[译]突破游戏的简单AI
By robot-v1.0
本文链接 https://www.kyfws.com/ai/simple-ai-for-the-game-of-breakthrough-zh/
版权声明 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
- 13 分钟阅读 - 6275 个词 阅读量 0突破游戏的简单AI(译文)
原文地址:https://www.codeproject.com/Articles/37024/Simple-AI-for-the-Game-of-Breakthrough
原文作者:Kel_
译文由本站 robot-v1.0 翻译
前言
This article presents an implementation of a simple alpha-beta player for the board game of Breakthrough.
本文介绍了用于Breakthrough棋盘游戏的简单alpha-beta播放器的实现.
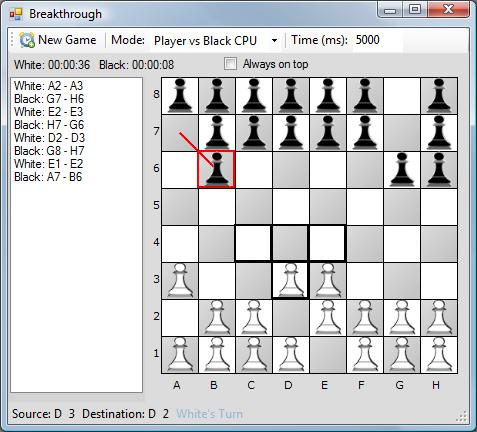
介绍(Introduction)
突破对AI玩家提出了一个有趣的挑战,因为该游戏仅包含一种类型的人物.因此,该游戏基于深度策略和对AI Player的深度搜索.为了使用Alpha-Beta调用树构建深度搜索,可以使用多种技术.本文介绍了这些技术的组合:迭代加深Alpha-Beta修剪(适用于Negamax);换位表;移动订购;和Null-Move启发式.它介绍了构建高效的.NET棋盘游戏引擎(突破游戏的评估功能)的几种技术.(Breakthrough presents an interesting challenge for an AI Player since the game consists only of a single type of figure; therefore, the game is based on deep tactics and deep search for an AI Player. In order to build a deep search with an Alpha-Beta call tree, several techniques can be used. This article presents a combination of those techniques: Iterative Deepening Alpha-Beta Pruning (for Negamax); Transposition Table; Move Ordering; and Null-Move Heuristic. It presents several techniques for building an efficient .NET board game engine, an evaluation function for the game of Breakthrough.)
本文仅提供了此类程序的原型,因此还远远不够完善.图形用户界面和引擎的一部分构建在ChessBin入门套件的顶部:(This article presents only a prototype of such a program, so it’s far from perfect. Parts of the graphical user interface and the engine were built on top of the ChessBin starter kit:) http://www.chessbin.com(http://www.chessbin.com) .(.)
背景(Background)
Breakthrough是Dan Troyka发明的抽象战略棋盘游戏.它赢得了2001年8x8游戏设计竞赛的冠军,尽管该游戏可以轻松扩展到更大的面板尺寸.本文介绍了该游戏在带有AI播放器的8x8板上的实现.(Breakthrough is an abstract strategy board game invented by Dan Troyka. It won the 2001 8x8 Game Design Competition, even though the game is trivially extendable to larger board sizes. This paper presents an implementation of this game for an 8x8 board with an AI Player.)
游戏是在正方形板上进行的,最初类似于跳棋.前两行充满了典当.选择首先要玩的玩家,然后玩家交替移动.(The game is played on a square board, initially similar to checkers; the first two rows are filled with pawns. A player to play first is chosen, and then the players alternate their moves.)
如果目标方块为空,则一块可以笔直或对角线向前移动一个空间.一个棋子可以移动到一个包含对手棋子的正方形中,并且前提是该正方形对角向前.对手的棋子被删除,而玩家的棋子代替了它.(A piece may move one space straight or diagonally forward if the target square is empty. A piece may move into a square containing an opponent’s piece if and only if that square is one step diagonally forward. The opponent’s piece is removed and the player’s piece replaces it.)
获胜者是第一个到达对手本垒打的玩家,离该玩家最远.抽奖是不可能的,因为棋子只能向前移动(或被捕获),并且某些棋子总是至少有一个向前的对角线移动可用.(The first player to reach the opponent’s home row, the one farthest from the player, is the winner. A draw is impossible since pieces can only move ahead (or be captured), and some pieces always have at least one forward diagonal move available.)
