情况下正确分解训练集中的所有数据集.(Due to UNIPEN training set is collection of particular datasets from different research institutes, these datasets are decomposed using some specific procedure. In order to be able to compare my system’s recognition results to published researches, the UNIPEN training set is used as training input to my recognizer. However, my approach is a little bit different; some general points in the structure of these datasets have been found to create a procedure which can decompose all datasets in the training set correctly in most cases.)
[5],[6],[15]中描述了UNIPEN格式. UNIPEN数据文件的格式具有关键字,这些关键字分为几个组,例如:强制性声明,数据文档,字母,词典,数据布局,单位系统,笔轨迹¸数据注释.为了获得信息并对这些关键字进行分类,已创建了基于上述组的类的集合,这些类可以帮助系统从数据文件中获取和分类所有必要的信息.(The UNIPEN format is described in [5],[6],[15]. The format of a UNIPEN data file has KEYWORDS which are divided to several groups like: Mandatory declarations, Data documentation, Alphabet, Lexicon, Data layout, Unit system, Pen trajectory¸ Data annotations. In order to get the information and categorize these keywords, a collection of classes based on the above groups have been created which can help the system to get and categorize all necessary information from data file.)
图像预处理和分割(Image pre-processing and segmentation)
分割是模式识别系统的重要一步.通常,将投影技术应用于文本图像中的单独的行,单词和字符.但是,如果字符混乱地组织起来将很困难.因此,已经开发了一种新算法来解决该问题.(Segmentation is an important step to pattern recognition system. Normally, projection techniques are applied to separate lines, words, and characters in a text image. However, it will be difficult if characters are organized in confusion. Therefore, a new algorithm has been developed to solve this issue.)
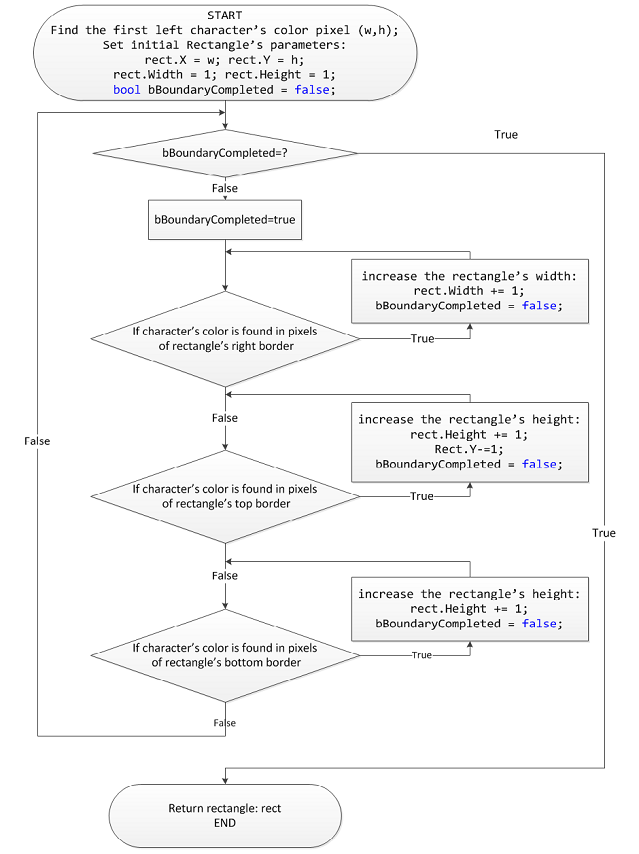
<o:p>(<o:p>)
图.(Fig.)4(4).(.)用于获取孤立角色的矩形边界的新算法(New algorithm for getting isolated character’s rectangle boundary).(.)
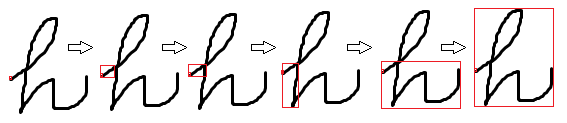
图.(Fig.)5(5).(.)孤立字符分割的步骤(Steps of isolated charactersegmentation)
图5展示了将上述算法应用于手写字符的示例.从角色的第一个左像素开始获取角色的矩形边界.边界从左到右,从上到下逐步扩展,直到边界可以包裹字符为止.可以应用类似的算法从最上方的像素获取字符的边界.(The figure 5 presents a sample of applying the above algorithm to a hand written character. Getting character’s rectangle boundary is started from the first left pixel of the character. The boundary is expanded step by step from left to right, from top to bottom until the boundary can wrap the character. A similar algorithm can be applied to get the character’s boundary from the topmost pixel.)
