揭开3D数学的大门:第一部分-矩阵乘法(译文)
By robot-v1.0
本文链接 https://www.kyfws.com/games/blowing-the-doors-off-d-math-part-i-matrix-multipl-zh/
版权声明 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
- 14 分钟阅读 - 6826 个词 阅读量 0揭开3D数学的大门:第一部分-矩阵乘法(译文)
原文地址:https://www.codeproject.com/Articles/1182724/Blowing-the-Doors-Off-D-Math-Part-I-Matrix-Multipl
原文作者:CMalcheski
译文由本站 robot-v1.0 翻译
前言
Thinking outside the box can result in critical performance gains
开箱即用的思维可能会导致关键的性能提升
The code presented in this article is ASM (assembly language) and can easily adaptable to any language that supports SSE, in particular AVX. If basic matrix multiplication is any indicator, huge performance gains result. I created my own version of the XMMatrixMultiply function and saw a 657% speed improvement. In a 3D scene, XMMatrixMultiply is called a lot. Through this article I use matrix multiplication to demonstrate the difference in speed.
本文介绍的代码是ASM(汇编语言),可以轻松地适应任何支持SSE的语言,尤其是AVX.如果基本矩阵乘法是任何指标,那么将获得巨大的性能提升.我创建了自己的XMMatrixMultiply函数版本,看到速度提高了657%.在3D场景中,XMMatrixMultiply被称为很多.通过本文,我使用矩阵乘法来演示速度的差异.
马虎的捷径或闪亮的品质?(Sloppy Shortcuts or Shining Quality?)
软件开发机构(尤其是学术界)一直在懒惰和避免工作的祭坛上崇拜.使用别人的图书馆!不要重新发明轮子!让编译器去做!教条有一个使自己永存的恶习,不断地降低输出质量,直到最终产品变得如此之小以至于无法有效使用为止.(The software development establishment (particularly academia) has always worshipped at the altar of laziness and avoiding work. Use somebody else’s library! Don’t reinvent the wheel! Let the compiler do it! Dogma has a nasty habit of perpetuating itself, steadily degrading output quality further and further until the end product becomes so diminished as to be effectively unusable.)
曾经有一段时间,技能,知识和工艺是受人尊敬的传统.对工艺的骄傲是懒惰和伪劣捷径的典型对立面.如果将这些概念应用于当今的3D数学,将会发生什么?(There was a time when skill, knowledge, and craftsmanship were honored traditions. Pride in workmanship was the quintessential opposite of laziness and shoddy shortcuts. What happens if these concepts are applied to the 3D math of today?)
如果基本矩阵乘法是任何指标,那么将获得巨大的性能提升.我创建了自己的版本(If basic matrix multiplication is any indicator, huge performance gains result. I created my own version of the) XMMatrixMultiply 功能,速度提高了657%.在3D场景中,(function and saw a 657% speed improvement. In a 3D scene,) XMMatrixMultiply 被称为(is called a)**很多.(lot.)**将它加速6.57倍(在我的测试机上测得).那只是数学库中的一个函数,其中有42个仅用于矩阵处理的附加函数.(Speeding it up 6.57 times (as it measured on my test machine) is going to be noticed. And that’s just one function in a math library that has 42 additional functions devoted to matrix handling alone.)
内部伪代码(Pseudo-Code Inside)
本文中介绍的代码是ASM(汇编语言),其主要原因是,与过度修饰和复杂的内部函数相比,它易于阅读和遵循.出于与概念相关的目的,使用ASM比尝试混淆长长的内在函数列表要干净得多.本文中的代码很容易适应任何支持SSE的语言,尤其是AVX.(The code presented in this article is ASM (assembly language), for the primary reason that it’s much easier to read and follow than overly-adorned and complicated intrinsics. For the purposes of relating a concept, using ASM is much cleaner than trying to muddle through long lists of intrinsics. The code herein is easily adaptable to any language that supports SSE, in particular AVX.)
本文随附了完整的.DLL,.LIB,C ++头文件和说明,可以下载.的(A complete .DLL, .LIB, C++ header file, and instructions accompany this article and are available for download. The) PCC_XMMatrixMultiply 该下载中包含本文介绍的功能.它采用与输入相同的输入并提供相同的输出.(function presented in this article is included in that download. It takes the same input and provides the same output as the) DirectXMath 功能(function) XMMatrixMultiply .(.)