有关突破游戏的更多信息:(For more information on the Breakthrough game:) http://en.wikipedia.org/wiki/Breakthrough_(board_game)(*http://en.wikipedia.org/wiki/Breakthrough_(board_game)*) .(.)
AI播放器(AI Player)
突破对AI玩家提出了一个有趣的挑战,因为该游戏仅包含一种类型的人物.因此,该游戏基于深度策略和对AI Player的深度搜索.为了使用Alpha-Beta调用树构建深度搜索,可以使用多种技术.本文介绍了这些技术的组合:(Breakthrough presents an interesting challenge for an AI Player since the game consists only of a single type of figure; therefore, the game is based on deep tactics and deep search for an AI Player. In order to build deep search with an Alpha-Beta call tree, several techniques can be used. This paper presents a combination of those techniques:)
- 迭代加深Alpha-Beta修剪(适用于Negamax);(Iterative Deepening Alpha-Beta Pruning (for Negamax);)
- 换位表;(Transposition Table;)
- 移动订购;(Move Ordering;)
- 空移启发式.(Null-Move Heuristic.) Alpha-beta修剪是一种搜索算法,可减少要在搜索树中评估的节点数.该算法非常普遍,并用于许多不同的棋盘游戏机游戏引擎中.迭代加深增强功能允许搜索算法处理时间限制.通过换位表,移动顺序(以提供更好的Alpha-Beta修剪)和Null Move Heuristic(通过识别截止点来加快Negamax算法的速度)(游戏树中当前位置为点)来提高重新搜索和搜索的速度如此有利于一方移动,以至于另一方的最佳表现会避免这一点).(Alpha-beta pruning is a search algorithm with reduction of the number of nodes to evaluate in the search tree. The algorithm is very common, and used in a lot of different board game machine playing engines. Iterative Deepening Enhancement allows the search algorithm to handle time constraints. Re-search and search speed improvements are done with transposition tables, move ordering (in order to provide better Alpha-Beta pruning), and Null Move Heuristic (speeds the Negamax algorithm by identifying cutoffs, points in the game tree where the current position is so good for the side to move that the best play by the other side would have avoided it).)
引擎架构(Engine Architecture)
Breakthrough引擎分为两个明显分开的层:(The Breakthrough engine was built in two clearly separated layers:)
- 引擎本身,包含所有游戏算法,棋盘表示和评估功能;(the engine itself, containing all game algorithms, board representation, and evaluation function;)
- 图形用户界面,用于用户输入和可视化.(the graphical user interface, used for user input and visualization.) 董事会代表以非常直接的方式实现:代表当前职位的董事会类别;代表正方形状态的木板正方形;和用于存储游戏值的游戏块.预先生成了移动,并计算了有效的移动,以促进移动选择过程并使之更有效.(The board representation is implemented in a very straightforward way: a board class to represent current positions; a board square for the square state representation; and a game piece for storing the values of the game. Moves are pre-generated, and valid moves are computed in order to facilitate and make the move selection process more efficient.)
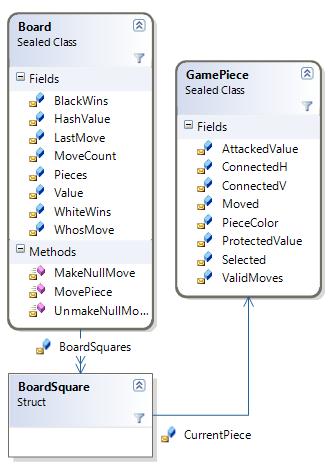
Breakthrough游戏引擎建立在.NET平台上(在带有Microsoft .NET的Windows上和带有Mono .NET的Linux/Mac上运行).为了尽可能高效地构建引擎,已经考虑了几种软件优化:(The Breakthrough game engine was built on the .NET platform (running on Windows with Microsoft .NET and on Linux/Mac with Mono .NET). In order to build an engine as efficient as possible, several software optimizations have been considered:)
- 以简单的一维数组(因此,对于8x8板为64个板正方形)的板表示形式,并具有板的快速副本,以便生成更快的移动(简单的块副本);(a board representation in a simple one dimensional array (therefore, 64 board squares for an 8x8 board) with a fast copy of a board in order to generate faster moves (simple chunk copy);)
- 面向对象的体系结构尽可能简单;对于实时约束,甚至建议避免使用它,因此几乎所有操作都是使用静态方法完成的;(the object-oriented architecture as simple as possible; even avoiding it is recommended for the real-time constraints, therefore almost everything was done with static methods;)
- 可见性修改器更改为(the visibility modifiers changed to)
internal和(and)private尽可能允许CLR编译器内联;(wherever possible, allowing the CLR compiler to inline as much as possible;) - 分析密集(实时)部分的复杂性以简化实现(例如,可能的棋盘/动作生成,棋盘复制,值分配).(analyzing the complexity of intensive (real-time) sections in order to simplify the implementation (e.g., the possible boards/moves generation, board copying, values assignments).) 通过这些优化,已经实现了一些显着的改进,并且测得了40%的搜索改进.(With those optimizations, some significant improvements have been achieved and 40% search improvement has been measured.)