通过更改水平和垂直步长,该系统不仅可以获取孤立的字符,还可以获取单词或句子,而无需更改算法.(By changing horizontal and vertical steps, the system can get not only isolated characters but also words or sentences without changing algorithm.)

图.(Fig.)6(6).(.)单词分割和孤立字符分割的样本(Samples of word segmentation and isolatedcharacter segmentation)
将此技术与其他众所周知的分割方法一起使用可以帮助系统更好地识别复杂文本图像中的字符.(Using this technique together with other well-known segmentation methods can help the system to recognize characters better in complex text images.)
使用多神经网络的识别系统(Recognition System using multi neural networks)
卷积网络的识别结果对于小模式集合(例如数字,大写字母或小写字母等)确实是很高的.但是,当我们想要创建一个较大的神经网络时,它可以识别更大的集合,例如数字和英文字母(62字符),问题开始出现.找到一个优化且足够大的网络变得更加困难,通过大输入模式训练网络需要更长的时间.网络的融合语音较慢,特别是由于较大的不良书面字符,许多相似和易混淆的字符等,导致准确率显着下降.此外,假设我们可以创建一个足够好的网络,可以准确地识别英语字符,但肯定不能识别正确地使用特殊字符以使其输出集更大(俄语或中文字符),因为它没有扩展能力.因此,为非常大的模式分类器创建唯一的网络非常困难,而且可能是不可能的.(The recognition results of the convolution network are really high to small patterns collection such as digit, capital letters or lower case letters etc. However, when we want to create a larger neural network which can recognize a bigger collection like digit and English letters (62 characters) for example, the problems begin appear. Finding an optimized and large enough network becomes more difficult, training network by large input patterns takes much longer time. Convergent speech of the network is slower and especially, the accuracy rate is significant decrease because bigger bad written characters, many similar and confusable characters etc. Furthermore, assuming we can create a good enough network which can recognize accurately English characters but it certainly cannot recognize properly a special character outsize its outputs set (a Russian or Chinese character) because it does not have expansion capacity. Therefore, creating a unique network for very large patterns classifier is very difficult and may be impossible.)
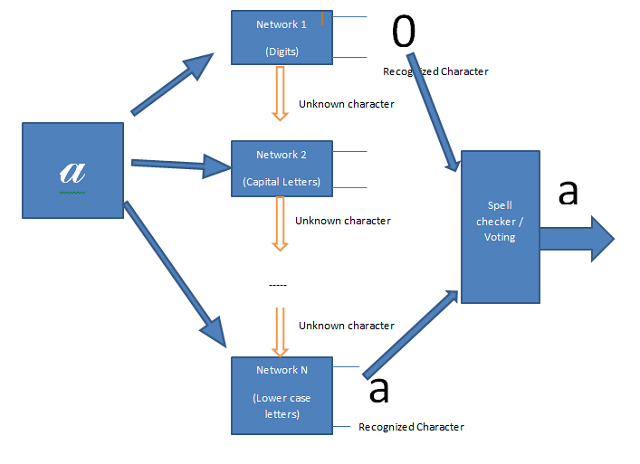
<o:p>(<o:p>)
图.(Fig.)7(7).(.)使用多神经网络的手写识别系统(A handwriting recognition systemusing multi neural networks)
针对上述问题提出的解决方案不是使用唯一的大型网络,而是可以使用多个较小的网络,这些网络对这些自己的输出集具有很高的识别率.除了正式的输出集(数字,字母…)之外,这些网络还有一个附加的未知输出(未知字符).这意味着,如果输入模式未被识别为官方输出的字符,它将被理解为未知字符(图3).对于像手写字符这样的大型模式集合,有太多类似的字符,在某些情况下,它们不仅会使机器产生混乱,而且还会使人感到困惑,例如:O,0和o; 9\4,g,q等.这些字符可能会使网络无法识别.通过在输出端使用附加的拼写检查器/投票模块,系统可以显着提高识别率.所有组件网络都可以识别输入模式.然后,这些输出(未知输出除外)将被设置为拼写检查器/投票模块的输入.该模块将基于先前识别的字符,内部词典和其他因素来决定哪一个将是最准确的识别字符.(The proposed solution to the above problems is instead of using a unique big network we can use multi smaller networks which have very high recognition rate to these own output sets. Beside the official output sets (digit, letters…) these networks have an additional unknown output (unknown character). It means that if the input pattern is not recognized as a character of official outputs it will be understand as an unknown character (Figure 3). For a large pattern collection like handwritten characters, there are so many similar characters which can make not only machine but also human confuse in some cases such as: O, 0 and o; 9, 4,g,q etc. These characters can make networks misrecognize. By using an additional spellchecker/voting module at the output, the system can significant increate recognition rate. The input pattern is recognized by all component networks. These outputs (except unknown outputs) then will be set as the inputs of the spellchecker/voting module. The module will bases on previous recognized characters, internal dictionary and other factors to decide which one will be the most accurated recognized character.)
