[译]AI:初学者神经网络(第3部分,共3部分)
By robot-v1.0
本文链接 https://www.kyfws.com/ai/ai-neural-network-for-beginners-part-of-2-zh/
版权声明 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
- 15 分钟阅读 - 7134 个词 阅读量 0AI:初学者神经网络(第3部分,共3部分)(译文)
原文地址:https://www.codeproject.com/Articles/16732/AI-Neural-Network-for-Beginners-Part-of-2
原文作者:Sacha Barber
译文由本站 robot-v1.0 翻译
前言
AI: An introduction into neural networks (multi-layer networks / trained by Microbial GA).
AI:神经网络(多层网络/由微生物GA培训)的简介.
介绍(Introduction)
本文是我要发表的三篇文章系列的第3部分.拟议的文章内容如下:(This article is part 3 of a series of three articles that I am going to post. The proposed article content will be as follows:)
- 第1部分(Part 1) :这是Perceptron网络(单层神经网络)的简介(: This one will be an introduction into Perceptron networks (single layer neural networks))
- 第2部分(Part 2) :将涉及多层神经网络以及用于解决非线性分类问题(例如XOR逻辑门的逻辑)的反向传播训练方法.这是Perceptron无法做到的.本文将对此进行进一步说明.(: Will be about multi-layer neural networks, and the back propagation training method to solve a non-linear classification problem such as the logic of an XOR logic gate. This is something that a Perceptron can’t do. This is explained further within this article.)
- 第3部分:这一部分是关于如何使用遗传算法(GA)训练多层神经网络来解决某些逻辑问题的;如果您从未遇到过遗传算法,也许我的其他文章(Part 3: This one is about how to use a genetic algorithm (GA) to train a multi-layer neural network to solve some logic problem, ;f you have never come across genetic algorithms, perhaps my other article located) 这里(here) 可能是开始学习基础知识的好地方.(may be a good place to start to learn the basics.)
概要(Summary)
本文将展示如何使用微生物遗传算法来训练多层神经网络来解决XOR逻辑问题.(This article will show how to use a Microbial Genetic Algorithm to train a multi-layer neural network to solve the XOR logic problem.)
简要回顾(第1部分和第2部分)(A Brief Recap (From Parts 1 and 2))
在开始处理多层神经网络的这篇新文章之前,让我们再次回顾一些关键概念.如果你还没读(Before we commence with the nitty griity of this new article which deals with multi-layer neural networks, let’s just revisit a few key concepts. If you haven’t read) 第1部分(Part 1) 要么(or) 第2部分(Part 2) ,也许您应该从这里开始.(, perhaps you should start there.)
第1部分:Perceptron配置(单层网络)(Part 1: Perceptron Configuration (Single Layer Network))
输入(The inputs)**(x1,x2,x3..xm)((x1,x2,x3..xm))和连接权重(and connection weights)(w1,w2,w3..wm)((w1,w2,w3..wm))**图4中的典型值为实数,正数(+)和负数(-).如果功能有些(in figure 4 are typically real values, both positive (+) and negative (-). If the feature of some)**xi(xi)**容易引起感知器着火,重量(tends to cause the perceptron to fire, the weight)**无线(wi)**将是积极的;如果功能(will be positive; if the feature)**xi(xi)**抑制感知器,重量(inhibits the perceptron, the weight)**无线(wi)**将是负面的.(will be negative.)
感知器本身包括权重,求和处理器,激活函数以及可调整的阈值处理器(以下称为"偏置").(The perceptron itself consists of weights, the summation processor, and an activation function, and an adjustable threshold processor (called bias hereafter).)
为了方便起见,通常的做法是将偏差视为另一种输入.下图说明了修改后的配置:(For convenience, the normal practice is to treat the bias as just another input. The following diagram illustrates the revised configuration:)

偏差可以认为是感知器着火的倾向(一种特定行为方式的倾向),无论其输入如何.如果加权和> 0,或者您对数学类型有所了解,则会触发图5中所示的感知器配置网络.(The bias can be thought of as the propensity (a tendency towards a particular way of behaving) of the perceptron to fire irrespective of its inputs. The perceptron configuration network shown in Figure 5 fires if the weighted sum > 0, or if you are into math type explanations.)