评估功能(Evaluation Function)
评估功能用于评估板的状态,以便比较不同的可能运动.系统内置的函数是线性的,可以用以下公式描述:(The evaluation function is used to evaluate the state of the board in order to compare different possible movements. The function built into the system is linear, and can be described with the following formula:)
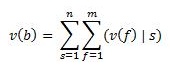
哪里:(Where:)
- s是板的正方形状态;(s is the board square state;)
- f是特征;(f is the feature;)
- n是平方数(8x8板为64);(n is number of squares (64 for the 8x8 board);)
- m是评估函数中的特征数;(m is the number of features in the evaluation function;)
- v(b)是董事会的价值;(v(b) is the value of the board;)
- v(f)| s是给定板为正方形状态时要素的值.(v(f)|s is the value of a feature, given the board square state.) 为了实现当前评估功能而使用的功能:(The features used in order to implement the current evaluation function:)
|功能名称(Feature Name)
|功能角色/说明(Feature Role/Description)
| 获奖位置(Winning Position) |
|赋予获胜地位的功能.在突破中,仅通过对手最远行的棋子位置(例如,第一行的黑色棋子)来检测获胜位置.(Feature that valorizes a winning position. In Breakthrough, the winning position is simply detected by a position of a pawn on the opponent’s farthest row (e.g., black pawn on a row 1).)
| |件几乎赢了(Piece Almost Win Value)
|预测P-1个动作的获胜位置的功能(通过查看接下来的三个可能动作).(Feature that predicts a winning position in P - 1 moves (by looking on the three next possible moves).)
| |单件价值(Piece Value)
|在船上珍贵一件/当量的功能(Feature that valorizes a piece/pawn on board)
| |件危险值(Piece Danger Value)
|一块的位置值,遵循以下公式:row * anger_value,对于黑白玩家对称.(Positional value of a piece, following the formula: row * danger_value, symmetrically for black and white players.)
| |高危险值(Piece High Danger Value)
|最高危险值的特征,对于最后一行的危险-1.(Feature for highest danger value of a piece, for a piece on a last row - 1.)
| |计件进攻价值(Piece Attack Value)
|此值加权对典当的攻击(累积的).(This value weights an attack on a pawn, cumulative.)
| |件保护值(Piece Protection Value)
|此值加权对典当的保护(累加).(This value weights a protection of a pawn, cumulative.)
| |水平连接(Connection Horizontal)
|代表两个棋子水平连接的特征.(Feature that characterizes a two pawns horizontal connection.)
| |垂直连接(Connection Vertical)
|代表两个棋子垂直连接的特征.(Feature that characterizes a two pawns vertical connection.)
| |件流动性价值(Piece Mobility Value)
|评估一件有效步数的功能.(Feature that valorizes the number of valid moves for a piece.)
| |列孔值(Column Hole Value)
|惩罚没有玩家棋子的列(空列)的功能.(Feature that penalizes the columns where no player’s pawns are present (empty columns).)
| |房屋地面价值(Home Ground Value)
|该功能可对初始家庭地面行上的棋子进行增值.(Feature that valorizes the pawns on the initial home ground row.)