该解决方案几乎克服了传统模型的局限性.新系统包括几个小型网络,这些网络很容易进行优化以获得最佳识别结果.训练这些小型网络所需的时间少于大型网络.特别是,新模型确实非常灵活和可扩展.根据需求,我们可以加载一个或多个网络.我们还可以在系统中添加新网络以识别新模式,而无需更改或重建模型.所有这些小型网络都具有可重用的能力,可用于另一个多神经网络系统.(This solution overcomes almost limits of the traditional model. The new system includes a several small networks which are simple for optimizing to get the best recognition results. Training these small networks takes less time than a huge network. Especially, the new model is really flexible and expandable. Depending on the requirement we can load one or more networks; we can also add new networks to the system to recognize new patterns without change or rebuilt the model. All these small networks have reusable capacity to another multi neural networks system.)
识别结果.(Recognition results.)
为了将库评估为手写识别系统,作者在MNIST和UNIPEN这两个不同的手写训练集上对库进行了实验.结果可以达到MNIST训练集[10]的准确率99%,UNIPEN数字的97%,UNIPEN数字和大写字母(1a,1b)的89%和UNIPEN小写字母(1c)的89%.[13] .(In order to evaluate the library to a handwritten recognition system, the author experiments the library on two different handwritten training sets are MNIST and UNIPEN. The results can reach to 99% accuracy rate to MNIST training set [10], 97% to UNIPEN digits, 89% to UNIPEN digits and capital letters (1a,1b) and 89% to UNIPEN lower case letters (1c)[13].)

图.(Fig.) 8(8).(.)使用UNIPEN训练集的网络训练接口(1c中的实验)(Networktraining interface using UNIPEN trainset (experiment in 1c))
图8是演示程序的网络培训界面.小写字母设置1c 48个纪元后,训练可以达到89%的准确性(第一次训练时间为30个纪元,第二个时间为18个纪元).在前30个时期之后,etaTrainingRate太小,这影响了网络训练性能.因此,第二次使用较大的初始etaTrainingRate =0.00045重新训练了网络.(The figure 8 is the network training interface of the demo program. The training can reach to 89% accuracy after 48 epochs to lower case letters set 1c (the first training time is 30 epochs, the second time is 18 epochs). After the first 30 epochs, the etaTrainingRate was too small which influenced to network training performance. So the network was trained again in second time with bigger initial etaTrainingRate = 0.00045.)
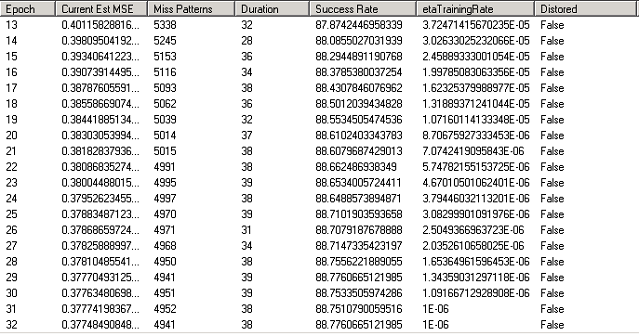
图.(Fig.)9(9).(.)62个时期后的网络培训参数统计(Statisticsof network training’ parameters after 62 epochs)
图9是数字和大写字母识别网络(36个输出网络)的网络培训参数统计.通过在反向传播过程中使用随机对角线Levenberg-Marquardt方法,网络的收敛语音比标准反向传播快得多.经过65个时期之后,网络的准确率可以达到89%.(Figure 9 is network training’s parameters statistics of the digits and capital letters recognition network (36 outputs network). By using Stochastic diagonal Levenberg-Marquardt method in back propagation process, the convergent speech of network becomes much faster than standard back propagation. After 65 epochs the accuracy rate of the network can reach to 89%.)