第2部分:多层配置(Part 2: Multi-Layer Configuration)
解决XOR问题的多层网络看起来类似于单层网络.我们仍在处理输入/权重/输出.新功能是增加了隐藏层.(The multi-layer network that will solve the XOR problem will look similar to a single layer network. We are still dealing with inputs / weights / outputs. What is new is the addition of the hidden layer.)
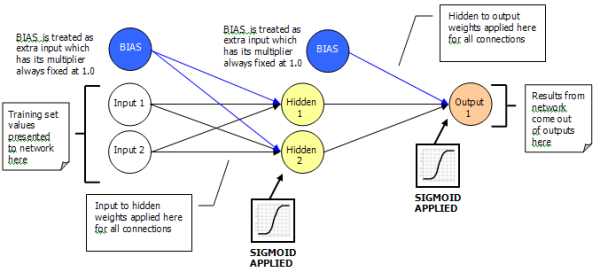
如上所述,存在一层输入层,一层隐藏层和一层输出层.(As already explained above, there is one input layer, one hidden layer, and one output layer.)
通过使用输入和权重,我们能够计算出给定节点的激活.对于隐藏层,这很容易实现,因为它直接链接到实际输入层.(It is by using the inputs and weights that we are able to work out the activation for a given node. This is easily achieved for the hidden layer as it has direct links to the actual input layer.)
但是,输出层对输入层一无所知,因为它没有直接连接到输入层.因此,要对输出节点进行激活,我们需要利用隐藏层节点的输出,这些隐藏层节点用作输出层节点的输入.(The output layer, however, knows nothing about the input layer as it is not directly connected to it. So to work out the activation for an output node, we need to make use of the output from the hidden layer nodes, which are used as inputs to the output layer nodes.)
可以将上述整个过程视为从一层到下一层的传递.(This entire process described above can be thought of as a pass forward from one layer to the next.)
这仍然像单层网络一样工作.对于任何给定节点的激活仍如下进行计算:(This still works like it did with a single layer network; the activation for any given node is still worked out as follows:)

其中wi是权重(i),而Ii是输入(i)值.您在这里看到的是相同的旧东西,没有恶魔,烟雾或魔法.这是我们已经介绍的内容.(where wi is the weight(i), and Ii is the input(i) value. You see it the same old stuff, no demons, smoke, or magic here. It’s stuff we’ve already covered.)
这就是网络的外观.现在,我想您想知道如何进行培训.(So that’s how the network looks. Now I guess you want to know how to go about training it.)
学习(Learning)
本质上,可以应用于神经网络的学习有两种类型,即"强化"和"监督".(There are essentially two types of learning that may be applied to a neural network, which are “Reinforcement” and “Supervised”.)
加强(Reinforcement)
在强化学习中,在训练期间,向神经网络提供了一组输入.目标预期为1.0时,输出为0.75.错误(1.0-0.75)用于训练(“错误0.25”).如果有两个输出怎么办?然后,将总误差求和以给出一个数字(通常是平方误差的总和).例如,“您在所有输出上的总误差为1.76”.请注意,这只是告诉您您做错了什么,而不是您讲错了什么方向.使用这种方法,我们可能永远都不会获得结果,或者可能难以捉摸.(In Reinforcement learning, during training, a set of inputs is presented to the neural network. The output is 0.75 when the target was expecting 1.0. The error (1.0 - 0.75) is used for training (“wrong by 0.25”). What if there are two outputs? Then the total error is summed to give a single number (typically sum of squared errors). E.g., “your total error on all outputs is 1.76”. Note that this just tells you how wrong you were, not in which direction you were wrong. Using this method, we may never get a result, or could be hunt the needle.)
使用通用算法训练多层神经网络可提供一种强化类型的训练方案,其中的变异负责"稍微改变权重".这就是本文的全部内容.(Using a generic algorithm to train a multi-layer neural network offers a Reinforcement type training arrangement, where the mutation is responsible for “jiggling the weights a bit”. This is what this article is all about.)
监督下(Supervised)
在监督学习中,将为神经网络提供更多信息.不仅是"错了",还是"错了什么方向"(例如"打针"),但在哪里被告知"北偏北"“西偏西”.因此,您可以在监督学习中获得并使用更多的信息,这是神经网络学习算法的正常形式.(In Supervised learning, the neural network is given more information. Not just “how wrong” it was, but “in what direction it was wrong”, like “Hunt the needle”, but where you are told “North a bit” “West a bit”. So you get, and use, far more information in Supervised learning, and this is the normal form of neural network learning algorithm.)