|
以下是用于执行评估功能的伪代码(简化的C#代码).系统内的实现分为两个功能,以提高可读性:(Following is a pseudo-code (simplified C# code) for the implementation of the evaluation function. The implementation within the system was split into two functions for easier readability:)
int GetValue(board, ColorMoving){
for (byte x= 0; x < 8; x++){
for (byte y = 0; y< 8; y++){
BoardSquare square = board. GetPosition(x,y);
if (NoPieceOnSquare) continue;
if (square.CurrentPiece.PieceColor ==White)
{
Value += GetPieceValue(square, x, y);
if(y ==7)board.WhiteWins = true;
if(y == 0)Value += HomeGroundValue;
if (column > 0) ThreatA = (board[GetPosition(y - 1, 7).NoPieceOnSquare);
if (column < 7) ThreatB = (board.GetPosition(y + 1, 7).NoPieceOnSquare);
if (ThreatA && ThreatB) // almost win
board.Value += PieceAlmostWinValue;
} else{
// Same for black, with inverted signs for NegaMax
}
}
if (WhitePiecesOnColumn == 0)Value -= PieceColumnHoleValue;
if (BlackPiecesOnColumn == 0)Value += PieceColumnHoleValue;
}
// if no more material available
if (RemainingWhitePieces == 0) board.BlackWins = true;
if (RemainingBlackPieces == 0) board.WhiteWins = true;
// winning positions
if (board.WhiteWins)Value += WinValue;
if (board.BlackWins)Value -= WinValue;
}
int GetPieceValue(square, Column, Row)
{
int Value = PieceValue;
var Piece = square.CurrentPiece;
// add connections value
if (Piece.ConnectedH) Value += PieceConnectionHValue;
if (Piece.ConnectedV) Value += PieceConnectionVValue;
// add to the value the protected value
Value += Piece.ProtectedValue;
// evaluate attack
if (Piece.AttackedValue > 0)
{
Value -= Piece.AttackedValue;
if (Piece.ProtectedValue == 0)
Value -= Piece.AttackedValue;
}else{
if (Piece.ProtectedValue != 0){
if (Piece.PieceColor == White){
if (Row == 5) Value += PieceDangerValue;
else if (Row == 6) Value += PieceHighDangerValue;
}else{
if (Row == 2) Value += PieceDangerValue;
else if (Row == 1) Value += PieceHighDangerValue;
}
}
}
// danger value
if (Piece.PieceColor ==White)
Value += Row * PieceDangerValue;
else
Value += (8-Row) * PieceDangerValue;
// mobility feature
Value += Piece.ValidMoves.Count;
return Value;
}
搜索算法/启发式(Search Algorithm / Heuristics)
总览(Overview)
该系统的搜索算法是在Negamax Alpha-Beta搜索的基础上构建的,并增强了:(Search algorithm for the system was built on the basis of Negamax Alpha-Beta search, enhanced with:)
- 迭代加深,以便控制执行时间;(Iterative-Deepening in order to have control of the execution duration;)
- 换位表(需要更快地重新搜索ID Alpha Beta);(Transposition table (required for faster re-search of ID Alpha Beta);)
- 完成搬家定单;(Complete move ordering;)
- 空移正向修剪启发式.(Null-move forward pruning heuristic.)
迭代加深的Alpha测试版(Iterative-Deepening Alpha-Beta)
由于深度优先方法不适用于时间限制,因此通过迭代加深增强了Negamax Alpha-Beta搜索.因此,为了便于在每个级别上进行搜索,将需要转置表.(Since the the depth first methodology is not suitable for time-constraints, the Negamax Alpha-Beta search was enhanced with iterative-deepening. Therefore, to facilitate re-search on each level, the transposition table would be necessary.)
以下伪代码说明了该方法.我们可以看到,转位表在每个动作的开始都被清除,并广泛用于每个级别的重新搜索:(The following pseudo-code illustrates the approach. We can see that the transposition table is cleared in the beginning of every move, and extensively used for re-search on each level:)
Board IterativeDeepeningAlphaBeta(Board, MaxDepth, WhosMove)
{
//Empty the Transposition Table
TT.Table = new TranspositionTable();
Depth = 1;
Watch.Reset();
Watch.Start();
for (Depth = 1; Depth < MaxDepth; Depth++)
{
LastBoard = AlphaBetaTTRoot(Board, Depth, WhosMove, EnableNullMoves);
if (Watch.ElapsedMilliseconds >= TimeToMoveMs || LastBoard == null)
break; // timeout
BestBoard = LastBoard;
}
Watch.Stop();
return BestBoard;
}
换位表(Transposition Table)
在Breakthrough中,换位表被证明对于检测重复位置以及迭代加深非常有效(研究几乎是立即完成的).(In Breakthrough, the transposition table proved to be very effective for detecting duplicate positions as well as for Iterative Deepening (re-search is almost done instantaneously).)