为了识别更大的字符集,例如英文字符(62个字符),已经创建了基于图5所示模型的识别系统.该系统是三个高识别率神经网络的组合:数字(97%),大写字母(89%)和小写字母(89%).该系统已通过使用附加的拼写检查器模块证明了其有效的识别能力.(In order to recognize a larger character set such as English characters (62 characters), a recognition system based on the model presented in figure 5 has been created. This system is a combination of three high recognition rate neural networks: digit (97%), capital letters (89%) and low case letters (89%). The system has proved its efficient recognition capacity by using an additional spell checker module.)
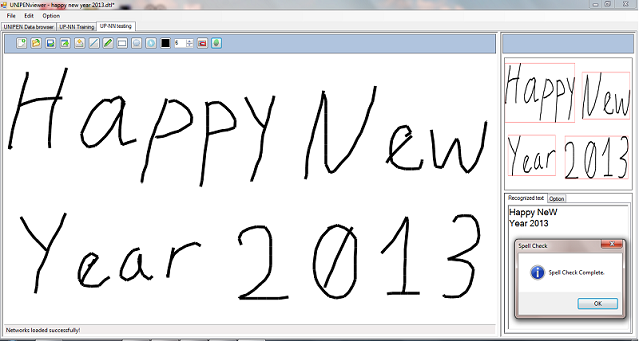
图.(Fig.)10(10).(.)使用多网络的鼠标绘图字符识别[13](Mousedrawing characters recognition using multi networks [13])
所有的库,演示程序,源代码和培训结果都可以在[13]下载.(All the library, demo program, source code and training results can be downloaded at [13].)
结论(Conclusion)
提出了一种利用人工卷积神经网络进行笔迹识别的方法.通过将卷积神经网络,弹性变形技术和随机对角线Levenberg-Marquardt方法相结合,实验神经网络可以取得积极的效果.此外,所提出的使用多成分神经网络的模型还具有为大型模式集(例如英文字符集等)创建高效且灵活的识别系统的能力.通过在输出端使用拼写检查器和投票模块,所提议的系统可以选择高识别率组成网络中最精确的字符.因此,它可以获得比传统的更好的识别结果.(The paper presented a method of handwriting recognition using artificial convolution neural network. By the combination of convolution neural network, elastic distortion technique and Stochastic diagonal Levenberg-Marquardt method, the experimental neural networks can reach to positive results. Furthermore, the proposed model using multi component neural networks also presented an ability of creating efficient and flexible recognition systems to large pattern sets such as English characters set etc. By using a spell checker and voting module at the output, the proposed system can choose the most accurated characters from high recognition rate component networks. Hence, it can get the better recognition results to a traditional one.)
参考文献(References)
Y. LeCun,L.Bottou,Y.Bengio和P. Haffner,“基于梯度的学习应用于文档识别”,IEEE会议录,第1卷. 86号1998年11月,第11页,第2278-2324页.[46页].(Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-Based Learning Applied to Document Recognition”, Proceedings of the IEEE, vol. 86, no. 11, pp. 2278-2324, Nov. 1998. [46 pages].)
-
Y. LeCun,L.Bottou,G.Orr和K. Muller,“有效的反向支撑”,<神经网络:交易技巧>,(G.Orr和Muller K.,编辑),1998年.[44页](2. Y. LeCun, L. Bottou, G. Orr, and K. Muller, “Efficient BackProp”, in Neural Networks: Tricks of the trade, (G. Orr and Muller K., eds.), 1998. [44 pages])
-
Patrice Y. Simard,Dave Steinkraus,John Platt,“卷积神经网络应用于可视化文档分析的最佳实践”,国际文档分析与识别会议(ICDAR),IEEE计算机协会,洛斯阿拉米托斯,第958-962页,2003年.(3. Patrice Y. Simard, Dave Steinkraus, John Platt, “Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis,” International Conference on Document Analysis and Recognition (ICDAR), IEEE Computer Society, Los Alamitos, pp. 958-962, 2003.)