此训练方法通常使用反向传播训练方法进行,(This training method is normally conducted using a Back Propagation training method, which I covered in) 第2部分(Part 2) ,因此,如果这是这三个部分的第一篇文章,并且反向传播方法特别受关注,那么您应该看看那里.(, so if this is your first article of these three parts, and the back propagation method is of particular interest, then you should look there.)
所以现在新东西(So Now the New Stuff)
从这一点开始,正在讨论的任何内容都直接与本文的代码有关.(From this point on, anything that is being discussed relates directly to this article’s code.)
我们要解决的问题是什么?好吧,它和以前一样(What is the problem we are trying to solve? Well, it’s the same as it was for) 第2部分(Part 2) ,这是简单的XOR逻辑问题.实际上,本文的内容实际上只是基于本文所涵盖知识的增量构建.(, it’s the simple XOR logic problem. In fact, this articles content is really just an incremental build, on knowledge that was covered in) 第1部分(Part 1) 和(and) 第2部分(Part 2) ,让我们继续前进.(, so let’s march on.)
为了使那些可能只阅读这篇文章的人受益,XOR逻辑问题看起来像下面的真值表:(For the benefit of those that may have only read this one article, the XOR logic problem looks like the following truth table:)

请记住,对于单层(感知器),我们不能实现XOR功能,因为它不是线性可分离的.但是对于多层网络,这是可以实现的.(Remember with a single layer (perceptron), we can’t actually achieve the XOR functionality as it’s not linearly separable. But with a multi-layer network, this is achievable.)
因此,考虑到这一点,我们将如何实现这一目标?好了,我们将从现在开始使用遗传算法(GA)来繁殖大量的神经网络,这些神经网络有望发展为XOR逻辑问题提供解决方案.无论如何,这是基本思想.(So with this in mind, how are we going to achieve this? Well, we are going to use a Genetic Algorithm (GA from this point on) to breed a population of neural networks that will hopefully evolve to provide a solution to the XOR logic problem; that’s the basic idea anyway.)
那么这一切是什么样的呢?(So what does this all look like?)

从上图可以看出,我们要做的是拥有一个GA,该GA实际上将包含一组神经网络. GA的想法是,在群体中摇晃神经网络的权重,希望权重的晃动将推动神经网络群体朝着XOR问题的解决方案发展.(As can be seen from the figure above, what we are going to do is have a GA which will actually contain a population of neural networks. The idea being that the GA will jiggle the weights of the neural networks, within the population, in the hope that the jiggling of the weights will push the neural network population towards a solution to the XOR problem.)
那么这如何转化为算法(So How Does This Translate Into an Algorithm)
微生物GA培训的基本操作如下:(The basic operation of the Microbial GA training is as follows:)
-
随机选择两个基因型(Pick two genotypes at random)
-
比较得分(适合度)以得出赢家和输家(Compare scores (fitness) to come up with a winner and loser)
-
在每个基因座(点)进行基因型分析(Go along genotype, at each locus (point))所以(So)只要(only)失败者得到改变,这免费提供了Elitism版本;这确保了种群中最好的品种.(the loser gets changed, which gives a version of Elitism for free; this ensures the best in breed remains in the population.)
- 很有可能从赢家复制到输家(覆盖)(With some probability, copy from winner to loser (overwrite))
- 一定要改变失败者的轨迹(With some probability, mutate that locus of the loser)
而已.那就是完整的算法.(That’s it. That is the complete algorithm.)
但是有一些(But there are some)必要(essential)使用GA时要注意的问题:(issues to be aware of when playing with GAs:)
- 对于不同的问题域,基因型将有所不同(The genotype will be different for a different problem domain)
- 适应度函数对于不同的问题域将有所不同(The fitness function will be different for a different problem domain) 这两项(These two items)必须(must)指定新问题时,将再次进行开发.例如,如果我们想找到一个人最喜欢的比萨饼浇头,其基因型和适应性将与本文的问题域所用的不同.(be developed again whenever a new problem is specified. For example, if we wanted to find a person’s favourite pizza toppings, the genotype and fitness would be different from that which is used for this article’s problem domain.)