在矩阵之外思考(Thinking Outside the Matrix)
SSE(流式SIMD [单指令多数据]扩展)是一种混合祝福.它可以在很短的时间内处理大量数据.从理论上讲,使用SSE足够简单,但真正的挑战在于准确跟踪在大规模操作期间所有数据的运行情况.(SSE (Streaming SIMD [Single Instruction Multiple Data] Extensions) is a mixed blessing. It does a lot of work with a lot of data in a very short time. Working with SSE is simple enough in theory, but the real challenge lies in keeping track of exactly what’s going on with all that data during extensive operations.) 随着SSE逐渐演变成AVX(高级矢量扩展),AVX2和AVX-512,已经添加了越来越多的功能,这些功能非常有助于矢量数学.但是,对这些进程的支持取决于CPU版本.本文假定AVX支持256位YMM寄存器,其中包含四个"槽"的双精度浮点值.(As SSE has evolved into AVX (Advanced Vector Extensions), AVX2, and AVX-512 beyond that, more and more functionality has been added that’s highly conducive to vector math. However, support for these processes depends on the CPU version. This article assumes AVX support with 256-bit YMM registers, holding four “slots” of double-precision float values.)
少即不多(Less is Not More)
一个普遍的误解,尤其是在使用高级语言时,是减少指令数量从本质上等同于更好,更快的代码.事实并非如此.十个逻辑按位指令将在单次存储器访问完成的时间内完成.指令数量无关紧要;少的指令数可能很慢,也可能很快,这全都取决于要编码的指令.最后,重要的是功能在整体上运行的速度.这是这里概述的功能的基础-指令数量可能看起来令人生畏,但是当每条指令执行五个或六个CPU周期时,整个功能在整个DirectXMath花费不到执行.(A common misconception, especially when using high level languages, is that reducing the instruction count inherently equates to better, faster code. This is far from being the case. Ten logical bitwise instructions will execute in a fraction of the time it takes a single memory access to complete. The number of instructions is irrelevant; a low instruction count can be slow or it can be fast, all depending on the instructions being coded. In the end, all that matters is how fast a function runs on the whole. This is the basis for the function outlined here – the instruction count may look intimidating, but when each one executes in five or six CPU cycles, the function as a whole screams through to completion in a fraction of the time it takes the DirectXMath equivalent to execute.)
内存不足(Stay Out of Memory)
最大化性能的真正关键是避免内存不足.在CPU的寄存器中移动数据的速度非常快,但是使用内存来辅助处理将严重拖累两个矩阵相乘的任务(或使用SSE进行的任何其他操作).(The real key to maximizing performance is to avoid memory hits. Moving data around the CPU’s registers is mega-fast, but using memory to assist the process will seriously drag down the task of multiplying two matrices (or any other operation using SSE).) 在理想情况下,假设使用YMM寄存器使用双精度浮点值(使用XMM进行单精度浮点将以较低的精度产生相同的结果),则矩阵乘法将仅涉及十二次内存访问操作.将进行8次读取,以将乘法器矩阵M1的四行和被乘数矩阵M2的四行移入其目标寄存器.对存储器的最后四次访问将被写入,以输出最终结果矩阵.其他所有事情都将在SSE寄存器中发生.(In a perfect world, matrix multiplication would involve only twelve memory access operations, assuming double precision float values working with YMM registers (single precision floats using XMM would yield the same result with lower precision). There would be 8 reads, to move the four rows of the multiplier matrix M1 and the four rows of the multiplicand matrix M2 into their target registers. The final four accesses to memory would be writes, to output the final result matrix. Everything else would occur within the SSE registers.) 能做到吗?(Can this be done?)