-
Fabien Lauer,Ching Y. Suen和Gerard Bloch,“用于手写数字识别的可训练特征提取器”,Elsevier Science,2006年2月(4. Fabien Lauer, Ching Y. Suen and Gerard Bloch, “A Trainable Feature Extractor for Handwritten Digit Recognition”, Elsevier Science, February 2006)
-
I. Guyon,L.Schomaker,R.Plamondon,R.Liberman和S. Janet,“在线数据交换和识别器基准的Unipen项目”.在1994年10月,以色列耶路撒冷,第12届国际模式识别会议论文集,ICPR'94,第29-33页.(5. I. Guyon, L. Schomaker, R. Plamondon, R. Liberman, and S. Janet, “Unipen project of on-line data exchange and recognizer benchmarks”. In Proceedings of the 12th International Conference on Pattern Recognition, ICPR’94, pages 29–33, Jerusalem, Israel, October 1994. IAPRIEEE.)
-
Louis Vuurpijl,Ralph Niels,Merijn van Erp Nijmegen,“验证UNIPEN devset”.(6. Louis Vuurpijl, Ralph Niels, Merijn van Erp Nijmegen, “Verifying the UNIPEN devset”.)
-
Marc Parizeau,Alexandre Lemieux和ChristianGagné,“使用Unipen数据进行字符识别实验”. Parizeau等人,Proc. 9月10日至13日,西雅图,ICDAR 2001.(7. Marc Parizeau, Alexandre Lemieux, and Christian Gagné, “Character Recognition Experiments using Unipen Data”. Parizeau & al., Proc. of ICDAR 2001, September 10-13, Seatle.)
-
Yann LeCun博士的出版物清单. http://yann.lecun.com/exdb/publis/index.html(8. List of publications by Dr. Yann LeCun. http://yann.lecun.com/exdb/publis/index.html)
-
Mike O’Neill,“用于手写数字识别的神经网络”. http://www.codeproject.com/Articles/16650/Neural-Network-for-Recognition-of-Handwriting-Digi(9. Mike O’Neill, “Neural Network for Recognition of Handwritten Digits”. http://www.codeproject.com/Articles/16650/Neural-Network-for-Recognition-of-Handwritten-Digi)
-
Pham Viet Dung,“用于识别C#中的手写数字的神经网络”. http://www.codeproject.com/Articles/143059/Neural-Network-for-Recognition-of-Handwriting-Digi(10. Pham Viet Dung, “Neural Network for Recognition of Handwritten Digits in C#”. http://www.codeproject.com/Articles/143059/Neural-Network-for-Recognition-of-Handwritten-Digi)
-
Pham Viet Dung,“使用UNIPEN数据库的在线手写识别系统库”. http://www.codeproject.com/Articles/363596/Library-for-online-handwriting-recognition-system(11. Pham Viet Dung, “Library for online handwriting recognition system using UNIPEN database”. http://www.codeproject.com/Articles/363596/Library-for-online-handwriting-recognition-system)
-
Pham Viet Dung,” UPV – UNIPEN在线手写识别数据库查看器控件". http://www.codeproject.com/Articles/346244/UPV-UNIPEN-online-handwriting-recognition-database(12. Pham Viet Dung, “UPV – UNIPEN online handwriting recognition database viewer control”. http://www.codeproject.com/Articles/346244/UPV-UNIPEN-online-handwriting-recognition-database)
-
Pham Viet Dung,“使用多神经网络的大型模式识别系统”. http://www.codeproject.com/Articles/376798/Large-pattern-recognition-system-using-multi-neura(13. Pham Viet Dung,” Large pattern recognition system using multi neural networks ”. http://www.codeproject.com/Articles/376798/Large-pattern-recognition-system-using-multi-neura)
14.修改后的NIST(" MNIST")数据库(总计11,594 KB).(14. Modified NIST (“MNIST”) database (11,594 KB total).)
许可
本文以及所有相关的源代码和文件均已获得The Code Project Open License (CPOL)的许可。
C# Windows Win64 新闻 翻译