GA(针对本文问题域)的这两个基本要素在下面指定.(These two essential elements of a GA (for this article problem domain) are specified below.)
1.基因型(1. The Geneotype)
对于本文,问题域指出我们拥有大量的神经网络.所以我创建了一个单维数组(For this article, the problem domain states that we had a population of neural networks. So I created a single dimension array of) NeuralNetwork 对象.这可以从(objects. This can be seen from the constructor code within the) GA_Trainer_XOR 目的:(object:)
//ANN's
private NeuralNetwork[] networks;
public GA_Trainer_XOR()
{
networks = new NeuralNetwork[POPULATION];
//create new ANN objects, random weights applied at start
for (int i = 0; i <= networks.GetUpperBound(0); i++)
{
networks[i] = new NeuralNetwork(2, 2, 1);
networks[i].Change +=
new NeuralNetwork.ChangeHandler(GA_Trainer_NN_Change);
}
}
2.健身功能(2. The Fitness Function)
记住指出的问题域描述,下面的真值表是我们要实现的目标:(Remembering the problem domain description stated, the following truth table is what we are trying to achieve:)
那么,如何确定神经网络对此的适应性(接近程度)呢?确实很简单.我们所做的是一次显示神经网络的全部输入,并保持累积的误差值,其计算如下:(So how can we tell how fit (how close) the neural network is to this ? It is fairly simply really. What we do is present the entire set of inputs to the Neural Network one at a time and keep an accumulated error value, which is worked out as follows:)
内(Within the) NeuralNetwork 上课,有一个(class, there is a) getError(..) 像这样的方法:(method like this:)
public double getError(double[] targets)
{
//storage for error
double error = 0.0;
//this calculation is based on something I read about weight space in
//Artificial Intellegence - A Modern Approach, 2nd edition.Prentice Hall
//2003. Stuart Rusell, Peter Norvig. Pg 741
error = Math.Sqrt(Math.Pow((targets[0] - outputs[0]), 2));
return error;
}
然后在(Then in the) NN_Trainer_XOR 上课,有一个(class, there is an) Evaluate 接受(method that accepts an) int 代表要获取和评估(适合)的总体成员的值.然后将总体适应度返回到GA训练方法,以查看哪个神经网络应该是赢家,哪个神经网络应该是输家.(value which represents the member of the population to fetch and evaluate (get fitness for). This overall fitness is then returned to the GA training method to see which neural network should be the winner and which neural network should be the loser.)
private double evaluate(int popMember)
{
double error = 0.0;
//loop through the entire training set
for (int i = 0; i <= train_set.GetUpperBound(0); i++)
{
//forward these new values through network
//forward weights through ANN
forwardWeights(popMember, getTrainSet(i));
double[] targetValues = getTargetValues(getTrainSet(i));
error += networks[popMember].getError(targetValues);
}
//if the Error term is < acceptableNNError value we have found
//a good configuration of weights for teh NeuralNetwork, so tell
//GA to stop looking
if (error < acceptableNNError)
{
bestConfiguration = popMember;
foundGoodANN = true;
}
//return error
return error;
}
那么,当我们拥有训练有素的神经网络时,我们怎么知道呢?在本文的代码中,我所做的是在(So how do we know when we have a trained neural network? In this article’s code, what I have done is provide a fixed limit value within the) NN_Trainer_XOR 当达到该级别时,表明训练已产生最佳配置的神经网络.(class that, when reached, indicates that the training has yielded a best configured neural network.)
但是,如果整个训练循环都完成了,但仍然没有配置良好的神经网络,我只是将(最后训练时期的)获胜者的值作为总体配置最佳的神经网络返回.(If, however, the entire training loop is done and there is still no well-configured neural network, I simply return the value of the winner (of the last training epoch) as the overall best configured neural network.)