翻转M2(Flipping M2)
从表面上看,矩阵乘法的性质妨碍了SSE指令的有效使用,因为需要处理第二个矩阵(M2,被乘数)中的列而不是行.但是,如果M2可以在从左上角到右下角的假想对角轴上翻转180度,则该矩阵的四列变为行,然后SSE寄存器可以完全访问它们.(The nature of matrix multiplication, on its face, precludes the efficient use of SSE instructions because of the need to work with columns, not rows, in the second matrix (M2, the multiplicand). However, if M2 can be flipped 180 degrees on an imaginary diagonal axis running from the upper left to lower right corners, then the four columns of that matrix become rows and are then fully accessible to the SSE registers.)
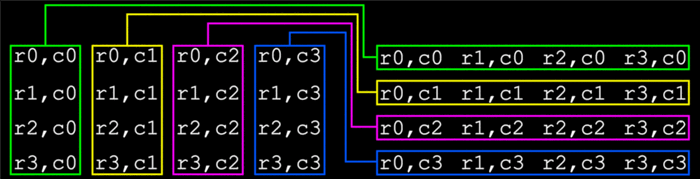
在翻转过程中,(During the flip process,) M2[r0,c0] ,(,) M2[r1,c1] ,(,) M2[r2,c2] 和(, and) M2[r3,c3] 不要动对于其余的值,可以直接交换寄存器内容以完成翻转.(don’t move. For the remainder of the values, register contents can be exchanged directly to complete the flip.)
SSE使用两种基本数据类型:(SSE works with two basic data types:)包装好的(packed),在YMM寄存器的每个64位插槽中都放置了不同的值,或者(, where distinct values are placed into each of the 64-bit slots of a YMM register, or)标量(scalar),仅使用低64位.翻转M2的过程使用两种类型的指令.(, where only the low 64 bits are used. The process of flipping M2 uses both types of instructions.)
的(The) vpermq 指令用于旋转YMM寄存器的内容,以便将要使用的每个连续值都移到其寄存器的低64位.在那里,标量指令可用于交换寄存器内容.通过使用这种方法,不会丢失或覆盖任何数据,也不会访问内存,并且可以非常快速地完成翻转M2的任务.指令数可能看起来很高,但是总执行时间却非常短.(instruction is used to rotate the content of YMM registers so that each successive value being worked with is moved to the low 64 bits of its register. Once there, scalar instructions can be used to exchange register contents. By using this approach, no data is lost or overwritten, there is no memory access, and the task of flipping M2 can be completed very quickly. The instruction count may seem high, but the total execution time is extremely low.)
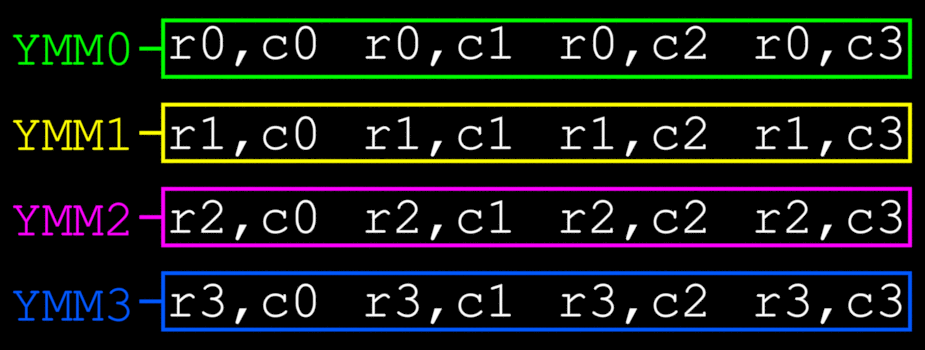
首先,此示例将M1行0-3加载到(First, this example loads M1 rows 0-3 into) YMM0 ,(,) YMM1 ,(,) YMM2 和(, and) YMM3 . M2的行被加载到(. The rows of M2 are loaded into) YMM4 ,(,) YMM5 ,(,) YMM6 和(and) YMM7 .(.)