该算法中使用了Zobrist哈希来创建转置表.根据原始研究,随机生成的数字越好,实际分布越好,并且可以避免冲突.该引擎是用C#构建的,它提供了一种生成伪随机数的方法.从有限的一组数字中以相等的概率选择伪随机数.所选数字不是完全随机的,因为使用了确定的数学算法来选择它们,但是出于实际目的,它们足够随机.(Zobrist hashing was used in the algorithm in order to create the transposition table. According to original research, the better the random generated numbers are, the better would be the actual distribution and collisions could be avoided. The engine was built in C#, which offers a way to generate pseudo-random numbers. Pseudo-random numbers are chosen with equal probability from a finite set of numbers. The chosen numbers are not completely random because a definite mathematical algorithm is used to select them, but they are sufficiently random for practical purposes.)
但是,为了确保更好的随机数分布质量,Musoto Matsumoto和Takuji Nishimura在1997年开发的Mersenne Twister伪随机数生成器基于有限二进制域上的矩阵线性递归,增强了Zobrist哈希.它提供了快速生成非常高质量的伪随机数的功能,它是专门为纠正旧算法中发现的许多缺陷而设计的.它的设计考虑了各种现有发电机的缺陷.(However, to ensure better quality of random number distribution, the Zobrist hashing was enhanced with the Mersenne Twister pseudo-random number generator, developed in 1997 by Makoto Matsumoto and Takuji Nishimura, that is based on a matrix linear recurrence over a finite binary field. It provides for fast generation of very high-quality pseudorandom numbers, having been designed specifically to rectify many of the flaws found in older algorithms. It is designed with consideration on the flaws of various existing generators.)
完成搬家订购(Complete Move Ordering)
为了增加对alpha-beta算法的修剪,使用了移动排序技术.由于评估功能本身是用最简单,最有效的方法设计的,因此通过检索所有可能的板并按值对它们进行排序,可以完全完成移动排序.以下伪代码显示了排序:(In order to increase the pruning for alpha-beta algorithm, a move ordering technique was used. Since the evaluation function itself was designed in the simplest and most efficient way, the move ordering was done completely by retrieving all possible boards and sorting them by the value. The following pseudo-code shows the ordering:)
int AlphaBetaTT(...)
{
Successors = GetPossibleBoards(WhosMove, Board);
if (Total Successors == 0)
return Board.Value;
// sort the boards in order to have better pruning
Successors.SortByValue();
//continue with normal Alpha-Beta ...
}
空动启发式(Null-move Heuristic)
Null-move正向修剪启发式算法增强了该算法,极大地提高了搜索深度.为了避免Zugzwang的位置,对该算法实施了一些限制:(The algorithm was enhanced with Null-move forward pruning heuristic, greatly improving the depth of search. In order to avoid Zugzwang positions, several restrictions were implemented to the algorithm:)
- 移动的一侧剩余少量零件;(the side to move has a small number of pieces remaining;)
- 搜索中的上一个动作也是空动作.(the previous move in the search was also a null move.) 以下伪代码说明了突破的Null-Move方法:(The following pseudo-code illustrates the Null-Move approach for Breakthrough:)
int AlphaBetaTT(Board, Depth, Alpha, Beta, WhosMove, AllowNullMove)
{
// (...) Transposition table ...
if (Depth >= 2 && Beta < Infinity &&
AllowNullMove && Board.Pieces > 10) {
// Try null move
int r = 1;
if (Depth >= 4) r = 2;
else if (Depth >= 7) r = 3;
Board.MakeNullMove();
int value = -AlphaBetaTT(Board, Depth - r - 1, -Beta,
-Beta + 1, WhosMove, false);
Board.UnmakeNullMove();
if (value >= Beta) {
TT.StoreEntry(HashValue, value,Upperbound, Depth);
return value;
}
}
// (...) Move ordering & Alpha-Beta ...