这显示在下面的代码片段中;这应该与(This is shown in the code snippet below; this should be read in conjunction with the) evaluate(..) 上面显示的方法:(method shown above:)
//check to see if there was a best configuration found, may not have done
//enough training to find a good NeuralNetwork configuration, so will simply
//have to return the WINNER
if (bestConfiguration == -1)
{
bestConfiguration = WINNER;
}
//return the best Neural network
return networks[bestConfiguration];
所以最后的代码(So Finally the Code)
好吧,本文的代码看起来像下面的类图(它是Visual Studio 2005,C#. NET v2.0):(Well, the code for this article looks like the following class diagram (it’s Visual Studio 2005, C#, .NET v2.0):)
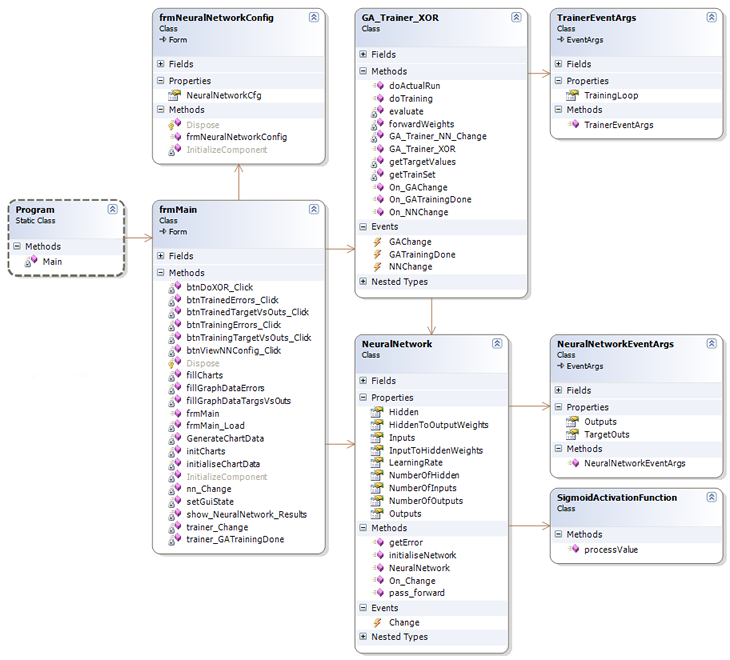
人们应该花时间看的主要课程是:(The main classes that people should take the time to look at would be:)
GA_Trainer_XOR:训练神经网络使用微生物GA解决XOR问题.(: Trains a neural network to solve the XOR problem using a Microbial GA.)TrainerEventArgs:培训事件args,与GUI一起使用.(: Training event args, for use with a GUI.)NeuralNetwork:可配置的神经网络.(: A configurable neural network.)NeuralNetworkEventArgs:培训事件args,与GUI一起使用.(: Training event args, for use with a GUI.)SigmoidActivationFunction:提供S型激活功能的静态方法.(: A static method to provide the sigmoid activation function.) 剩下的就是我构建的GUI,只是为了展示它们如何组合在一起.(The rest are the GUI I constructed simply to show how it all fits together.)
注意(Note):演示项目包含所有代码,因此在此不再列出.另请注意,大多数此类与(: The demo project contains all code, so I won’t list it here. Also note that most of these classes are quite similar to those included with the) 第2部分(Part 2) 文章代码.我想保持代码相似,以便已经看过的人(article code. I wanted to keep the code similar so people who have already looked at) 第2部分(Part 2) 会认识到常见的模式.(would recognize the common pattern.)