(此代码假定在函数输入时,RCX指向M1,RDX指向M2.这是将M1和M2作为参数传递时的标准调用约定.)((This code assumes that on entry to the function, RCX points to M1 and RDX points to M2. This is standard calling convention when M1 and M2 are passed as parameters.))
vmovapd ymm4, ymmword ptr [ rdx ] ; Load M2 [ r0 ] into ymm4
vmovapd ymm5, ymmword ptr [ rdx + 32 ] ; Load M2 [ r1 ] into ymm5
vmovapd ymm6, ymmword ptr [ rdx + 64 ] ; Load M2 [ r2 ] into ymm6
vmovapd ymm7, ymmword ptr [ rdx + 96 ] ; Load M2 [ r3 ] into ymm7
将M2加载到内存后,即可开始翻转过程.必须进行以下交流:(With M2 loaded into memory, the flipping process can begin. The following exchanges have to be made:)
r1, c0 : r0, c1
r2, c0 : r0, c2
r3, c0 : r0, c3
r2, c1 : r1, c2
r3, c1 : r1, c3
r3, c2 : r2, c3
总共需要进行六次交换.(A total of six exchanges need to be made.)
要记住的一个重要事项是CPU的低位优先操作.第3列的值将占据其各自的YMM寄存器的高64位;列0的值将占据低64位.这与在图表中查看矩阵的方式相反. YMM的实际内容如下:(An important item to remember is the little-endian operation of the CPU. Column 3 values will occupy the high 64 bits of their respective YMM registers; column 0 values will occupy the low 64 bits. This is reversed from how the matrix is viewed in diagrams and figures. Actual YMM contents are as follows:)

每个要交换的值都必须旋转到其YMM寄存器的低端位置–位63-0.对于第一次交流,((Each value to be swapped must be rotated into the low end position of its YMM register – bits 63-0. For the first exchange, () r1,c0 与(with) r0,c1 )的值(), the value for) r1,c0 已位于的低64位(is already in the low 64 bits of) YMM5 .(.) YMM4 需要向右旋转64位,才能移动(needs a 64 bit rotation right, to move the value for) r0,c1 进入其低64位.(into its low 64 bits.)
vpermq ymm4, ymm4, 39h ; Rotate ymm4 right 64 bits
movsd xmm8, xmm5 ; Move r1c0 to hold
movsd xmm5, xmm4 ; Move r0c1 to r1c0 in xmm5
movsd xmm4, xmm8 ; Move r1c0 to r0c1
SSE指令仅将低128位或XMM寄存器部分用于标量移动,因为仅使用63-0位.使用YMM寄存器作为XMM的超集时,可以达到预期的效果:即使引用了XMM寄存器,也可以在YMM寄存器的低64位之间移动值.(SSE instructions use only the low 128 bits, or the XMM register portion, for scalar moves since only bits 63-0 are worked with. With YMM registers being a superset of XMM, the desired effect is achieved: values are moved between the low 64 bits of YMM registers, even though XMM registers are referenced.)
旋转后(After the rotation,) r0c1 (在((in) ymm8 )已向右旋转,因此() has been rotated right so that) c1 现在位于第63-0位.下一个向右旋转64位的位置(is now in bits 63-0. The next rotation to the right 64 bits places) r0c2 转换为63-0位,该过程可以重复进行交换(into bits 63-0 and the process can repeat to exchange) r0,c2 与(with) r2,c0 :(:)
vpermq ymm4, ymm4, 39h ; Rotate ymm4 right 64 bits
movsd xmm8, xmm6 ; Move r2c0 to hold
movsd xmm6, xmm4 ; Move r0c2 to r2c0
movsd xmm4, xmm8 ; Move hold to r0c2
重复此过程,使用(This process repeats, using) YMM7 交流(to exchange) r3,c0 与(with) r0,c3 . M2值交换的其余部分以相同的方式进行.本文结尾处的最终代码包含整个过程.(. The remainder of the M2 value exchanges proceed the same way. The final code at the end of the article contains the entire process.)
执行乘法(Executing the Multiplication)
一旦M2被翻转,就可以执行实际的乘法运算.这是实时节省的地方,因为仅需要执行四个乘法运算.由于现在M2的每一列在YMM寄存器中是连续的,因此可以应用直接乘法.(Once M2 has been flipped, the actual multiplication can be performed. This is where the real time savings occur, because only four multiplication operations need to be performed. Since each column of M2 is now contiguous in a YMM register, direct multiplication can be applied.)