}
结果(Results)
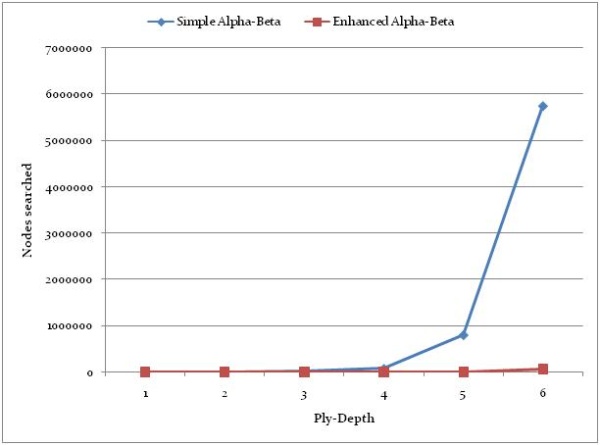
为了评估本文提出的算法对搜索的改进,将带有Negamax的简单Alpha-Beta与提出的方法进行了比较. AI播放器设置为黑色播放,从初始位置开始进行相同的移动(白色A2-A3),并且AI播放器以不同深度进行搜索.测量了搜索到的节点的时间和数量.(In order to evaluate the search improvement made with the algorithm presented in the paper, a simple Alpha-Beta with Negamax was compared to the presented approach. The AI Player was set to play black, the same move (White A2-A3) from the initial position was done, and the AI Player performed a search with a different depth. Times and number of nodes searched were measured.)
下表是针对不同搜索深度测得的结果. A1是一种简单的搜索算法,而A2是一种增强的搜索算法:(Below is the table with the results measured for a different depth of search. A1 is a simple search algorithm, and A2 is an enhanced one:)
|层深度(Ply-Depth)
|A1-节点(A1 - Nodes)
|A1-时间(A1 - Time)
|A2-节点(A2 - Nodes)
|A2-时间(A2 - Time)
|节点展示次数.(Nodes Impr.)
|时间展示.(Time Impr.)
|截断展示次数(Cutoffs Impr.)
| 2 |
|192
|12
|25
|29
|167
|-17
|86,98%
| |3
|1152
|59
|115
|58
|1037
|1
|90,02%
| |4
|12389
|358
|526
|225
|11863
|133
|95,75%
| |5
|77288
|3502
|2564
|837
|74724
|2665
|96,68%
| |6
|804367
|23152
|3568
|1090
|800799
|22062
|99,56%
| |7
|5751094
|245487
|62536
|22491
|5688558
|222996
|98,91%
|
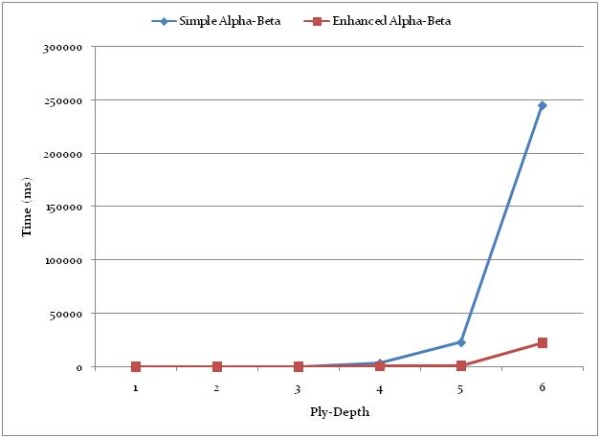
结论(Conclusions)
换位表,空动作启发式和移动顺序可在"突破"游戏中极大地提高搜索深度,在"突破"游戏中,战术和策略最为重要.实验表明,通过简单的Alpha-Beta修剪就可以完成完整的移动排序,并且该系统在合理的时间内实现了99%以上的截止.(Transposition table, null moves heuristic, and move ordering significantly improve the search depth in a game of Breakthrough, where tactics and strategies are most important. The experiments have shown that complete move ordering with a simple Alpha-Beta pruning is possible, and the system achieved 99+% cutoffs within a reasonable time.)
为了获得更好的结果,可以对算法进行并行化,特别是因为该算法符合标准Alpha-Beta,并且已经进行了大量研究.(In order to achieve even better results, the parallelization of the algorithm can be done, especially since the algorithm conforms to a standard Alpha-Beta and there is a lot of research that has already been done.)
历史(History)
- 2009年6月5日-该文章的第一版.(5 June 2009 - First version of the article.)
许可
本文以及所有相关的源代码和文件均已获得The Code Project Open License (CPOL)的许可。
C# .NET Windows VS2008 Dev Architect 新闻 翻译