代码演示(Code Demos)
随附的演示应用程序具有三个主要区域,如下所述:(The demo application attached has three main areas which are described below:)
实时结果标签(Live Results Tab)
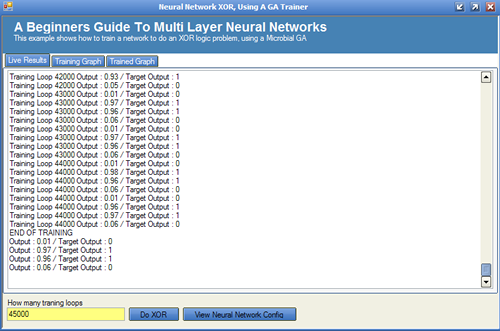
可以看出,这几乎解决了XOR问题.然而,它确实花费了训练循环近45000次迭代(纪元).请记住,我们还必须将整个训练集呈现给网络,并且还要进行两次,一次是寻找赢家,一次是寻找失败者.这项工作很多.我相信你们都会同意.这就是为什么神经网络通常不由GA训练的原因;本文实际上是关于如何将GA应用于问题域的.因为GA培训花费了45000个纪元才能产生可接受的结果,但这并不意味着GA毫无用处. GA远非如此,可以用于许多问题,例如:(It can be seen that this has very nearly solved the XOR problem; it did however take nearly 45000 iterations (epoch) of a training loop. Remembering that we have to also present the entire training set to the network, and also do this twice, once to find a winner and once to find a loser. That is quite a lot of work; I am sure you would all agree. This is why neural networks are not normally trained by GAs; this article is really about how to apply a GA to a problem domain. Because the GA training took 45000 epochs to yield an acceptable result does not mean that GAs are useless. Far from it, GAs have their place, and can be used for many problems, such as:)
- 数独解算器(流行游戏)(Sudoko solver (the popular game))
- 背包问题(尝试优化使用有限尺寸的背包,以容纳尽可能多的物品)(Backpack problem (trying to optimize the use of a backpack of limited size, to get as many items in as will fit))
- 最喜欢的比萨饼浇头问题(尝试找出某人最喜欢的比萨饼是什么)(Favourite pizza toppings problem (try and find out what someone’s favourite pizza is)) 仅举几个例子,基本上,如果您可以提出基因型和适应性函数,则应该能够获得GA来制定解决方案. GA也已用于增长语法的整个语法树,以便预测哪种语法更理想.在我撰写本文时,在这一领域还有更多的研究要做.实际上,关于这个主题有一篇不错的文章((To name but a few, basically, if you can come up with the genotype and a Fitness function, you should be able to get a GA to work out a solution. GAs have also been used to grow entire syntax trees of grammar, in order to predict which grammar is more optimal. There is more research being done in this area as I write this article; in fact, there is a nice article on this topic () 基因表达程序设计(Gene Expression Programming) ),如果有人想进一步阅读的话,可以在CodeProject上找到Andrew Krillov.() by Andrew Krillov, right here at the CodeProject, if anyone wants to read further.)
训练结果标签(Training Results Tab)
一起查看目标/输出:(Viewing the target/outputs together:)

查看错误:(Viewing the errors:)

训练结果选项卡(Trained Results Tab)
一起查看目标/输出:(Viewing the target/outputs together:)

也可以使用"查看神经网络配置"按钮查看神经网络的最终配置.(It is also possible to view the neural network’s final configuration using the “View Neural Network Config” button.)

你怎么看?(What Do You Think?)
这就对了;我想问一下,如果您喜欢这篇文章,请投赞成票.(That is it; I would just like to ask, if you liked the article, please vote for it.)
兴趣点(Points of Interest)
我认为AI相当有趣,这就是为什么我要花时间发布这些文章的原因.因此,我希望其他人会发现它有趣,并且因为它具有我自己的知识,因此可能会有助于进一步增进人们的知识.(I think AI is fairly interesting, that’s why I am taking the time to publish these articles. So I hope someone else finds it interesting, and that it might help further someone’s knowledge, as it has my own.)
任何想进一步研究AI类型的东西,发现本文内容有点基础的人,都应该在以下位置查看Andrew Krillov的文章(Anyone that wants to look further into AI type stuff, that finds the content of this article a bit basic, should check out Andrew Krillov’s articles at) Andrew Krillov CP文章(Andrew Krillov CP articles) 因为他比较先进,也很好.(as his are more advanced, and very good.)
历史(History)
- v1.1:27/12/06:修改了(v1.1: 27/12/06: Modified the)
GA_Trainer_XOR类具有5的随机数种子.(class to have a random number seed of 5.) - v1.0:06年11月12日:初始文章.(v1.0: 11/12/06: Initial article.)
参考书目(Bibliography)
- 人工智能第二版,伊莱恩
里奇/凯文奈特.麦格劳`希尔公司(Artificial Intelligence 2nd edition, Elaine Rich / Kevin Knight. McGraw Hill Inc.) - 人工智能,一种现代方法,Stuart Russell/Peter Norvig.学徒大厅.(Artificial Intelligence, A Modern Approach, Stuart Russell / Peter Norvig. Prentice Hall.)
许可
本文以及所有相关的源代码和文件均已获得The Code Project Open License (CPOL)的许可。
C# .NET Windows Visual-Studio VS2005 Dev AI 新闻 翻译