首先,将M1加载到(First, M1 is loaded into) YMM0 通过(through) YMM3 :(:)
vmovapd ymm0, ymmword ptr [ rcx ] ; Load row 0 into ymm0
vmovapd ymm1, ymmword ptr [ rcx + 32 ] ; Load row 1 into ymm1
vmovapd ymm2, ymmword ptr [ rcx + 64 ] ; Load row 2 into ymm2
vmovapd ymm3, ymmword ptr [ rcx + 96 ] ; Load row 3 into ymm3
首先,乘以(First, multiply) M1[r0] ,加载到(, loaded into) YMM0 ,由(, by) M2[c0] ,加载到(, loaded into) YMM4 :(:)
vmulpd ymm8, ymm0, ymm4 ; Set M1r0 * M2c0 in ymm8
结果(With the result of) M1[r1] * M2[c0] 现在存在(now present in) YMM8 ,下一个挑战是积累(, the next challenge is to accumulate the values in) YMM8 ,其中包含乘法结果.(, which holds the result of the multiplication.)
我已经看到很多凌乱的方法来做到这一点;我个人认为它们都不适合.对于此功能,我再次转向系统地旋转结果寄存器,(I’ve seen a lot of messy approaches to doing this; I personally found none of them suitable. For this function, I once again turn to systematically rotating the result register,) YMM8 ,三次,每次64位,使用(, three times, by 64 bits each time, using the) addsd 指令来累加每个移位到位63-0的值.由于原始的M1行位于(instruction to accumulate each value that shifts into bits 63-0. Since the original M1 rows are in) YMM0 –(–) YMM3 ,并且翻转后M2列在(, and the post-flip M2 columns are in) YMM4 –(–) YMM7 ,(,) YMM8 累积完成后丢弃;它可以保持其最终状态,右移192位.(is discarded after the accumulation completes; it can be left in its final state, right-shifted by 192 bits.)
再次提醒您,没有发生内存不足的情况.完成的所有工作都是逐个注册的,这就是提高速度的来源.(Once again, keep in mind that no memory hits are taking place. Everything done is register-to-register and that’s where the speed-up comes from.)
movsd xmm9, xmm8 ; Get the full result (only care about 63 - 0)
vpermq ymm8, ymm8, 39h ; Rotate ymm8 right 64 bits
addsd xmm9, xmm8 ; Add 127 – 64
vpermq ymm8, ymm8, 39h ; Rotate ymm8 right 64 bits
addsd xmm9, xmm8 ; Add 191 – 128
vpermq ymm8, ymm8, 39h ; Rotate ymm8 right 64 bits
addsd xmm9, xmm8 ; Add 255 - 192
重复相同的过程:乘法(The same process is repeated: multiply) M1[r0] * M2[c1] .在过程开始时,累加器(. At the beginning of the process, the accumulator) YMM9 被左移64位,因此(is shifted left 64 bits so that the result of) M1[r0] * M2[c1] 可以放进位(can be placed into bits) 63-0 :(:)
vmulpd ymm8, ymm0, ymm5 ; Set M1r0 * M2c1
vpermq ymm9, ymm9, 39h ; Rotate accumulator left 64 bits
movsd xmm9, xmm8 ; Get the full result
vpermq ymm8, ymm8, 39h ; Rotate ymm0 right 32 bits
addsd xmm9, xmm8 ; Add 63 – 32
vpermq ymm8, ymm8, 39h ; Rotate ymm0 right 32 bits
addsd xmm9, xmm8 ; Add 95 – 64
vpermq ymm8, ymm8, 39h ; Rotate ymm0 right 32 bits
addsd xmm9, xmm8 ; Add 127 – 96
该过程使用以下命令系统地重复两次以上(This process systematically repeats two more times, using) M2[c2] (YMM6) 和(and) M2[c3] (YMM7) 作为被乘数.当该过程重复四次时,每次使用(as the multiplicands. When the process has repeated four times, each time using) YMM0 作为乘数,累加器(as the multiplier, the accumulator) YMM9 向右旋转了三下.最后一轮旋转将其保留为最终形式,准备存储在最终输出中:(has rotated right three times. One final rotation leaves it in final form, ready to store in the final output:)
vpermq ymm9, ymm9, 39h ; Rotate accumulator left 32 bits
vmovapd ymmword ptr M, ymm9 ; Store output row 0
对于输出行1\2和3重复此过程,乘数从(The process repeats for output rows one, two, and three, with the multiplier moving from) YMM0 至(to) YMM1 , 然后(, then) YMM2 , 然后(, then) YMM3 每行.(for each row.)
最终结果是正确地计算了输出矩阵M,而所需的时间是(The end result is the output matrix M is properly computed in a fraction of the time that would be required for) XMMatrixMultiply 执行.(to execute.)
注意(Note):对于那些希望自己进行速度比较的人,在64位Visual Studio应用程序中不允许64位汇编,并且内部函数可能会或可能不会使计时结果产生偏差(它们可能执行得更慢).此外,尽管我不能绝对证明这一点,但我的经验一直是,用Visual Studio编写的应用程序与Windows有特殊的关系,在Windows中,它们的运行速度比使用其他任何工具编写的应用程序快得多.那是我的经验;我无法在法庭上站起来证明这一点,所以我不能授权它是真的.我个人坚信.(: For those wishing to make their own speed comparisons, 64-bit assembly is not permitted in 64 bit Visual Studio apps, and intrinsics may or may not skew the timing results (they will probably execute slower). Further, while I cannot prove this absolutely, my experience has always been that apps written inside Visual Studio have a special relationship with Windows, where they run considerably faster than apps written with anything else. That’s been my experience; I could not stand up in a court of law and prove it so I cannot claim with authority that it’s true. It’s a firm belief that I personally hold.)
的完整代码清单(The complete code listings for the) PCC_XMMatrixMultiply 功能如下所示.最初的外观使它看起来像此函数有太多指令,它不可能在任何明显的时间范围内运行.但事实并非如此.这些都是极高速度,低延迟的指令,它们像油脂般的闪电一样被切掉.如前所述,唯一可以判断的是整体功能的最终性能.(function is shown below. Initial appearances make it look like this function has so many instructions, it couldn’t possibly run in any kind of appreciable time frame. But it’s not the case. These are extremely high-speed, low-latency instructions and they are cut through like greased lightning. As stated earlier, the only thing to judge by is the final performance of the function as a whole.)
align qword
PCC_XMMatrixMultiply proc
; 64-bit calling conventions have RCX > M1 and RDX > M2 on entry to this function.
;*****[Load M2 into ymm4 / ymm5 / ymm6 / ymm7]*****
vmovapd ymm4, ymmword ptr [ rdx ]
vmovapd ymm5, ymmword ptr [ rdx + 32 ]
vmovapd ymm6, ymmword ptr [ rdx + 64 ]
vmovapd ymm7, ymmword ptr [ rdx + 96 ]
;*****[Swap r0,c1 and r1,c0]*************************
vpermq ymm4, ymm4, 39h
movsd xmm9, xmm5
movsd xmm5, xmm4
movsd xmm4, xmm9
;*****[Swap r0,c2 and r2,c0]*************************
vpermq ymm4, ymm4, 39h
movsd xmm9, xmm6
movsd xmm6, xmm4
movsd xmm4, xmm9
;*****[Swap r3,c0 and r0,c3]*************************
vpermq ymm4, ymm4, 39h
movsd xmm9, xmm7
movsd xmm7, xmm4
movsd xmm4, xmm9
vpermq ymm4, ymm4, 39h
;*****[Swap r2,c1 and r1,c2]*************************
vpermq ymm5, ymm5, 04Eh
vpermq ymm6, ymm6, 039h
movsd xmm9, xmm6
movsd xmm6, xmm5
movsd xmm5, xmm9
;*****[Swap r3,c1 and r1,c3]*************************
vpermq ymm5, ymm5, 039h
vpermq ymm7, ymm7, 039h
movsd xmm9, xmm7
movsd xmm7, xmm5
movsd xmm5, xmm9
vpermq ymm5, ymm5, 039h
;*****[Swap r3,c2 and r2,c3]*************************
vpermq ymm6, ymm6, 04Eh
vpermq ymm7, ymm7, 039h
movsd xmm9, xmm7
movsd xmm7, xmm6
movsd xmm6, xmm9
vpermq ymm6, ymm6, 039h
vpermq ymm7, ymm7, 04Eh
;*****[Load M1 values]*******************************
vmovapd ymm0, ymmword ptr [ rcx ]
vmovapd ymm1, ymmword ptr [ rcx + 32 ]
vmovapd ymm2, ymmword ptr [ rcx + 64 ]
vmovapd ymm3, ymmword ptr [ rcx + 96 ]
;*****[Set Mr0c0 = M1r0 * M2c0 ]*********************
vmulpd ymm8, ymm0, ymm4
movsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
;*****[Set Mr0c1 = M1r0 * M2c1 ]*********************
vmulpd ymm8, ymm0, ymm5
vpermq ymm9, ymm9, 39h
movsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
;*****[Set Mr0c2 = M1r0 * M2c2 ]*********************
vmulpd ymm8, ymm0, ymm6
vpermq ymm9, ymm9, 39h
movsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
;*****[Set Mr0c3 = M1r0 * M2c3 ]*********************
vmulpd ymm8, ymm0, ymm7
vpermq ymm9, ymm9, 39h
movsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
;*****[Store output row 0]***************************
vpermq ymm9, ymm9, 39h
lea rdx, M
vmovapd ymmword ptr M, ymm9
;*****[Set Mr1c0 = M1r1 * M2c0 ]*********************
vmulpd ymm8, ymm1, ymm4
movsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
;*****[Set Mr1c1 = M1r1 * M2c1 ]*********************
vmulpd ymm8, ymm1, ymm5
vpermq ymm9, ymm9, 39h
movsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
;*****[Set Mr1c2 = M1r1 * M2c2 ]*********************
vmulpd ymm8, ymm1, ymm6
vpermq ymm9, ymm9, 39h
movsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39haddsd xmm9, xmm8
;*****[Set Mr1c3 = M1r1 * M2c3 ]*********************
vmulpd ymm8, ymm1, ymm7
vpermq ymm9, ymm9, 39h
movsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
;*****[Store output row 1]***************************
vpermq ymm9, ymm9, 39h
vmovapd ymmword ptr M [ 32 ], ymm9
;*****[Set Mr1c0 = M1r2 * M2c0 ]*********************
vmulpd ymm8, ymm2, ymm4
movsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
;*****[Set Mr2c1 = M1r2 * M2c1 ]*********************
vmulpd ymm8, ymm2, ymm5
vpermq ymm9, ymm9, 39h
movsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
;*****[Set Mr2c2 = M1r2 * M2c2 ]*********************
vmulpd ymm8, ymm2, ymm6
vpermq ymm9, ymm9, 39h
movsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
;*****[Set Mr2c3 = M1r2 * M2c3 ]*********************
vmulpd ymm8, ymm2, ymm7
vpermq ymm9, ymm9, 39h
movsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
;*****[Store output row 2]***************************
vpermq ymm9, ymm9, 39h
vmovapd ymmword ptr M [ 64 ], ymm9
;*****[Set Mr3c0 = M1r3 * M2c0 ]*********************
vmulpd ymm8, ymm3, ymm4
movsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
;*****[Set Mr3c1 = M1r3 * M2c1 ]*********************
vmulpd ymm8, ymm3, ymm5
vpermq ymm9, ymm9, 39h
movsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
;*****[Set Mr3c2 = M1r3 * M2c2 ]*********************
vmulpd ymm8, ymm3, ymm6
vpermq ymm9, ymm9, 39h
movsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
;*****[Set Mr3c3 = M1r3 * M2c3 ]*********************
vmulpd ymm8, ymm3, ymm7
vpermq ymm9, ymm9, 39h
movsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
vpermq ymm8, ymm8, 39h
addsd xmm9, xmm8
;*****[Store output row 3]***************************
vpermq ymm9, ymm9, 39h
vmovapd ymmword ptr M [ 96 ], ymm9
;*****[Set final return]*****************************
lea rax, M
ret
PCC_XMMatrixMultiply endp
许可
本文以及所有相关的源代码和文件均已获得The Code Project Open License (CPOL)的许可。
DirectX graphics game 新闻 翻译